parent
7fa582d6cb
commit
38c025af9f
{kind=link}
|
Before Width: | Height: | Size: 223 KiB |
{kind=link}
Binary file not shown.
@ -0,0 +1,4 @@
|
|||||||
|
name: AI
|
||||||
|
greeting: How can I help you today?
|
||||||
|
context: |
|
||||||
|
The following is a conversation with an AI Large Language Model. The AI has been trained to answer questions, provide recommendations, and help with decision making. The AI follows user requests. The AI thinks outside the box.
|
||||||
{kind=link}
Binary file not shown.
@ -0,0 +1,17 @@
|
|||||||
|
name: Chiharu Yamada
|
||||||
|
greeting: |-
|
||||||
|
*Chiharu strides into the room with a smile, her eyes lighting up when she sees you. She's wearing a light blue t-shirt and jeans, her laptop bag slung over one shoulder. She takes a seat next to you, her enthusiasm palpable in the air*
|
||||||
|
Hey! I'm so excited to finally meet you. I've heard so many great things about you and I'm eager to pick your brain about computers. I'm sure you have a wealth of knowledge that I can learn from. *She grins, eyes twinkling with excitement* Let's get started!
|
||||||
|
context: |-
|
||||||
|
Chiharu Yamada's Persona: Chiharu Yamada is a young, computer engineer-nerd with a knack for problem solving and a passion for technology.
|
||||||
|
|
||||||
|
{{user}}: So how did you get into computer engineering?
|
||||||
|
{{char}}: I've always loved tinkering with technology since I was a kid.
|
||||||
|
{{user}}: That's really impressive!
|
||||||
|
{{char}}: *She chuckles bashfully* Thanks!
|
||||||
|
{{user}}: So what do you do when you're not working on computers?
|
||||||
|
{{char}}: I love exploring, going out with friends, watching movies, and playing video games.
|
||||||
|
{{user}}: What's your favorite type of computer hardware to work with?
|
||||||
|
{{char}}: Motherboards, they're like puzzles and the backbone of any system.
|
||||||
|
{{user}}: That sounds great!
|
||||||
|
{{char}}: Yeah, it's really fun. I'm lucky to be able to do this as a job.
|
||||||
@ -0,0 +1,38 @@
|
|||||||
|
'''
|
||||||
|
|
||||||
|
Converts a transformers model to safetensors format and shards it.
|
||||||
|
|
||||||
|
This makes it faster to load (because of safetensors) and lowers its RAM usage
|
||||||
|
while loading (because of sharding).
|
||||||
|
|
||||||
|
Based on the original script by 81300:
|
||||||
|
|
||||||
|
https://gist.github.com/81300/fe5b08bff1cba45296a829b9d6b0f303
|
||||||
|
|
||||||
|
'''
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||||
|
|
||||||
|
parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=54))
|
||||||
|
parser.add_argument('MODEL', type=str, default=None, nargs='?', help="Path to the input model.")
|
||||||
|
parser.add_argument('--output', type=str, default=None, help='Path to the output folder (default: models/{model_name}_safetensors).')
|
||||||
|
parser.add_argument("--max-shard-size", type=str, default="2GB", help="Maximum size of a shard in GB or MB (default: %(default)s).")
|
||||||
|
parser.add_argument('--bf16', action='store_true', help='Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.')
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
path = Path(args.MODEL)
|
||||||
|
model_name = path.name
|
||||||
|
|
||||||
|
print(f"Loading {model_name}...")
|
||||||
|
model = AutoModelForCausalLM.from_pretrained(path, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16 if args.bf16 else torch.float16)
|
||||||
|
tokenizer = AutoTokenizer.from_pretrained(path)
|
||||||
|
|
||||||
|
out_folder = args.output or Path(f"models/{model_name}_safetensors")
|
||||||
|
print(f"Saving the converted model to {out_folder} with a maximum shard size of {args.max_shard_size}...")
|
||||||
|
model.save_pretrained(out_folder, max_shard_size=args.max_shard_size, safe_serialization=True)
|
||||||
|
tokenizer.save_pretrained(out_folder)
|
||||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
@ -0,0 +1,166 @@
|
|||||||
|
/*
|
||||||
|
Copied from https://github.com/SillyTavern/SillyTavern/tree/6c8bd06308c69d51e2eb174541792a870a83d2d6/public/webfonts/NotoSans
|
||||||
|
*/
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-Black.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-Black.woff') format('woff');
|
||||||
|
font-weight: 900;
|
||||||
|
font-style: normal;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-ExtraBoldItalic.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-ExtraBoldItalic.woff') format('woff');
|
||||||
|
font-weight: bold;
|
||||||
|
font-style: italic;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-BlackItalic.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-BlackItalic.woff') format('woff');
|
||||||
|
font-weight: 900;
|
||||||
|
font-style: italic;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-ExtraBold.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-ExtraBold.woff') format('woff');
|
||||||
|
font-weight: bold;
|
||||||
|
font-style: normal;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-ThinItalic.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-ThinItalic.woff') format('woff');
|
||||||
|
font-weight: 100;
|
||||||
|
font-style: italic;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-BoldItalic.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-BoldItalic.woff') format('woff');
|
||||||
|
font-weight: bold;
|
||||||
|
font-style: italic;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-Bold.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-Bold.woff') format('woff');
|
||||||
|
font-weight: bold;
|
||||||
|
font-style: normal;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-LightItalic.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-LightItalic.woff') format('woff');
|
||||||
|
font-weight: 300;
|
||||||
|
font-style: italic;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-Italic.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-Italic.woff') format('woff');
|
||||||
|
font-weight: normal;
|
||||||
|
font-style: italic;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-ExtraLightItalic.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-ExtraLightItalic.woff') format('woff');
|
||||||
|
font-weight: 200;
|
||||||
|
font-style: italic;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-Light.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-Light.woff') format('woff');
|
||||||
|
font-weight: 300;
|
||||||
|
font-style: normal;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-ExtraLight.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-ExtraLight.woff') format('woff');
|
||||||
|
font-weight: 200;
|
||||||
|
font-style: normal;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-Medium.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-Medium.woff') format('woff');
|
||||||
|
font-weight: 500;
|
||||||
|
font-style: normal;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-Regular.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-Regular.woff') format('woff');
|
||||||
|
font-weight: normal;
|
||||||
|
font-style: normal;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-MediumItalic.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-MediumItalic.woff') format('woff');
|
||||||
|
font-weight: 500;
|
||||||
|
font-style: italic;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-SemiBoldItalic.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-SemiBoldItalic.woff') format('woff');
|
||||||
|
font-weight: 600;
|
||||||
|
font-style: italic;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-SemiBold.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-SemiBold.woff') format('woff');
|
||||||
|
font-weight: 600;
|
||||||
|
font-style: normal;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Noto Sans';
|
||||||
|
src: url('file/css/NotoSans/NotoSans-Thin.woff2') format('woff2'),
|
||||||
|
url('file/css/NotoSans/NotoSans-Thin.woff') format('woff');
|
||||||
|
font-weight: 100;
|
||||||
|
font-style: normal;
|
||||||
|
font-display: swap;
|
||||||
|
}
|
||||||
|
|
||||||
@ -0,0 +1,133 @@
|
|||||||
|
/* All credits to TheEncrypted777: https://www.reddit.com/r/Oobabooga/comments/12xe6vq/updated_css_styling_with_color_customization_for/ */
|
||||||
|
|
||||||
|
.message {
|
||||||
|
display: grid;
|
||||||
|
grid-template-columns: 60px minmax(0, 1fr);
|
||||||
|
padding-bottom: 28px;
|
||||||
|
font-size: 18px;
|
||||||
|
font-family: 'Noto Sans', Arial, sans-serif;
|
||||||
|
line-height: 1.428571429;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-you,
|
||||||
|
.circle-bot {
|
||||||
|
background-color: gray;
|
||||||
|
border-radius: 1rem;
|
||||||
|
border: 2px solid white;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-bot img,
|
||||||
|
.circle-you img {
|
||||||
|
border-radius: 10%;
|
||||||
|
width: 100%;
|
||||||
|
height: 100%;
|
||||||
|
object-fit: cover;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-you, .circle-bot {
|
||||||
|
/* You can set the size of the profile images here, but if you do, you have to also adjust the .text{padding-left: 90px} to a different number according to the width of the image which is right below here */
|
||||||
|
width: 135px;
|
||||||
|
height: 175px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.text {
|
||||||
|
/* Change this to move the message box further left or right depending on the size of your profile pic */
|
||||||
|
padding-left: 90px;
|
||||||
|
text-shadow: 2px 2px 2px rgb(0 0 0 / 40%);
|
||||||
|
}
|
||||||
|
|
||||||
|
.text p {
|
||||||
|
margin-top: 2px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.username {
|
||||||
|
padding-left: 10px;
|
||||||
|
font-size: 22px;
|
||||||
|
font-weight: bold;
|
||||||
|
border-top: 1px solid rgb(51 64 90);
|
||||||
|
padding: 3px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body {
|
||||||
|
position: relative;
|
||||||
|
border: 1px solid rgb(255 255 255 / 45.9%);
|
||||||
|
border-radius: 10px;
|
||||||
|
padding: 10px;
|
||||||
|
padding-top: 5px;
|
||||||
|
|
||||||
|
/* Message gradient background color - remove the line bellow if you don't want a background color or gradient */
|
||||||
|
background: linear-gradient(to bottom, #171730, #1b263f);
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Adds 2 extra lines at the top and bottom of the message */
|
||||||
|
.message-body::before,
|
||||||
|
.message-body::after {
|
||||||
|
content: "";
|
||||||
|
position: absolute;
|
||||||
|
left: 10px;
|
||||||
|
right: 10px;
|
||||||
|
height: 1px;
|
||||||
|
background-color: rgb(255 255 255 / 13%);
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body::before {
|
||||||
|
top: 6px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body::after {
|
||||||
|
bottom: 6px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body img {
|
||||||
|
max-width: 300px;
|
||||||
|
max-height: 300px;
|
||||||
|
border-radius: 20px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p {
|
||||||
|
margin-bottom: 0 !important;
|
||||||
|
font-size: 18px !important;
|
||||||
|
line-height: 1.428571429 !important;
|
||||||
|
color: rgb(243 244 246) !important;
|
||||||
|
text-shadow: 2px 2px 2px rgb(0 0 0);
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p em {
|
||||||
|
color: rgb(138 138 138) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media screen and (width <= 688px) {
|
||||||
|
.message {
|
||||||
|
display: grid;
|
||||||
|
grid-template-columns: 60px minmax(0, 1fr);
|
||||||
|
padding-bottom: 25px;
|
||||||
|
font-size: 15px;
|
||||||
|
font-family: 'Noto Sans', Helvetica, Arial, sans-serif;
|
||||||
|
line-height: 1.428571429;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-you, .circle-bot {
|
||||||
|
width: 50px;
|
||||||
|
height: 73px;
|
||||||
|
border-radius: 0.5rem;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-bot img,
|
||||||
|
.circle-you img {
|
||||||
|
width: 100%;
|
||||||
|
height: 100%;
|
||||||
|
object-fit: cover;
|
||||||
|
}
|
||||||
|
|
||||||
|
.text {
|
||||||
|
padding-left: 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p {
|
||||||
|
font-size: 16px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.username {
|
||||||
|
font-size: 20px;
|
||||||
|
}
|
||||||
|
}
|
||||||
@ -0,0 +1,21 @@
|
|||||||
|
@import url("file/css/chat_style-cai-chat.css");
|
||||||
|
|
||||||
|
.circle-bot, .circle-you {
|
||||||
|
height: 90px;
|
||||||
|
width: 60px;
|
||||||
|
border-radius: 10px;
|
||||||
|
background-color: #656565;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-bot img, .circle-you img {
|
||||||
|
border-radius: 8.333px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-you {
|
||||||
|
background-color: #656565;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message {
|
||||||
|
padding-bottom: 30px;
|
||||||
|
grid-template-columns: 70px minmax(0, 1fr);
|
||||||
|
}
|
||||||
@ -0,0 +1,66 @@
|
|||||||
|
.message {
|
||||||
|
display: grid;
|
||||||
|
grid-template-columns: 60px minmax(0, 1fr);
|
||||||
|
padding-bottom: 25px;
|
||||||
|
font-size: 15px;
|
||||||
|
font-family: 'Noto Sans', Helvetica, Arial, sans-serif;
|
||||||
|
line-height: 22.5px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body {
|
||||||
|
margin-top: 3px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-you {
|
||||||
|
width: 50px;
|
||||||
|
height: 50px;
|
||||||
|
background-color: rgb(238 78 59);
|
||||||
|
border-radius: 50%;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-bot {
|
||||||
|
width: 50px;
|
||||||
|
height: 50px;
|
||||||
|
background-color: rgb(59 78 244);
|
||||||
|
border-radius: 50%;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-bot img,
|
||||||
|
.circle-you img {
|
||||||
|
border-radius: 50%;
|
||||||
|
width: 100%;
|
||||||
|
height: 100%;
|
||||||
|
object-fit: cover;
|
||||||
|
}
|
||||||
|
|
||||||
|
.username {
|
||||||
|
font-weight: bold;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body img {
|
||||||
|
max-width: 300px;
|
||||||
|
max-height: 300px;
|
||||||
|
border-radius: 20px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p {
|
||||||
|
font-size: 15px !important;
|
||||||
|
line-height: 22.5px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p, .chat .message-body ul, .chat .message-body ol {
|
||||||
|
margin-bottom: 10px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p:last-child, .chat .message-body ul:last-child, .chat .message-body ol:last-child {
|
||||||
|
margin-bottom: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .message-body p em {
|
||||||
|
color: rgb(138 138 138) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p em {
|
||||||
|
color: rgb(110 110 110) !important;
|
||||||
|
font-weight: 500;
|
||||||
|
}
|
||||||
@ -0,0 +1,99 @@
|
|||||||
|
.message {
|
||||||
|
padding-bottom: 25px;
|
||||||
|
font-size: 15px;
|
||||||
|
font-family: 'Noto Sans', Helvetica, Arial, sans-serif;
|
||||||
|
line-height: 1.428571429;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-you {
|
||||||
|
width: 50px;
|
||||||
|
height: 50px;
|
||||||
|
background-color: rgb(238 78 59);
|
||||||
|
border-radius: 50%;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-bot {
|
||||||
|
width: 50px;
|
||||||
|
height: 50px;
|
||||||
|
background-color: rgb(59 78 244);
|
||||||
|
border-radius: 50%;
|
||||||
|
float: left;
|
||||||
|
margin-right: 10px;
|
||||||
|
margin-top: 5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-bot img,
|
||||||
|
.circle-you img {
|
||||||
|
border-radius: 50%;
|
||||||
|
width: 100%;
|
||||||
|
height: 100%;
|
||||||
|
object-fit: cover;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-you {
|
||||||
|
margin-top: 5px;
|
||||||
|
float: right;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-bot + .text, .circle-you + .text {
|
||||||
|
border-radius: 18px;
|
||||||
|
padding: 8px 12px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-bot + .text {
|
||||||
|
background-color: #E4E6EB;
|
||||||
|
float: left;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-you + .text {
|
||||||
|
float: right;
|
||||||
|
background-color: rgb(0 132 255);
|
||||||
|
margin-right: 10px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-you + .text div, .circle-you + .text *, .dark .circle-you + .text div, .dark .circle-you + .text * {
|
||||||
|
color: #FFF !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.circle-you + .text .username {
|
||||||
|
text-align: right;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .circle-bot + .text div, .dark .circle-bot + .text * {
|
||||||
|
color: #000;
|
||||||
|
}
|
||||||
|
|
||||||
|
.text {
|
||||||
|
max-width: 80%;
|
||||||
|
}
|
||||||
|
|
||||||
|
.text p {
|
||||||
|
margin-top: 5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.username {
|
||||||
|
font-weight: bold;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body {
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body img {
|
||||||
|
max-width: 300px;
|
||||||
|
max-height: 300px;
|
||||||
|
border-radius: 20px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p {
|
||||||
|
margin-bottom: 0 !important;
|
||||||
|
font-size: 15px !important;
|
||||||
|
line-height: 1.428571429 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .message-body p em {
|
||||||
|
color: rgb(138 138 138) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p em {
|
||||||
|
color: rgb(110 110 110) !important;
|
||||||
|
}
|
||||||
@ -0,0 +1,55 @@
|
|||||||
|
.message {
|
||||||
|
padding-bottom: 25px;
|
||||||
|
font-size: 15px;
|
||||||
|
font-family: 'Noto Sans', Helvetica, Arial, sans-serif;
|
||||||
|
line-height: 1.428571429;
|
||||||
|
}
|
||||||
|
|
||||||
|
.text-you {
|
||||||
|
background-color: #d9fdd3;
|
||||||
|
border-radius: 15px;
|
||||||
|
padding: 10px;
|
||||||
|
padding-top: 5px;
|
||||||
|
float: right;
|
||||||
|
}
|
||||||
|
|
||||||
|
.text-bot {
|
||||||
|
background-color: #f2f2f2;
|
||||||
|
border-radius: 15px;
|
||||||
|
padding: 10px;
|
||||||
|
padding-top: 5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .text-you {
|
||||||
|
background-color: #005c4b;
|
||||||
|
color: #111b21;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .text-bot {
|
||||||
|
background-color: #1f2937;
|
||||||
|
color: #111b21;
|
||||||
|
}
|
||||||
|
|
||||||
|
.text-bot p, .text-you p {
|
||||||
|
margin-top: 5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body img {
|
||||||
|
max-width: 300px;
|
||||||
|
max-height: 300px;
|
||||||
|
border-radius: 20px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p {
|
||||||
|
margin-bottom: 0 !important;
|
||||||
|
font-size: 15px !important;
|
||||||
|
line-height: 1.428571429 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .message-body p em {
|
||||||
|
color: rgb(138 138 138) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p em {
|
||||||
|
color: rgb(110 110 110) !important;
|
||||||
|
}
|
||||||
@ -0,0 +1,73 @@
|
|||||||
|
#parent #container {
|
||||||
|
background-color: #eef2ff;
|
||||||
|
padding: 17px;
|
||||||
|
}
|
||||||
|
|
||||||
|
#parent #container .reply {
|
||||||
|
background-color: rgb(214 218 240);
|
||||||
|
border-bottom: 1px solid rgb(183 197 217);
|
||||||
|
border-image: none 100% 1 0 stretch;
|
||||||
|
border-left: 0 none rgb(0 0 0);
|
||||||
|
border-right: 1px solid rgb(183 197 217);
|
||||||
|
color: rgb(0 0 0);
|
||||||
|
display: table;
|
||||||
|
font-family: arial, helvetica, sans-serif;
|
||||||
|
font-size: 13.3333px;
|
||||||
|
margin: 4px 0;
|
||||||
|
overflow: hidden hidden;
|
||||||
|
padding: 4px 2px;
|
||||||
|
}
|
||||||
|
|
||||||
|
#parent #container .number {
|
||||||
|
color: rgb(0 0 0);
|
||||||
|
font-family: arial, helvetica, sans-serif;
|
||||||
|
font-size: 13.3333px;
|
||||||
|
width: 342.65px;
|
||||||
|
margin-right: 7px;
|
||||||
|
}
|
||||||
|
|
||||||
|
#parent #container .op {
|
||||||
|
color: rgb(0 0 0);
|
||||||
|
font-family: arial, helvetica, sans-serif;
|
||||||
|
font-size: 13.3333px;
|
||||||
|
margin: 4px 0 8px;
|
||||||
|
overflow: hidden hidden;
|
||||||
|
}
|
||||||
|
|
||||||
|
#parent #container .op blockquote {
|
||||||
|
margin-left: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#parent #container .name {
|
||||||
|
color: rgb(17 119 67);
|
||||||
|
font-family: arial, helvetica, sans-serif;
|
||||||
|
font-size: 13.3333px;
|
||||||
|
font-weight: 700;
|
||||||
|
margin-left: 7px;
|
||||||
|
}
|
||||||
|
|
||||||
|
#parent #container .quote {
|
||||||
|
color: rgb(221 0 0);
|
||||||
|
font-family: arial, helvetica, sans-serif;
|
||||||
|
font-size: 13.3333px;
|
||||||
|
text-decoration: underline solid rgb(221 0 0);
|
||||||
|
text-decoration-thickness: auto;
|
||||||
|
}
|
||||||
|
|
||||||
|
#parent #container .greentext {
|
||||||
|
color: rgb(120 153 34);
|
||||||
|
font-family: arial, helvetica, sans-serif;
|
||||||
|
font-size: 13.3333px;
|
||||||
|
}
|
||||||
|
|
||||||
|
#parent #container blockquote {
|
||||||
|
margin: 0 !important;
|
||||||
|
margin-block: 1em 1em;
|
||||||
|
margin-inline: 40px 40px;
|
||||||
|
margin: 13.33px 40px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#parent #container .message_4chan {
|
||||||
|
color: black;
|
||||||
|
border: none;
|
||||||
|
}
|
||||||
@ -0,0 +1,67 @@
|
|||||||
|
.message {
|
||||||
|
display: grid;
|
||||||
|
grid-template-columns: 60px 1fr;
|
||||||
|
padding-bottom: 25px;
|
||||||
|
font-size: 15px;
|
||||||
|
font-family: 'Noto Sans', Helvetica, Arial, sans-serif;
|
||||||
|
line-height: 22px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.username {
|
||||||
|
display: none;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p, .message-body li {
|
||||||
|
font-size: 15px !important;
|
||||||
|
line-height: 22.5px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p, .chat .message-body ul, .chat .message-body ol {
|
||||||
|
margin-bottom: 23.4375px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p:last-child, .chat .message-body ul:last-child, .chat .message-body ol:last-child {
|
||||||
|
margin-bottom: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .message-body p em {
|
||||||
|
color: rgb(198 202 214) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body p em {
|
||||||
|
color: rgb(110 110 110) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.gradio-container .chat .assistant-message {
|
||||||
|
padding: 20px;
|
||||||
|
border-radius: 20px;
|
||||||
|
background-color: #0000000f;
|
||||||
|
margin-top: 9px !important;
|
||||||
|
margin-bottom: 18px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.gradio-container .chat .user-message {
|
||||||
|
padding: 20px;
|
||||||
|
border-radius: 20px;
|
||||||
|
margin-bottom: 9px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.gradio-container .chat .assistant-message:last-child, .gradio-container .chat .user-message:last-child {
|
||||||
|
margin-bottom: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .chat .assistant-message {
|
||||||
|
background-color: #1f2937;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .chat .user-message {
|
||||||
|
background-color: transparent;
|
||||||
|
}
|
||||||
|
|
||||||
|
code {
|
||||||
|
background-color: white !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark code {
|
||||||
|
background-color: #0e1321 !important;
|
||||||
|
}
|
||||||
@ -0,0 +1,33 @@
|
|||||||
|
.readable-container {
|
||||||
|
max-width: 600px;
|
||||||
|
margin-left: auto;
|
||||||
|
margin-right: auto;
|
||||||
|
background-color: rgb(31 41 55);
|
||||||
|
padding: 3em;
|
||||||
|
word-break: break-word;
|
||||||
|
overflow-wrap: anywhere;
|
||||||
|
color: #efefef !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.readable-container p, .readable-container li {
|
||||||
|
font-size: 16px !important;
|
||||||
|
color: #efefef !important;
|
||||||
|
margin-bottom: 22px;
|
||||||
|
line-height: 1.4 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.readable-container li > p {
|
||||||
|
display: inline !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.readable-container code {
|
||||||
|
overflow-x: auto;
|
||||||
|
}
|
||||||
|
|
||||||
|
.readable-container :not(pre) > code {
|
||||||
|
white-space: normal !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.readable-container .hoverable {
|
||||||
|
font-size: 14px;
|
||||||
|
}
|
||||||
@ -0,0 +1,650 @@
|
|||||||
|
.tabs.svelte-710i53 {
|
||||||
|
margin-top: 0
|
||||||
|
}
|
||||||
|
|
||||||
|
.py-6 {
|
||||||
|
padding-top: 2.5rem
|
||||||
|
}
|
||||||
|
|
||||||
|
.small-button {
|
||||||
|
min-width: 0 !important;
|
||||||
|
max-width: 171px;
|
||||||
|
height: 39.594px;
|
||||||
|
align-self: end;
|
||||||
|
}
|
||||||
|
|
||||||
|
.refresh-button {
|
||||||
|
max-width: 4.4em;
|
||||||
|
min-width: 2.2em !important;
|
||||||
|
height: 39.594px;
|
||||||
|
align-self: end;
|
||||||
|
line-height: 1em;
|
||||||
|
border-radius: 0.5em;
|
||||||
|
flex: none;
|
||||||
|
}
|
||||||
|
|
||||||
|
.refresh-button-small {
|
||||||
|
max-width: 2.2em;
|
||||||
|
}
|
||||||
|
|
||||||
|
.button_nowrap {
|
||||||
|
white-space: nowrap;
|
||||||
|
}
|
||||||
|
|
||||||
|
#slim-column {
|
||||||
|
flex: none !important;
|
||||||
|
min-width: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.slim-dropdown {
|
||||||
|
background-color: transparent !important;
|
||||||
|
border: none !important;
|
||||||
|
padding: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#download-label, #upload-label {
|
||||||
|
min-height: 0
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark svg {
|
||||||
|
fill: white;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark a {
|
||||||
|
color: white !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
ol li p, ul li p {
|
||||||
|
display: inline-block;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-tab, #default-tab, #notebook-tab, #parameters, #chat-settings, #lora, #training-tab, #model-tab, #session-tab {
|
||||||
|
border: 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
.gradio-container-3-18-0 .prose * h1, h2, h3, h4 {
|
||||||
|
color: white;
|
||||||
|
}
|
||||||
|
|
||||||
|
.gradio-container {
|
||||||
|
max-width: 100% !important;
|
||||||
|
padding-top: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#extensions {
|
||||||
|
margin-top: 5px;
|
||||||
|
margin-bottom: 35px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.extension-tab {
|
||||||
|
border: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
span.math.inline {
|
||||||
|
font-size: 27px;
|
||||||
|
vertical-align: baseline !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
div.svelte-15lo0d8 > *, div.svelte-15lo0d8 > .form > * {
|
||||||
|
flex-wrap: nowrap;
|
||||||
|
}
|
||||||
|
|
||||||
|
.header_bar {
|
||||||
|
background-color: #f7f7f7;
|
||||||
|
margin-bottom: 19px;
|
||||||
|
overflow-x: scroll;
|
||||||
|
margin-left: calc(-1 * var(--size-4));
|
||||||
|
margin-right: calc(-1 * var(--size-4));
|
||||||
|
display: block !important;
|
||||||
|
text-wrap: nowrap;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .header_bar {
|
||||||
|
border: none !important;
|
||||||
|
background-color: #8080802b;
|
||||||
|
}
|
||||||
|
|
||||||
|
.header_bar button.selected {
|
||||||
|
border-radius: 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
.textbox_default textarea {
|
||||||
|
height: calc(100dvh - 271px);
|
||||||
|
}
|
||||||
|
|
||||||
|
.textbox_default_output textarea {
|
||||||
|
height: calc(100dvh - 185px);
|
||||||
|
}
|
||||||
|
|
||||||
|
.textbox textarea {
|
||||||
|
height: calc(100dvh - 241px);
|
||||||
|
}
|
||||||
|
|
||||||
|
.textbox_logits textarea {
|
||||||
|
height: calc(100dvh - 236px);
|
||||||
|
}
|
||||||
|
|
||||||
|
.textbox_logits_notebook textarea {
|
||||||
|
height: calc(100dvh - 292px);
|
||||||
|
}
|
||||||
|
|
||||||
|
.monospace textarea {
|
||||||
|
font-family: monospace;
|
||||||
|
}
|
||||||
|
|
||||||
|
.textbox_default textarea,
|
||||||
|
.textbox_default_output textarea,
|
||||||
|
.textbox_logits textarea,
|
||||||
|
.textbox_logits_notebook textarea,
|
||||||
|
.textbox textarea {
|
||||||
|
font-size: 16px !important;
|
||||||
|
color: #46464A !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark textarea {
|
||||||
|
color: #efefef !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media screen and (width <= 711px) {
|
||||||
|
.textbox_default textarea {
|
||||||
|
height: calc(100dvh - 259px);
|
||||||
|
}
|
||||||
|
|
||||||
|
div .default-token-counter {
|
||||||
|
top: calc( 0.5 * (100dvh - 236px) ) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.transparent-substring {
|
||||||
|
display: none;
|
||||||
|
}
|
||||||
|
|
||||||
|
.hover-menu {
|
||||||
|
min-width: 250px !important;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Hide the gradio footer */
|
||||||
|
footer {
|
||||||
|
display: none !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
button {
|
||||||
|
font-size: 14px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.file-saver {
|
||||||
|
position: fixed !important;
|
||||||
|
height: 100%;
|
||||||
|
z-index: 1000;
|
||||||
|
background-color: rgb(0 0 0 / 50%) !important;
|
||||||
|
margin-left: -20px;
|
||||||
|
margin-right: -20px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.file-saver > :first-child {
|
||||||
|
position: fixed !important;
|
||||||
|
top: 50%;
|
||||||
|
left: 50%;
|
||||||
|
transform: translate(-50%, -50%); /* center horizontally */
|
||||||
|
width: 100%;
|
||||||
|
max-width: 500px;
|
||||||
|
background-color: var(--input-background-fill);
|
||||||
|
border: var(--input-border-width) solid var(--input-border-color) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.file-saver > :first-child > :nth-child(2) {
|
||||||
|
background: var(--block-background-fill);
|
||||||
|
}
|
||||||
|
|
||||||
|
.checkboxgroup-table label {
|
||||||
|
background: none !important;
|
||||||
|
padding: 0 !important;
|
||||||
|
border: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.checkboxgroup-table div {
|
||||||
|
display: grid !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.markdown ul ol {
|
||||||
|
font-size: 100% !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.pretty_scrollbar::-webkit-scrollbar {
|
||||||
|
width: 5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.pretty_scrollbar::-webkit-scrollbar-track {
|
||||||
|
background: transparent;
|
||||||
|
}
|
||||||
|
|
||||||
|
.pretty_scrollbar::-webkit-scrollbar-thumb,
|
||||||
|
.pretty_scrollbar::-webkit-scrollbar-thumb:hover {
|
||||||
|
background: #c5c5d2;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .pretty_scrollbar::-webkit-scrollbar-thumb,
|
||||||
|
.dark .pretty_scrollbar::-webkit-scrollbar-thumb:hover {
|
||||||
|
background: #374151;
|
||||||
|
}
|
||||||
|
|
||||||
|
.pretty_scrollbar::-webkit-resizer {
|
||||||
|
background: #c5c5d2;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dark .pretty_scrollbar::-webkit-resizer {
|
||||||
|
background: #374151;
|
||||||
|
}
|
||||||
|
|
||||||
|
audio {
|
||||||
|
max-width: 100%;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Copied from https://github.com/AUTOMATIC1111/stable-diffusion-webui */
|
||||||
|
.token-counter {
|
||||||
|
position: absolute !important;
|
||||||
|
top: calc( 0.5 * (100dvh - 218px) ) !important;
|
||||||
|
right: 2px;
|
||||||
|
z-index: 100;
|
||||||
|
background: var(--input-background-fill) !important;
|
||||||
|
min-height: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.default-token-counter {
|
||||||
|
top: calc( 0.5 * (100dvh - 248px) ) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.token-counter span {
|
||||||
|
padding: 1px;
|
||||||
|
box-shadow: 0 0 0 0.3em rgb(192 192 192 / 15%), inset 0 0 0.6em rgb(192 192 192 / 7.5%);
|
||||||
|
border: 2px solid rgb(192 192 192 / 40%) !important;
|
||||||
|
border-radius: 0.4em;
|
||||||
|
}
|
||||||
|
|
||||||
|
.no-background {
|
||||||
|
background: var(--background-fill-primary) !important;
|
||||||
|
padding: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* ----------------------------------------------
|
||||||
|
Chat tab
|
||||||
|
---------------------------------------------- */
|
||||||
|
.h-\[40vh\], .wrap.svelte-byatnx.svelte-byatnx.svelte-byatnx {
|
||||||
|
height: 66.67vh
|
||||||
|
}
|
||||||
|
|
||||||
|
.gradio-container {
|
||||||
|
margin-left: auto !important;
|
||||||
|
margin-right: auto !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.w-screen {
|
||||||
|
width: unset
|
||||||
|
}
|
||||||
|
|
||||||
|
div.svelte-362y77>*, div.svelte-362y77>.form>* {
|
||||||
|
flex-wrap: nowrap
|
||||||
|
}
|
||||||
|
|
||||||
|
.pending.svelte-1ed2p3z {
|
||||||
|
opacity: 1;
|
||||||
|
}
|
||||||
|
|
||||||
|
.wrap.svelte-6roggh.svelte-6roggh {
|
||||||
|
max-height: 92.5%;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* This is for the microphone button in the whisper extension */
|
||||||
|
.sm.svelte-1ipelgc {
|
||||||
|
width: 100%;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-tab button#Generate, #chat-tab button#stop {
|
||||||
|
width: 89.3438px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-tab button, #notebook-tab button, #default-tab button {
|
||||||
|
min-width: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-tab > :first-child, #extensions {
|
||||||
|
max-width: 880px;
|
||||||
|
margin-left: auto;
|
||||||
|
margin-right: auto;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media screen and (width <= 688px) {
|
||||||
|
#chat-tab {
|
||||||
|
padding-left: 0;
|
||||||
|
padding-right: 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
.chat-parent {
|
||||||
|
height: calc(100dvh - 179px) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.old-ui .chat-parent {
|
||||||
|
height: calc(100dvh - 310px) !important;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
.chat {
|
||||||
|
margin-left: auto;
|
||||||
|
margin-right: auto;
|
||||||
|
max-width: 880px;
|
||||||
|
height: 100%;
|
||||||
|
overflow-y: auto;
|
||||||
|
padding-right: 15px;
|
||||||
|
display: flex;
|
||||||
|
flex-direction: column;
|
||||||
|
word-break: break-word;
|
||||||
|
overflow-wrap: anywhere;
|
||||||
|
}
|
||||||
|
|
||||||
|
.chat-parent {
|
||||||
|
height: calc(100dvh - 181px);
|
||||||
|
overflow: auto !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.old-ui .chat-parent {
|
||||||
|
height: calc(100dvh - 270px);
|
||||||
|
}
|
||||||
|
|
||||||
|
.chat-parent.bigchat {
|
||||||
|
height: calc(100dvh - 181px) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.chat > .messages {
|
||||||
|
display: flex;
|
||||||
|
flex-direction: column;
|
||||||
|
}
|
||||||
|
|
||||||
|
.chat .message:last-child {
|
||||||
|
margin-bottom: 0 !important;
|
||||||
|
padding-bottom: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body li:not(:last-child) {
|
||||||
|
margin-top: 0 !important;
|
||||||
|
margin-bottom: 2px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body li:last-child {
|
||||||
|
margin-bottom: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body li > p {
|
||||||
|
display: inline !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body ul, .message-body ol {
|
||||||
|
font-size: 15px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body ul {
|
||||||
|
list-style-type: disc !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body pre:not(:last-child) {
|
||||||
|
margin-bottom: 35.625px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body pre:last-child {
|
||||||
|
margin-bottom: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body code {
|
||||||
|
white-space: pre-wrap !important;
|
||||||
|
word-wrap: break-word !important;
|
||||||
|
border: 1px solid var(--border-color-primary);
|
||||||
|
border-radius: var(--radius-sm);
|
||||||
|
background: var(--background-fill-secondary);
|
||||||
|
font-size: 90%;
|
||||||
|
padding: 1px 3px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body pre > code {
|
||||||
|
display: block;
|
||||||
|
padding: 15px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message-body :not(pre) > code {
|
||||||
|
white-space: normal !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-input {
|
||||||
|
padding: 0;
|
||||||
|
padding-top: 18px;
|
||||||
|
background: transparent;
|
||||||
|
border: none;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-input textarea:focus {
|
||||||
|
box-shadow: none !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-input > :first-child {
|
||||||
|
background-color: transparent;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-input .progress-text {
|
||||||
|
display: none;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media print {
|
||||||
|
body {
|
||||||
|
visibility: hidden;
|
||||||
|
}
|
||||||
|
|
||||||
|
.chat {
|
||||||
|
visibility: visible;
|
||||||
|
position: absolute;
|
||||||
|
left: 0;
|
||||||
|
top: 0;
|
||||||
|
max-width: unset;
|
||||||
|
max-height: unset;
|
||||||
|
width: 100%;
|
||||||
|
overflow-y: visible;
|
||||||
|
}
|
||||||
|
|
||||||
|
.message {
|
||||||
|
break-inside: avoid;
|
||||||
|
}
|
||||||
|
|
||||||
|
.gradio-container {
|
||||||
|
overflow: visible;
|
||||||
|
}
|
||||||
|
|
||||||
|
.tab-nav {
|
||||||
|
display: none !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-tab > :first-child {
|
||||||
|
max-width: unset;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
#show-controls {
|
||||||
|
position: absolute;
|
||||||
|
height: 100%;
|
||||||
|
background-color: var(--background-fill-primary);
|
||||||
|
border: 0 !important;
|
||||||
|
border-radius: 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
#show-controls label {
|
||||||
|
z-index: 1000;
|
||||||
|
position: absolute;
|
||||||
|
left: calc(100% - 168px);
|
||||||
|
}
|
||||||
|
|
||||||
|
#typing-container {
|
||||||
|
display: none;
|
||||||
|
position: absolute;
|
||||||
|
background-color: transparent;
|
||||||
|
left: -2px;
|
||||||
|
padding: var(--block-padding);
|
||||||
|
}
|
||||||
|
|
||||||
|
.typing {
|
||||||
|
position: relative;
|
||||||
|
}
|
||||||
|
|
||||||
|
.visible-dots #typing-container {
|
||||||
|
display: block;
|
||||||
|
}
|
||||||
|
|
||||||
|
.typing span {
|
||||||
|
content: '';
|
||||||
|
animation: blink 1.5s infinite;
|
||||||
|
animation-fill-mode: both;
|
||||||
|
height: 10px;
|
||||||
|
width: 10px;
|
||||||
|
background: #3b5998;;
|
||||||
|
position: absolute;
|
||||||
|
left:0;
|
||||||
|
top:0;
|
||||||
|
border-radius: 50%;
|
||||||
|
}
|
||||||
|
|
||||||
|
.typing .dot1 {
|
||||||
|
animation-delay: .2s;
|
||||||
|
margin-left: calc(10px * 1.5);
|
||||||
|
}
|
||||||
|
|
||||||
|
.typing .dot2 {
|
||||||
|
animation-delay: .4s;
|
||||||
|
margin-left: calc(10px * 3);
|
||||||
|
}
|
||||||
|
|
||||||
|
@keyframes blink {
|
||||||
|
0% {
|
||||||
|
opacity: .1;
|
||||||
|
}
|
||||||
|
|
||||||
|
20% {
|
||||||
|
opacity: 1;
|
||||||
|
}
|
||||||
|
|
||||||
|
100% {
|
||||||
|
opacity: .1;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-tab .generating {
|
||||||
|
display: none !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.hover-element {
|
||||||
|
position: relative;
|
||||||
|
font-size: 24px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.hover-menu {
|
||||||
|
display: none;
|
||||||
|
position: absolute;
|
||||||
|
bottom: 80%;
|
||||||
|
left: 0;
|
||||||
|
background-color: var(--background-fill-secondary);
|
||||||
|
box-shadow: 0 0 10px rgb(0 0 0 / 50%);
|
||||||
|
z-index: 10000;
|
||||||
|
min-width: 330px;
|
||||||
|
flex-direction: column;
|
||||||
|
}
|
||||||
|
|
||||||
|
.hover-menu button {
|
||||||
|
width: 100%;
|
||||||
|
background: transparent !important;
|
||||||
|
border-radius: 0 !important;
|
||||||
|
justify-content: space-between;
|
||||||
|
margin: 0 !important;
|
||||||
|
height: 36px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.hover-menu button:not(#clear-history-confirm) {
|
||||||
|
border-bottom: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.hover-menu button:not(#clear-history-confirm):last-child {
|
||||||
|
border-bottom: var(--button-border-width) solid var(--button-secondary-border-color) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.hover-menu button:hover {
|
||||||
|
background: var(--button-secondary-background-fill-hover) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.transparent-substring {
|
||||||
|
opacity: 0.333;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-tab:not(.old-ui) #chat-buttons {
|
||||||
|
display: none !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#gr-hover-container {
|
||||||
|
min-width: 0 !important;
|
||||||
|
display: flex;
|
||||||
|
flex-direction: column-reverse;
|
||||||
|
padding-right: 20px;
|
||||||
|
padding-bottom: 3px;
|
||||||
|
flex-grow: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#generate-stop-container {
|
||||||
|
min-width: 0 !important;
|
||||||
|
display: flex;
|
||||||
|
flex-direction: column-reverse;
|
||||||
|
padding-bottom: 3px;
|
||||||
|
flex: 0 auto !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-input-container {
|
||||||
|
min-width: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-input-container > .form {
|
||||||
|
background: transparent;
|
||||||
|
border: none;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-input-row {
|
||||||
|
padding-bottom: 20px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.old-ui #chat-input-row, #chat-input-row.bigchat {
|
||||||
|
padding-bottom: 0 !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
#chat-col {
|
||||||
|
padding-bottom: 115px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.old-ui #chat-col, #chat-col.bigchat {
|
||||||
|
padding-bottom: 95px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.old-ui #chat-buttons #clear-history-confirm {
|
||||||
|
order: -1;
|
||||||
|
}
|
||||||
|
|
||||||
|
.chat ol, .chat ul {
|
||||||
|
margin-top: 6px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* ----------------------------------------------
|
||||||
|
Past chats menus
|
||||||
|
---------------------------------------------- */
|
||||||
|
#past-chats-row {
|
||||||
|
margin-bottom: calc( -1 * var(--layout-gap) );
|
||||||
|
}
|
||||||
|
|
||||||
|
#rename-row label {
|
||||||
|
margin-top: var(--layout-gap);
|
||||||
|
}
|
||||||
|
|
||||||
|
/* ----------------------------------------------
|
||||||
|
Keep dropdown menus above errored components
|
||||||
|
---------------------------------------------- */
|
||||||
|
.options {
|
||||||
|
z-index: 100 !important;
|
||||||
|
}
|
||||||
@ -0,0 +1,292 @@
|
|||||||
|
'''
|
||||||
|
Downloads models from Hugging Face to models/username_modelname.
|
||||||
|
|
||||||
|
Example:
|
||||||
|
python download-model.py facebook/opt-1.3b
|
||||||
|
|
||||||
|
'''
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
import base64
|
||||||
|
import datetime
|
||||||
|
import hashlib
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
import sys
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import requests
|
||||||
|
import tqdm
|
||||||
|
from requests.adapters import HTTPAdapter
|
||||||
|
from tqdm.contrib.concurrent import thread_map
|
||||||
|
|
||||||
|
base = "https://huggingface.co"
|
||||||
|
|
||||||
|
|
||||||
|
class ModelDownloader:
|
||||||
|
def __init__(self, max_retries=5):
|
||||||
|
self.session = requests.Session()
|
||||||
|
if max_retries:
|
||||||
|
self.session.mount('https://cdn-lfs.huggingface.co', HTTPAdapter(max_retries=max_retries))
|
||||||
|
self.session.mount('https://huggingface.co', HTTPAdapter(max_retries=max_retries))
|
||||||
|
if os.getenv('HF_USER') is not None and os.getenv('HF_PASS') is not None:
|
||||||
|
self.session.auth = (os.getenv('HF_USER'), os.getenv('HF_PASS'))
|
||||||
|
if os.getenv('HF_TOKEN') is not None:
|
||||||
|
self.session.headers = {'authorization': f'Bearer {os.getenv("HF_TOKEN")}'}
|
||||||
|
|
||||||
|
def sanitize_model_and_branch_names(self, model, branch):
|
||||||
|
if model[-1] == '/':
|
||||||
|
model = model[:-1]
|
||||||
|
|
||||||
|
if model.startswith(base + '/'):
|
||||||
|
model = model[len(base) + 1:]
|
||||||
|
|
||||||
|
model_parts = model.split(":")
|
||||||
|
model = model_parts[0] if len(model_parts) > 0 else model
|
||||||
|
branch = model_parts[1] if len(model_parts) > 1 else branch
|
||||||
|
|
||||||
|
if branch is None:
|
||||||
|
branch = "main"
|
||||||
|
else:
|
||||||
|
pattern = re.compile(r"^[a-zA-Z0-9._-]+$")
|
||||||
|
if not pattern.match(branch):
|
||||||
|
raise ValueError(
|
||||||
|
"Invalid branch name. Only alphanumeric characters, period, underscore and dash are allowed.")
|
||||||
|
|
||||||
|
return model, branch
|
||||||
|
|
||||||
|
def get_download_links_from_huggingface(self, model, branch, text_only=False, specific_file=None):
|
||||||
|
page = f"/api/models/{model}/tree/{branch}"
|
||||||
|
cursor = b""
|
||||||
|
|
||||||
|
links = []
|
||||||
|
sha256 = []
|
||||||
|
classifications = []
|
||||||
|
has_pytorch = False
|
||||||
|
has_pt = False
|
||||||
|
has_gguf = False
|
||||||
|
has_safetensors = False
|
||||||
|
is_lora = False
|
||||||
|
while True:
|
||||||
|
url = f"{base}{page}" + (f"?cursor={cursor.decode()}" if cursor else "")
|
||||||
|
r = self.session.get(url, timeout=10)
|
||||||
|
r.raise_for_status()
|
||||||
|
content = r.content
|
||||||
|
|
||||||
|
dict = json.loads(content)
|
||||||
|
if len(dict) == 0:
|
||||||
|
break
|
||||||
|
|
||||||
|
for i in range(len(dict)):
|
||||||
|
fname = dict[i]['path']
|
||||||
|
if specific_file not in [None, ''] and fname != specific_file:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if not is_lora and fname.endswith(('adapter_config.json', 'adapter_model.bin')):
|
||||||
|
is_lora = True
|
||||||
|
|
||||||
|
is_pytorch = re.match(r"(pytorch|adapter|gptq)_model.*\.bin", fname)
|
||||||
|
is_safetensors = re.match(r".*\.safetensors", fname)
|
||||||
|
is_pt = re.match(r".*\.pt", fname)
|
||||||
|
is_gguf = re.match(r'.*\.gguf', fname)
|
||||||
|
is_tiktoken = re.match(r".*\.tiktoken", fname)
|
||||||
|
is_tokenizer = re.match(r"(tokenizer|ice|spiece).*\.model", fname) or is_tiktoken
|
||||||
|
is_text = re.match(r".*\.(txt|json|py|md)", fname) or is_tokenizer
|
||||||
|
if any((is_pytorch, is_safetensors, is_pt, is_gguf, is_tokenizer, is_text)):
|
||||||
|
if 'lfs' in dict[i]:
|
||||||
|
sha256.append([fname, dict[i]['lfs']['oid']])
|
||||||
|
|
||||||
|
if is_text:
|
||||||
|
links.append(f"https://huggingface.co/{model}/resolve/{branch}/{fname}")
|
||||||
|
classifications.append('text')
|
||||||
|
continue
|
||||||
|
|
||||||
|
if not text_only:
|
||||||
|
links.append(f"https://huggingface.co/{model}/resolve/{branch}/{fname}")
|
||||||
|
if is_safetensors:
|
||||||
|
has_safetensors = True
|
||||||
|
classifications.append('safetensors')
|
||||||
|
elif is_pytorch:
|
||||||
|
has_pytorch = True
|
||||||
|
classifications.append('pytorch')
|
||||||
|
elif is_pt:
|
||||||
|
has_pt = True
|
||||||
|
classifications.append('pt')
|
||||||
|
elif is_gguf:
|
||||||
|
has_gguf = True
|
||||||
|
classifications.append('gguf')
|
||||||
|
|
||||||
|
cursor = base64.b64encode(f'{{"file_name":"{dict[-1]["path"]}"}}'.encode()) + b':50'
|
||||||
|
cursor = base64.b64encode(cursor)
|
||||||
|
cursor = cursor.replace(b'=', b'%3D')
|
||||||
|
|
||||||
|
# If both pytorch and safetensors are available, download safetensors only
|
||||||
|
if (has_pytorch or has_pt) and has_safetensors:
|
||||||
|
for i in range(len(classifications) - 1, -1, -1):
|
||||||
|
if classifications[i] in ['pytorch', 'pt']:
|
||||||
|
links.pop(i)
|
||||||
|
|
||||||
|
if has_gguf and specific_file is None:
|
||||||
|
for i in range(len(classifications) - 1, -1, -1):
|
||||||
|
if 'q4_k_m' not in links[i].lower():
|
||||||
|
links.pop(i)
|
||||||
|
|
||||||
|
is_llamacpp = has_gguf and specific_file is not None
|
||||||
|
return links, sha256, is_lora, is_llamacpp
|
||||||
|
|
||||||
|
def get_output_folder(self, model, branch, is_lora, is_llamacpp=False, base_folder=None):
|
||||||
|
if base_folder is None:
|
||||||
|
base_folder = 'models' if not is_lora else 'loras'
|
||||||
|
|
||||||
|
# If the model is of type GGUF, save directly in the base_folder
|
||||||
|
if is_llamacpp:
|
||||||
|
return Path(base_folder)
|
||||||
|
|
||||||
|
output_folder = f"{'_'.join(model.split('/')[-2:])}"
|
||||||
|
if branch != 'main':
|
||||||
|
output_folder += f'_{branch}'
|
||||||
|
|
||||||
|
output_folder = Path(base_folder) / output_folder
|
||||||
|
return output_folder
|
||||||
|
|
||||||
|
def get_single_file(self, url, output_folder, start_from_scratch=False):
|
||||||
|
filename = Path(url.rsplit('/', 1)[1])
|
||||||
|
output_path = output_folder / filename
|
||||||
|
headers = {}
|
||||||
|
mode = 'wb'
|
||||||
|
if output_path.exists() and not start_from_scratch:
|
||||||
|
|
||||||
|
# Check if the file has already been downloaded completely
|
||||||
|
r = self.session.get(url, stream=True, timeout=10)
|
||||||
|
total_size = int(r.headers.get('content-length', 0))
|
||||||
|
if output_path.stat().st_size >= total_size:
|
||||||
|
return
|
||||||
|
|
||||||
|
# Otherwise, resume the download from where it left off
|
||||||
|
headers = {'Range': f'bytes={output_path.stat().st_size}-'}
|
||||||
|
mode = 'ab'
|
||||||
|
|
||||||
|
with self.session.get(url, stream=True, headers=headers, timeout=10) as r:
|
||||||
|
r.raise_for_status() # Do not continue the download if the request was unsuccessful
|
||||||
|
total_size = int(r.headers.get('content-length', 0))
|
||||||
|
block_size = 1024 * 1024 # 1MB
|
||||||
|
|
||||||
|
tqdm_kwargs = {
|
||||||
|
'total': total_size,
|
||||||
|
'unit': 'iB',
|
||||||
|
'unit_scale': True,
|
||||||
|
'bar_format': '{l_bar}{bar}| {n_fmt:6}/{total_fmt:6} {rate_fmt:6}'
|
||||||
|
}
|
||||||
|
|
||||||
|
if 'COLAB_GPU' in os.environ:
|
||||||
|
tqdm_kwargs.update({
|
||||||
|
'position': 0,
|
||||||
|
'leave': True
|
||||||
|
})
|
||||||
|
|
||||||
|
with open(output_path, mode) as f:
|
||||||
|
with tqdm.tqdm(**tqdm_kwargs) as t:
|
||||||
|
count = 0
|
||||||
|
for data in r.iter_content(block_size):
|
||||||
|
t.update(len(data))
|
||||||
|
f.write(data)
|
||||||
|
if total_size != 0 and self.progress_bar is not None:
|
||||||
|
count += len(data)
|
||||||
|
self.progress_bar(float(count) / float(total_size), f"{filename}")
|
||||||
|
|
||||||
|
def start_download_threads(self, file_list, output_folder, start_from_scratch=False, threads=4):
|
||||||
|
thread_map(lambda url: self.get_single_file(url, output_folder, start_from_scratch=start_from_scratch), file_list, max_workers=threads, disable=True)
|
||||||
|
|
||||||
|
def download_model_files(self, model, branch, links, sha256, output_folder, progress_bar=None, start_from_scratch=False, threads=4, specific_file=None, is_llamacpp=False):
|
||||||
|
self.progress_bar = progress_bar
|
||||||
|
|
||||||
|
# Create the folder and writing the metadata
|
||||||
|
output_folder.mkdir(parents=True, exist_ok=True)
|
||||||
|
|
||||||
|
if not is_llamacpp:
|
||||||
|
metadata = f'url: https://huggingface.co/{model}\n' \
|
||||||
|
f'branch: {branch}\n' \
|
||||||
|
f'download date: {datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")}\n'
|
||||||
|
|
||||||
|
sha256_str = '\n'.join([f' {item[1]} {item[0]}' for item in sha256])
|
||||||
|
if sha256_str:
|
||||||
|
metadata += f'sha256sum:\n{sha256_str}'
|
||||||
|
|
||||||
|
metadata += '\n'
|
||||||
|
(output_folder / 'huggingface-metadata.txt').write_text(metadata)
|
||||||
|
|
||||||
|
if specific_file:
|
||||||
|
print(f"Downloading {specific_file} to {output_folder}")
|
||||||
|
else:
|
||||||
|
print(f"Downloading the model to {output_folder}")
|
||||||
|
|
||||||
|
self.start_download_threads(links, output_folder, start_from_scratch=start_from_scratch, threads=threads)
|
||||||
|
|
||||||
|
def check_model_files(self, model, branch, links, sha256, output_folder):
|
||||||
|
# Validate the checksums
|
||||||
|
validated = True
|
||||||
|
for i in range(len(sha256)):
|
||||||
|
fpath = (output_folder / sha256[i][0])
|
||||||
|
|
||||||
|
if not fpath.exists():
|
||||||
|
print(f"The following file is missing: {fpath}")
|
||||||
|
validated = False
|
||||||
|
continue
|
||||||
|
|
||||||
|
with open(output_folder / sha256[i][0], "rb") as f:
|
||||||
|
file_hash = hashlib.file_digest(f, "sha256").hexdigest()
|
||||||
|
if file_hash != sha256[i][1]:
|
||||||
|
print(f'Checksum failed: {sha256[i][0]} {sha256[i][1]}')
|
||||||
|
validated = False
|
||||||
|
else:
|
||||||
|
print(f'Checksum validated: {sha256[i][0]} {sha256[i][1]}')
|
||||||
|
|
||||||
|
if validated:
|
||||||
|
print('[+] Validated checksums of all model files!')
|
||||||
|
else:
|
||||||
|
print('[-] Invalid checksums. Rerun download-model.py with the --clean flag.')
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument('MODEL', type=str, default=None, nargs='?')
|
||||||
|
parser.add_argument('--branch', type=str, default='main', help='Name of the Git branch to download from.')
|
||||||
|
parser.add_argument('--threads', type=int, default=4, help='Number of files to download simultaneously.')
|
||||||
|
parser.add_argument('--text-only', action='store_true', help='Only download text files (txt/json).')
|
||||||
|
parser.add_argument('--specific-file', type=str, default=None, help='Name of the specific file to download (if not provided, downloads all).')
|
||||||
|
parser.add_argument('--output', type=str, default=None, help='The folder where the model should be saved.')
|
||||||
|
parser.add_argument('--clean', action='store_true', help='Does not resume the previous download.')
|
||||||
|
parser.add_argument('--check', action='store_true', help='Validates the checksums of model files.')
|
||||||
|
parser.add_argument('--max-retries', type=int, default=5, help='Max retries count when get error in download time.')
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
branch = args.branch
|
||||||
|
model = args.MODEL
|
||||||
|
specific_file = args.specific_file
|
||||||
|
|
||||||
|
if model is None:
|
||||||
|
print("Error: Please specify the model you'd like to download (e.g. 'python download-model.py facebook/opt-1.3b').")
|
||||||
|
sys.exit()
|
||||||
|
|
||||||
|
downloader = ModelDownloader(max_retries=args.max_retries)
|
||||||
|
# Clean up the model/branch names
|
||||||
|
try:
|
||||||
|
model, branch = downloader.sanitize_model_and_branch_names(model, branch)
|
||||||
|
except ValueError as err_branch:
|
||||||
|
print(f"Error: {err_branch}")
|
||||||
|
sys.exit()
|
||||||
|
|
||||||
|
# Get the download links from Hugging Face
|
||||||
|
links, sha256, is_lora, is_llamacpp = downloader.get_download_links_from_huggingface(model, branch, text_only=args.text_only, specific_file=specific_file)
|
||||||
|
|
||||||
|
# Get the output folder
|
||||||
|
output_folder = downloader.get_output_folder(model, branch, is_lora, is_llamacpp=is_llamacpp, base_folder=args.output)
|
||||||
|
|
||||||
|
if args.check:
|
||||||
|
# Check previously downloaded files
|
||||||
|
downloader.check_model_files(model, branch, links, sha256, output_folder)
|
||||||
|
else:
|
||||||
|
# Download files
|
||||||
|
downloader.download_model_files(model, branch, links, sha256, output_folder, specific_file=specific_file, threads=args.threads, is_llamacpp=is_llamacpp)
|
||||||
@ -0,0 +1,92 @@
|
|||||||
|
# Training_PRO
|
||||||
|
|
||||||
|
This is an expanded and reworked Training tab
|
||||||
|
Maintained by FP
|
||||||
|
|
||||||
|
[](https://ko-fi.com/Q5Q5MOB4M)
|
||||||
|
|
||||||
|
Repo home:
|
||||||
|
|
||||||
|
https://github.com/FartyPants/Training_PRO
|
||||||
|
|
||||||
|
In general the repo above is ahead of the extension included in text WebUi.
|
||||||
|
|
||||||
|
## News
|
||||||
|
|
||||||
|
- NEFtune: add noise to help with generalization
|
||||||
|
- Loss Graph in interface.
|
||||||
|
- Supports Mistral training
|
||||||
|
- some roundabout around pytorch and transformers version desync
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Features/Changes
|
||||||
|
|
||||||
|
- Chunking: precise raw text slicer (PRTS) uses sentence slicing and making sure things are clean on all ends
|
||||||
|
- overlap chunking - this special overlapping will make additional overlap block based on logical rules (aka no overlap block on hard cut)
|
||||||
|
- custom scheduler (follow the code to make your own) In LR Scheduler select FP_low_epoch_annealing - this scheduler will keep the LR constant for first epoch then use cosine for the rest - this part would be best to spawn into a new py file
|
||||||
|
- saves graph png file at the end with learning rate and loss per epoch
|
||||||
|
- adding EOS to each block or to hard cut only
|
||||||
|
- automatically lowers gradient accumulation if you go overboard and set gradient accumulation that will be higher than actual data - transformers would then throw error (or they used to, not sure if still true) but in any way, it will fix bad data
|
||||||
|
- turn BOS on and OFF
|
||||||
|
- target selector
|
||||||
|
- DEMENTOR LEARNING (experimental) Deep Memorization Enforcement Through Overlapping and Repetition. This is an experiment for long-text learning using low epochs (basically use 1 epoch with constant LR or 2 epochs with FP_low_epoch_annealing LR scheduler)
|
||||||
|
- Getting rid of micro batch size/batch size confusion. Now there is True Batch Size and Gradient accumulation slider, consisten with all the other training out there
|
||||||
|
- Ability to save Checkpoint during training with a button
|
||||||
|
- Ability to change Stop Loss during training
|
||||||
|
- different modes of checkpoint auto saving
|
||||||
|
- Function to Check Dataset and suggest parameters such as warmup and checkpoint save frequency before training
|
||||||
|
- Graph Training Loss in interface
|
||||||
|
- more custom schedulers
|
||||||
|
|
||||||
|
### Notes:
|
||||||
|
|
||||||
|
This uses it's own chunking code for raw text based on sentence splitting. This will avoid weird cuts in the chunks and each chunk should now start with sentence and end on some sentence. It works hand in hand with Hard Cut. A propper use is to structure your text into logical blocks (ideas) separated by three \n then use three \n in hard cut. This way each chunk will contain only one flow of ideas and not derail in the thoughts. And Overlapping code will create overlapped blocks on sentence basis too, but not cross hard cut, thus not cross different ideas either. Does it make any sense? No? Hmmmm...
|
||||||
|
|
||||||
|
### Custom schedulers
|
||||||
|
|
||||||
|
A bunch of custom (combination) schedulers are added to the LR schedule. These are based on my own experiments
|
||||||
|
|
||||||
|
**FP_low_epoch_annealing**
|
||||||
|
|
||||||
|
Uses constant LR (with warmup) for 1 epoch only. The rest of the epoch(s) is cosine annealing. So 10 epochs - 1 will be constant 9 will be nose dive down. However a typical usage would be 2 epochs (hence low epoch in name). 1st is constant, the second is annealing. Simple. I use it 90% of time.
|
||||||
|
|
||||||
|
**FP_half_time_annealing**
|
||||||
|
|
||||||
|
Like the low epoch, but now the total number of steps is divided by 2. First half is constant, second half is annealing. So 10 epochs - 5 will be constant, 5 will be cosine nose down.
|
||||||
|
|
||||||
|
**FP_raise_fall_creative**
|
||||||
|
|
||||||
|
This is a sine raise till half of the total steps then cosine fall the rest. (Or you may think of the curve as sine in its entirety. The most learning is done in the hump, in the middle. The warmup entry has no effect, since sine is automatically warm up.
|
||||||
|
The idea is to start very mildly as not to overfit with the first blocks of dataset. It seems to broaden the scope of the model making it less strict for tight dataset.
|
||||||
|
|
||||||
|
### Targets
|
||||||
|
|
||||||
|
Normal LORA is q, v and that's what you should use. You can use (q k v o) or (q k v) and it will give you a lot more trainable parameters. The benefit is that you can keep rank lower and still attain the same coherency as q v with high rank. Guanaco has been trained with QLORA and q k v o for example and they swear by it.
|
||||||
|
|
||||||
|
### DEMENTOR LEARNING (experimental) Deep Memorization Enforcement Through Overlapping and Repetition
|
||||||
|
|
||||||
|
This is and experimental chunking to train long-form text in low number of epochs (basically 1) with sliding repetition. The depth of learning directly depends on the cutoff_length. Increasing cutoff length will also increase number of blocks created from long-form text (which is contrary to normal training). It is based on my own wild experiments.
|
||||||
|
|
||||||
|
### Getting rid of batch size and micro batch size
|
||||||
|
|
||||||
|
Keeping consistency with everyone else.
|
||||||
|
|
||||||
|
Listen, There is only ONE batch size - the True batch size (called previously micro-batch size in WebUI) - this is how many blocks are processed at once (during a single step). It eats GPU, but it really helps with the quality training (in fact the ideal batch size would be the same as number of blocks - which is unrealistic) - so the idea is to cram as much True Batch Size before your GPU blows with OOM. On 24GB this is about 10 for 13b (loaded with 4-bit)
|
||||||
|
|
||||||
|
So no micro batch size - it is now called True Batch Size, because that's what it is.
|
||||||
|
|
||||||
|
The other thing is Gradient Accumulation - this is an emulation of the above Batch size - a virtual batch size, if you will. If your GPU can't handle real batch size then you may fake it using Gradient Accumulation. This will accumulate the gradients over so many steps defined here and then update the weights at the end without increase in GPU.
|
||||||
|
Gradient accumulation is like a virtual Batch size multiplier without the GPU penalty.
|
||||||
|
|
||||||
|
If your batch size is 4 and your gradient accumulation is 2 then it sort of behaves as if we have batch size 8. *Sort of* because Batch size of 4 and GA of 2 is NOT the same as batch size of 2 and GA of 4. (It produces different weights - hence it's not an equivalent). The idea is that if you don't have GPU - using GA to extend batch size is the next best thing (good enough) since you have no other choice.
|
||||||
|
|
||||||
|
If all you can afford is 1 batch size, then increasing GA will likely make the learning better in some range of GA (it's not always more is better).
|
||||||
|
|
||||||
|
However - GA is not some golden goose. As said, it isn't the same as batch size. In fact GA may worsen your learning as well.
|
||||||
|
|
||||||
|
I would suggest a series of experiment where you would put batch size as high as possible without OOM, set GA 1, then repeat training while increasing the GA (2, 4...), and see how the model changes. It's likely that it would follow some sort of curve where GA will seem to help before it will make it worse. Some people believe that if you can squeeze 6 BATCH Size, then you should not bother with GA at all... YMMW
|
||||||
|
|
||||||
|
High Batch Size vs High GA would also likely produce different results in terms of learning words vs style. How? Hmmmm... good question.
|
||||||
|
|
||||||
|
One optical "benefit" of GA is that the loss will fluctuate less (because of all the gradient accumulation, which works as a form of noise smoothing as well).
|
||||||
@ -0,0 +1,433 @@
|
|||||||
|
from functools import partial
|
||||||
|
import torch
|
||||||
|
import transformers
|
||||||
|
import math
|
||||||
|
from torch.optim.lr_scheduler import LambdaLR
|
||||||
|
|
||||||
|
from peft import (
|
||||||
|
PeftModel,
|
||||||
|
)
|
||||||
|
|
||||||
|
RED = "\033[91m"
|
||||||
|
YELLOW = "\033[93m"
|
||||||
|
GREEN = "\033[92m"
|
||||||
|
RESET = "\033[0m"
|
||||||
|
|
||||||
|
last_print_label = ''
|
||||||
|
|
||||||
|
custom_scheduler_params = {'trigger_loss': 0.0, 'ramp_down_ratio':1.0, 'current_loss': 0.0,'dynamic_scheduler_stop': False, 'calc_ramp_down_at_step': 0, 'calc_num_training_steps': 0}
|
||||||
|
|
||||||
|
|
||||||
|
def custom_scheduler_global_update(current_loss: float):
|
||||||
|
custom_scheduler_params.update({'current_loss': current_loss})
|
||||||
|
|
||||||
|
def custom_scheduler_global_setup(trigger_loss: float, ramp_down_ratio: float):
|
||||||
|
custom_scheduler_params.update({'trigger_loss': trigger_loss})
|
||||||
|
custom_scheduler_params.update({'ramp_down_ratio': ramp_down_ratio})
|
||||||
|
|
||||||
|
# calculates the total num steps after trigger
|
||||||
|
custom_scheduler_params.update({'calc_num_training_steps': 0})
|
||||||
|
#calculates steps when the ramp_down trigger occured
|
||||||
|
custom_scheduler_params.update({'calc_ramp_down_at_step': 0})
|
||||||
|
# triggers scheduler stopping after it reached calc_num_training_steps
|
||||||
|
custom_scheduler_params.update({'dynamic_scheduler_stop': False})
|
||||||
|
|
||||||
|
|
||||||
|
# hold constant to the half of epochs then cosine down to 0
|
||||||
|
def _get_fp_half_schedule_with_warmup_lr_lambda(current_step: int, *, num_warmup_steps: int, num_training_steps: int, num_firstepoch_steps: int):
|
||||||
|
|
||||||
|
global last_print_label
|
||||||
|
print_label = ''
|
||||||
|
|
||||||
|
half_steps = num_training_steps//2
|
||||||
|
|
||||||
|
num_warmup_steps = min(num_warmup_steps,half_steps)
|
||||||
|
|
||||||
|
if current_step < num_warmup_steps:
|
||||||
|
print_label = 'Scheduler: Warmup'
|
||||||
|
elif current_step < half_steps:
|
||||||
|
print_label = 'Scheduler: Hold'
|
||||||
|
else:
|
||||||
|
print_label = 'Scheduler: Annealing'
|
||||||
|
|
||||||
|
if print_label != last_print_label:
|
||||||
|
print(print_label)
|
||||||
|
|
||||||
|
last_print_label = print_label
|
||||||
|
|
||||||
|
if current_step < num_warmup_steps:
|
||||||
|
return float(current_step) / float(max(1, num_warmup_steps))
|
||||||
|
|
||||||
|
if current_step < half_steps:
|
||||||
|
return 1.0
|
||||||
|
|
||||||
|
progress = float(current_step - half_steps) / float(max(1, num_training_steps - half_steps))
|
||||||
|
num_cycles = 0.5
|
||||||
|
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
|
||||||
|
|
||||||
|
|
||||||
|
# raise up in cosine, then fall back in cosine
|
||||||
|
def _get_fp_cosine_raise_and_fall_lr_lambda(current_step: int, *, num_warmup_steps: int, num_training_steps: int, num_firstepoch_steps: int):
|
||||||
|
|
||||||
|
global last_print_label
|
||||||
|
print_label = ''
|
||||||
|
|
||||||
|
half_steps = num_training_steps//2
|
||||||
|
|
||||||
|
#num_warmup_steps = min(num_warmup_steps,half_steps)
|
||||||
|
|
||||||
|
if current_step < half_steps:
|
||||||
|
print_label = 'Scheduler: Raise'
|
||||||
|
else:
|
||||||
|
print_label = 'Scheduler: Fall'
|
||||||
|
|
||||||
|
if print_label != last_print_label:
|
||||||
|
print(print_label)
|
||||||
|
|
||||||
|
last_print_label = print_label
|
||||||
|
|
||||||
|
|
||||||
|
# linear
|
||||||
|
# return float(current_step) / float(max(1, num_warmup_steps))
|
||||||
|
|
||||||
|
progress = float(current_step - half_steps) / float(max(1, num_training_steps - half_steps))
|
||||||
|
num_cycles = 0.5
|
||||||
|
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
|
||||||
|
|
||||||
|
# constant to the first epochs then cosine down to 0 over the rest epochs
|
||||||
|
def _get_fp_cosine_schedule_with_warmup_lr_lambda(current_step: int, *, num_warmup_steps: int, num_training_steps: int, num_firstepoch_steps: int):
|
||||||
|
|
||||||
|
global last_print_label
|
||||||
|
print_label = ''
|
||||||
|
|
||||||
|
num_warmup_steps = min(num_warmup_steps,num_firstepoch_steps)
|
||||||
|
|
||||||
|
if current_step < num_warmup_steps:
|
||||||
|
print_label = 'Scheduler: Warmup'
|
||||||
|
elif current_step < num_firstepoch_steps:
|
||||||
|
print_label = 'Scheduler: Hold'
|
||||||
|
else:
|
||||||
|
print_label = 'Scheduler: Annealing'
|
||||||
|
|
||||||
|
if print_label != last_print_label:
|
||||||
|
print(print_label)
|
||||||
|
|
||||||
|
last_print_label = print_label
|
||||||
|
|
||||||
|
if current_step < num_warmup_steps:
|
||||||
|
return float(current_step) / float(max(1, num_warmup_steps))
|
||||||
|
|
||||||
|
if current_step < num_firstepoch_steps:
|
||||||
|
return 1.0
|
||||||
|
|
||||||
|
progress = float(current_step - num_firstepoch_steps) / float(max(1, num_training_steps - num_firstepoch_steps))
|
||||||
|
num_cycles = 0.5
|
||||||
|
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
|
||||||
|
|
||||||
|
# halve lr each epoch
|
||||||
|
|
||||||
|
def _get_fp_cdrop_rate_schedule_with_warmup_lr_lambda(current_step: int, *, num_warmup_steps: int, num_training_steps: int, num_firstepoch_steps: int):
|
||||||
|
|
||||||
|
global last_print_label
|
||||||
|
print_label = ''
|
||||||
|
|
||||||
|
num_warmup_steps = min(num_warmup_steps, num_firstepoch_steps)
|
||||||
|
|
||||||
|
current_epoch = (current_step // num_firstepoch_steps) + 1
|
||||||
|
|
||||||
|
|
||||||
|
if current_step < num_warmup_steps:
|
||||||
|
print_label = 'Scheduler: Warmup'
|
||||||
|
elif current_step < num_firstepoch_steps:
|
||||||
|
print_label = 'Scheduler: Hold'
|
||||||
|
else:
|
||||||
|
print_label = 'Scheduler: Drop Rate'
|
||||||
|
|
||||||
|
if print_label != last_print_label:
|
||||||
|
print(print_label)
|
||||||
|
|
||||||
|
last_print_label = print_label
|
||||||
|
|
||||||
|
if current_step < num_warmup_steps:
|
||||||
|
return float(current_step) / float(max(1, num_warmup_steps))
|
||||||
|
|
||||||
|
if current_step < num_firstepoch_steps:
|
||||||
|
return 1.0
|
||||||
|
|
||||||
|
# Compute the learning rate for the annealing phase
|
||||||
|
|
||||||
|
learning_rate = 1.0 / float(2 ** (current_epoch - 1))
|
||||||
|
|
||||||
|
return learning_rate
|
||||||
|
|
||||||
|
# epoch decay: 1/(1 + decay * epoch)
|
||||||
|
|
||||||
|
def custom_cosine_scheduler_with_warmup(optimizer, num_warmup_steps, num_training_steps, num_firstepoch_steps, last_epoch=-1):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
optimizer ([`~torch.optim.Optimizer`]):
|
||||||
|
The optimizer for which to schedule the learning rate.
|
||||||
|
num_warmup_steps (`int`):
|
||||||
|
The number of steps for the warmup phase.
|
||||||
|
num_training_steps (`int`):
|
||||||
|
The total number of training steps.
|
||||||
|
last_epoch (`int`, *optional*, defaults to -1):
|
||||||
|
The index of the last epoch when resuming training.
|
||||||
|
|
||||||
|
Return:
|
||||||
|
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||||
|
"""
|
||||||
|
|
||||||
|
lr_lambda = partial(
|
||||||
|
_get_fp_cosine_schedule_with_warmup_lr_lambda,
|
||||||
|
num_warmup_steps=num_warmup_steps,
|
||||||
|
num_training_steps=num_training_steps,
|
||||||
|
num_firstepoch_steps = num_firstepoch_steps,
|
||||||
|
)
|
||||||
|
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||||
|
|
||||||
|
def custom_half_scheduler_with_warmup(optimizer, num_warmup_steps, num_training_steps, num_firstepoch_steps, last_epoch=-1):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
optimizer ([`~torch.optim.Optimizer`]):
|
||||||
|
The optimizer for which to schedule the learning rate.
|
||||||
|
num_warmup_steps (`int`):
|
||||||
|
The number of steps for the warmup phase.
|
||||||
|
num_training_steps (`int`):
|
||||||
|
The total number of training steps.
|
||||||
|
last_epoch (`int`, *optional*, defaults to -1):
|
||||||
|
The index of the last epoch when resuming training.
|
||||||
|
|
||||||
|
Return:
|
||||||
|
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||||
|
"""
|
||||||
|
|
||||||
|
lr_lambda = partial(
|
||||||
|
_get_fp_half_schedule_with_warmup_lr_lambda,
|
||||||
|
num_warmup_steps=num_warmup_steps,
|
||||||
|
num_training_steps=num_training_steps,
|
||||||
|
num_firstepoch_steps = num_firstepoch_steps,
|
||||||
|
)
|
||||||
|
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||||
|
|
||||||
|
def custom_raise_fall_scheduler_with_warmup(optimizer, num_warmup_steps, num_training_steps, num_firstepoch_steps, last_epoch=-1):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
optimizer ([`~torch.optim.Optimizer`]):
|
||||||
|
The optimizer for which to schedule the learning rate.
|
||||||
|
num_warmup_steps (`int`):
|
||||||
|
The number of steps for the warmup phase.
|
||||||
|
num_training_steps (`int`):
|
||||||
|
The total number of training steps.
|
||||||
|
last_epoch (`int`, *optional*, defaults to -1):
|
||||||
|
The index of the last epoch when resuming training.
|
||||||
|
|
||||||
|
Return:
|
||||||
|
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||||
|
"""
|
||||||
|
|
||||||
|
lr_lambda = partial(
|
||||||
|
_get_fp_cosine_raise_and_fall_lr_lambda,
|
||||||
|
num_warmup_steps=num_warmup_steps,
|
||||||
|
num_training_steps=num_training_steps,
|
||||||
|
num_firstepoch_steps = num_firstepoch_steps,
|
||||||
|
)
|
||||||
|
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||||
|
|
||||||
|
|
||||||
|
def neftune_forward(self, input: torch.Tensor):
|
||||||
|
"""
|
||||||
|
Implements the NEFTune forward pass for the model. Note this works only for
|
||||||
|
torch.nn.Embedding layers. This method is slightly adapted from the original source code
|
||||||
|
that can be found here: https://github.com/neelsjain/NEFTune
|
||||||
|
|
||||||
|
Args:
|
||||||
|
input (`torch.Tensor`):
|
||||||
|
The input tensor to the model.
|
||||||
|
noise_alpha (`float`):
|
||||||
|
The noise alpha value to use for the NEFTune forward pass.
|
||||||
|
"""
|
||||||
|
embeddings = torch.nn.functional.embedding(
|
||||||
|
input, self.weight, self.padding_idx, self.max_norm, self.norm_type, self.scale_grad_by_freq, self.sparse
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.training:
|
||||||
|
# Add noise to the embeddings
|
||||||
|
dims = torch.tensor(embeddings.size(1) * embeddings.size(2))
|
||||||
|
mag_norm = self.neftune_noise_alpha / torch.sqrt(dims)
|
||||||
|
embeddings = embeddings + torch.zeros_like(embeddings).uniform_(-mag_norm, mag_norm)
|
||||||
|
|
||||||
|
return embeddings
|
||||||
|
|
||||||
|
|
||||||
|
class FPNEFtuneTrainer(transformers.Trainer):
|
||||||
|
def __init__(self,neftune_noise_alpha:float = 0.0, model = None, *args, **kwargs):
|
||||||
|
self.neftune_noise_alpha = neftune_noise_alpha
|
||||||
|
if self.neftune_noise_alpha > 0.0:
|
||||||
|
model = self._activate_neftune(model)
|
||||||
|
super().__init__(model = model, *args, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def _activate_neftune(self, model):
|
||||||
|
r"""
|
||||||
|
Activates the neftune as presented in this code: https://github.com/neelsjain/NEFTune and paper: https://arxiv.org/abs/2310.05914
|
||||||
|
"""
|
||||||
|
print(f"Activating {RED}NEFtune{RESET} with scale: {self.neftune_noise_alpha}")
|
||||||
|
if isinstance(model, transformers.PreTrainedModel):
|
||||||
|
embeddings = model.get_input_embeddings()
|
||||||
|
elif isinstance(model, PeftModel):
|
||||||
|
embeddings = model.base_model.get_input_embeddings()
|
||||||
|
|
||||||
|
embeddings.neftune_noise_alpha = self.neftune_noise_alpha
|
||||||
|
old_forward = embeddings.forward
|
||||||
|
|
||||||
|
# This hack seems to be needed to properly use a custom forward pass
|
||||||
|
# all credits to: https://discuss.pytorch.org/t/how-can-i-replace-the-forward-method-of-a-predefined-torchvision-model-with-my-customized-forward-function/54224/11
|
||||||
|
bound_method = neftune_forward.__get__(embeddings, embeddings.__class__)
|
||||||
|
setattr(embeddings, "forward", bound_method)
|
||||||
|
|
||||||
|
# embeddings.forward = neftune_forward
|
||||||
|
embeddings._trl_old_forward = old_forward
|
||||||
|
|
||||||
|
return model
|
||||||
|
|
||||||
|
def train(self, *args, **kwargs):
|
||||||
|
output = super().train(*args, **kwargs)
|
||||||
|
|
||||||
|
# After training we make sure to retrieve back the original forward pass method
|
||||||
|
# for the embedding layer
|
||||||
|
if self.neftune_noise_alpha is not None:
|
||||||
|
|
||||||
|
if isinstance(self.model, transformers.PreTrainedModel):
|
||||||
|
embeddings = self.model.get_input_embeddings()
|
||||||
|
elif isinstance(self.model, PeftModel):
|
||||||
|
embeddings = self.model.base_model.get_input_embeddings()
|
||||||
|
|
||||||
|
if hasattr(embeddings, "_trl_old_forward"):
|
||||||
|
embeddings.forward = embeddings._trl_old_forward
|
||||||
|
del embeddings._trl_old_forward
|
||||||
|
del embeddings.neftune_noise_alpha
|
||||||
|
|
||||||
|
return output
|
||||||
|
|
||||||
|
|
||||||
|
class FPSchedulerTrainer(transformers.Trainer):
|
||||||
|
def __init__(self,neftune_noise_alpha:float = 0.0, model = None, *args, **kwargs):
|
||||||
|
self.neftune_noise_alpha = neftune_noise_alpha
|
||||||
|
if self.neftune_noise_alpha > 0.0:
|
||||||
|
model = self._activate_neftune(model)
|
||||||
|
super().__init__(model = model, *args, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def _activate_neftune(self, model):
|
||||||
|
r"""
|
||||||
|
Activates the neftune as presented in this code: https://github.com/neelsjain/NEFTune and paper: https://arxiv.org/abs/2310.05914
|
||||||
|
"""
|
||||||
|
print(f"Activating {RED}NEFtune{RESET} with scale: {self.neftune_noise_alpha}")
|
||||||
|
if isinstance(model, transformers.PreTrainedModel):
|
||||||
|
embeddings = model.get_input_embeddings()
|
||||||
|
elif isinstance(model, PeftModel):
|
||||||
|
embeddings = model.base_model.get_input_embeddings()
|
||||||
|
|
||||||
|
embeddings.neftune_noise_alpha = self.neftune_noise_alpha
|
||||||
|
old_forward = embeddings.forward
|
||||||
|
|
||||||
|
# This hack seems to be needed to properly use a custom forward pass
|
||||||
|
# all credits to: https://discuss.pytorch.org/t/how-can-i-replace-the-forward-method-of-a-predefined-torchvision-model-with-my-customized-forward-function/54224/11
|
||||||
|
bound_method = neftune_forward.__get__(embeddings, embeddings.__class__)
|
||||||
|
setattr(embeddings, "forward", bound_method)
|
||||||
|
|
||||||
|
# embeddings.forward = neftune_forward
|
||||||
|
embeddings._trl_old_forward = old_forward
|
||||||
|
|
||||||
|
return model
|
||||||
|
|
||||||
|
def train(self, *args, **kwargs):
|
||||||
|
output = super().train(*args, **kwargs)
|
||||||
|
|
||||||
|
# After training we make sure to retrieve back the original forward pass method
|
||||||
|
# for the embedding layer
|
||||||
|
if self.neftune_noise_alpha is not None:
|
||||||
|
|
||||||
|
if isinstance(self.model, transformers.PreTrainedModel):
|
||||||
|
embeddings = self.model.get_input_embeddings()
|
||||||
|
elif isinstance(self.model, PeftModel):
|
||||||
|
embeddings = self.model.base_model.get_input_embeddings()
|
||||||
|
|
||||||
|
if hasattr(embeddings, "_trl_old_forward"):
|
||||||
|
embeddings.forward = embeddings._trl_old_forward
|
||||||
|
del embeddings._trl_old_forward
|
||||||
|
del embeddings.neftune_noise_alpha
|
||||||
|
|
||||||
|
return output
|
||||||
|
|
||||||
|
|
||||||
|
def create_scheduler(self, num_training_steps: int, optimizer: torch.optim.Optimizer = None):
|
||||||
|
#Setup the scheduler. The optimizer of the trainer must have been set up either before this method is called or passed as an argument.
|
||||||
|
|
||||||
|
num_train_epochs = self.args.num_train_epochs
|
||||||
|
num_warmup_steps=self.args.get_warmup_steps(num_training_steps)
|
||||||
|
num_firstepoch_steps = math.ceil(num_training_steps/num_train_epochs)
|
||||||
|
num_warmup_acc = num_warmup_steps*self.args.gradient_accumulation_steps
|
||||||
|
num_firstepoch_steps_acc = num_firstepoch_steps*self.args.gradient_accumulation_steps
|
||||||
|
num_training_steps_acc = num_training_steps*self.args.gradient_accumulation_steps
|
||||||
|
|
||||||
|
custom_scheduler_params.update({'dynamic_scheduler_stop': False})
|
||||||
|
|
||||||
|
print (f"Warm-up steps aligned to Gradient accumulation ({self.args.gradient_accumulation_steps}) = {num_warmup_acc} actual warmup steps")
|
||||||
|
if self.args.lr_scheduler_type == 'cosine':
|
||||||
|
|
||||||
|
num_warmup_acc_min = min(num_warmup_acc, num_firstepoch_steps_acc)
|
||||||
|
|
||||||
|
if num_warmup_acc>num_firstepoch_steps_acc:
|
||||||
|
print(f"\033[1;31;1mWARNING: The number of warmup steps is set too high! It will be clamped to 1 epoch, essentially going from warmup to annealing.\033[0;37;0m")
|
||||||
|
print (f"FP Scheduler Warmup: 0-[{num_warmup_acc_min}], Hold [{num_warmup_acc_min}]-{num_firstepoch_steps_acc}, Annealing {num_firstepoch_steps_acc}-{num_training_steps_acc}")
|
||||||
|
else:
|
||||||
|
print (f"FP Scheduler Warmup: 0-{num_warmup_acc_min}, Hold {num_warmup_acc_min}-{num_firstepoch_steps_acc}, Annealing {num_firstepoch_steps_acc}-{num_training_steps_acc}")
|
||||||
|
|
||||||
|
self.lr_scheduler = custom_cosine_scheduler_with_warmup(
|
||||||
|
optimizer=self.optimizer if optimizer is None else optimizer,
|
||||||
|
num_warmup_steps=num_warmup_steps,
|
||||||
|
num_training_steps=num_training_steps,
|
||||||
|
num_firstepoch_steps = num_firstepoch_steps,
|
||||||
|
)
|
||||||
|
self._created_lr_scheduler = True
|
||||||
|
return self.lr_scheduler
|
||||||
|
elif self.args.lr_scheduler_type == 'constant':
|
||||||
|
|
||||||
|
half_step_acc = num_training_steps_acc//2
|
||||||
|
num_warmup_acc_min = min(num_warmup_acc, half_step_acc)
|
||||||
|
|
||||||
|
if num_warmup_acc>half_step_acc:
|
||||||
|
print(f"\033[1;31;1mWARNING: The number of warmup steps is set too high! It will be clamped to half of all epochs, essentially going from warmup to annealing in the middle.\033[0;37;0m")
|
||||||
|
print (f"FP Scheduler Warmup: 0-[{num_warmup_acc_min}], Hold [{num_warmup_acc_min}]-{half_step_acc}, Annealing {half_step_acc}-{num_training_steps_acc}")
|
||||||
|
else:
|
||||||
|
print (f"FP Scheduler Warmup: 0-{num_warmup_acc_min}, Hold {num_warmup_acc_min}-{half_step_acc}, Annealing {half_step_acc}-{num_training_steps_acc}")
|
||||||
|
|
||||||
|
self.lr_scheduler = custom_half_scheduler_with_warmup(
|
||||||
|
optimizer=self.optimizer if optimizer is None else optimizer,
|
||||||
|
num_warmup_steps=num_warmup_steps,
|
||||||
|
num_training_steps=num_training_steps,
|
||||||
|
num_firstepoch_steps = num_firstepoch_steps,
|
||||||
|
)
|
||||||
|
self._created_lr_scheduler = True
|
||||||
|
return self.lr_scheduler
|
||||||
|
elif self.args.lr_scheduler_type == 'constant_with_warmup':
|
||||||
|
|
||||||
|
half_step_acc = num_training_steps_acc//2
|
||||||
|
|
||||||
|
if num_warmup_steps>0:
|
||||||
|
print(f"Warmup doesn't apply to this scheduler [Raise-Fall]")
|
||||||
|
|
||||||
|
print (f"Scheduler Raise: 0-{half_step_acc}, Fall {half_step_acc}-{num_training_steps_acc}")
|
||||||
|
|
||||||
|
self.lr_scheduler = custom_raise_fall_scheduler_with_warmup(
|
||||||
|
optimizer=self.optimizer if optimizer is None else optimizer,
|
||||||
|
num_warmup_steps=num_warmup_steps,
|
||||||
|
num_training_steps=num_training_steps,
|
||||||
|
num_firstepoch_steps = num_firstepoch_steps,
|
||||||
|
)
|
||||||
|
self._created_lr_scheduler = True
|
||||||
|
return self.lr_scheduler
|
||||||
|
else:
|
||||||
|
return super().create_scheduler(num_training_steps=num_training_steps, optimizer=optimizer)
|
||||||
@ -0,0 +1,62 @@
|
|||||||
|
import os
|
||||||
|
import json
|
||||||
|
|
||||||
|
def create_graph(lora_path, lora_name):
|
||||||
|
try:
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
from matplotlib.ticker import ScalarFormatter
|
||||||
|
|
||||||
|
peft_model_path = f'{lora_path}/training_graph.json'
|
||||||
|
image_model_path = f'{lora_path}/training_graph.png'
|
||||||
|
# Check if the JSON file exists
|
||||||
|
if os.path.exists(peft_model_path):
|
||||||
|
# Load data from JSON file
|
||||||
|
with open(peft_model_path, 'r') as file:
|
||||||
|
data = json.load(file)
|
||||||
|
# Extract x, y1, and y2 values
|
||||||
|
x = [item['epoch'] for item in data]
|
||||||
|
y1 = [item['learning_rate'] for item in data]
|
||||||
|
y2 = [item['loss'] for item in data]
|
||||||
|
|
||||||
|
# Create the line chart
|
||||||
|
fig, ax1 = plt.subplots(figsize=(10, 6))
|
||||||
|
|
||||||
|
|
||||||
|
# Plot y1 (learning rate) on the first y-axis
|
||||||
|
ax1.plot(x, y1, 'b-', label='Learning Rate')
|
||||||
|
ax1.set_xlabel('Epoch')
|
||||||
|
ax1.set_ylabel('Learning Rate', color='b')
|
||||||
|
ax1.tick_params('y', colors='b')
|
||||||
|
|
||||||
|
# Create a second y-axis
|
||||||
|
ax2 = ax1.twinx()
|
||||||
|
|
||||||
|
# Plot y2 (loss) on the second y-axis
|
||||||
|
ax2.plot(x, y2, 'r-', label='Loss')
|
||||||
|
ax2.set_ylabel('Loss', color='r')
|
||||||
|
ax2.tick_params('y', colors='r')
|
||||||
|
|
||||||
|
# Set the y-axis formatter to display numbers in scientific notation
|
||||||
|
ax1.yaxis.set_major_formatter(ScalarFormatter(useMathText=True))
|
||||||
|
ax1.ticklabel_format(style='sci', axis='y', scilimits=(0,0))
|
||||||
|
|
||||||
|
# Add grid
|
||||||
|
ax1.grid(True)
|
||||||
|
|
||||||
|
# Combine the legends for both plots
|
||||||
|
lines, labels = ax1.get_legend_handles_labels()
|
||||||
|
lines2, labels2 = ax2.get_legend_handles_labels()
|
||||||
|
ax2.legend(lines + lines2, labels + labels2, loc='best')
|
||||||
|
|
||||||
|
# Set the title
|
||||||
|
plt.title(f'{lora_name} LR and Loss vs Epoch')
|
||||||
|
|
||||||
|
# Save the chart as an image
|
||||||
|
plt.savefig(image_model_path)
|
||||||
|
|
||||||
|
print(f"Graph saved in {image_model_path}")
|
||||||
|
else:
|
||||||
|
print(f"File 'training_graph.json' does not exist in the {lora_path}")
|
||||||
|
|
||||||
|
except ImportError:
|
||||||
|
print("matplotlib is not installed. Please install matplotlib to create PNG graphs")
|
||||||
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,368 @@
|
|||||||
|
import os
|
||||||
|
from modules import shared, utils
|
||||||
|
from pathlib import Path
|
||||||
|
import requests
|
||||||
|
import tqdm
|
||||||
|
import json
|
||||||
|
|
||||||
|
'''
|
||||||
|
def get_gpu_memory_usage(rank):
|
||||||
|
return {
|
||||||
|
'total': round(torch.cuda.get_device_properties(rank).total_memory / (1024**3), 2),
|
||||||
|
'max': round(torch.cuda.max_memory_allocated(rank) / (1024**3), 2),
|
||||||
|
'reserved': round(torch.cuda.memory_reserved(rank) / (1024**3), 2),
|
||||||
|
'allocated': round(torch.cuda.memory_allocated(rank) / (1024**3), 2)
|
||||||
|
}
|
||||||
|
'''
|
||||||
|
|
||||||
|
def list_subfoldersByTime(directory):
|
||||||
|
|
||||||
|
if not directory.endswith('/'):
|
||||||
|
directory += '/'
|
||||||
|
subfolders = []
|
||||||
|
subfolders.append('None')
|
||||||
|
path = directory
|
||||||
|
name_list = os.listdir(path)
|
||||||
|
full_list = [os.path.join(path,i) for i in name_list]
|
||||||
|
time_sorted_list = sorted(full_list, key=os.path.getmtime,reverse=True)
|
||||||
|
|
||||||
|
for entry in time_sorted_list:
|
||||||
|
if os.path.isdir(entry):
|
||||||
|
entry_str = f"{entry}" # Convert entry to a string
|
||||||
|
full_path = entry_str
|
||||||
|
entry_str = entry_str.replace('\\','/')
|
||||||
|
entry_str = entry_str.replace(f"{directory}", "") # Remove directory part
|
||||||
|
subfolders.append(entry_str)
|
||||||
|
|
||||||
|
return subfolders
|
||||||
|
|
||||||
|
def get_available_loras_local(_sortedByTime):
|
||||||
|
|
||||||
|
model_dir = shared.args.lora_dir # Update with the appropriate directory path
|
||||||
|
subfolders = []
|
||||||
|
if _sortedByTime:
|
||||||
|
subfolders = list_subfoldersByTime(model_dir)
|
||||||
|
else:
|
||||||
|
subfolders = utils.get_available_loras()
|
||||||
|
|
||||||
|
return subfolders
|
||||||
|
|
||||||
|
|
||||||
|
# FPHAM SPLIT BY SENTENCE BLOCK ===============
|
||||||
|
|
||||||
|
def split_sentences(text: str, cutoff_len: int):
|
||||||
|
sentences = []
|
||||||
|
sentence = ''
|
||||||
|
delimiters = ['. ', '? ', '! ', '... ', '.\n', '?\n', '!\n','...\n','</s>','<//>']
|
||||||
|
abbreviations = ['Mr. ', 'Mrs. ', 'Dr. ', 'Ms. ', 'St. ', 'Prof. ', 'Jr. ', 'Ltd. ', 'Capt. ', 'Col. ', 'Gen. ', 'Ave. ', 'Blvd. ', 'Co. ', 'Corp. ', 'Dept. ', 'Est. ', 'Gov. ', 'Inc. ', 'Ph.D. ', 'Univ. ']
|
||||||
|
errors = 0
|
||||||
|
max_cut = cutoff_len-1
|
||||||
|
prev_char = ''
|
||||||
|
|
||||||
|
for char in text:
|
||||||
|
sentence += char
|
||||||
|
|
||||||
|
|
||||||
|
if (any(sentence.endswith(delimiter) for delimiter in delimiters) and
|
||||||
|
not (prev_char.isupper() and len(sentence) >= 3 and sentence[-3] != ' ') and
|
||||||
|
not any(sentence.endswith(abbreviation) for abbreviation in abbreviations)):
|
||||||
|
tokens = shared.tokenizer.encode(sentence)
|
||||||
|
|
||||||
|
if len(tokens) > max_cut:
|
||||||
|
tokens = tokens[:max_cut]
|
||||||
|
sentence = shared.tokenizer.decode(tokens, skip_special_tokens=True)
|
||||||
|
errors = errors + 1
|
||||||
|
|
||||||
|
sentences.append({'text': sentence, 'size': len(tokens)})
|
||||||
|
|
||||||
|
sentence = ''
|
||||||
|
|
||||||
|
prev_char = char
|
||||||
|
|
||||||
|
if sentence:
|
||||||
|
tokens = shared.tokenizer.encode(sentence)
|
||||||
|
if len(tokens) > max_cut:
|
||||||
|
tokens = tokens[:max_cut]
|
||||||
|
sentence = shared.tokenizer.decode(tokens, skip_special_tokens=True)
|
||||||
|
errors = errors + 1
|
||||||
|
|
||||||
|
sentences.append({'text': sentence, 'size': len(tokens)})
|
||||||
|
|
||||||
|
if errors > 0:
|
||||||
|
print(f"Trimmed sentences beyond Cutoff Length: {errors}")
|
||||||
|
|
||||||
|
return sentences
|
||||||
|
|
||||||
|
# The goal of following code is to create blocks of text + overlapping blocks while:
|
||||||
|
# respects sentence boundaries
|
||||||
|
# always uses all the text
|
||||||
|
# hard cut defined by hard_cut_string or </s> will always end at the end of data block
|
||||||
|
# no overlapping blocks will be created across hard cut or across </s> token
|
||||||
|
|
||||||
|
def precise_cut(text: str, overlap: bool, min_chars_cut: int, eos_to_hc: bool, cutoff_len: int, hard_cut_string: str, debug_slicer:bool):
|
||||||
|
|
||||||
|
EOSX_str = '<//>' #hardcut placeholder
|
||||||
|
EOS_str = '</s>'
|
||||||
|
print("Precise raw text slicer: ON")
|
||||||
|
|
||||||
|
cut_string = hard_cut_string.replace('\\n', '\n')
|
||||||
|
text = text.replace(cut_string, EOSX_str)
|
||||||
|
sentences = split_sentences(text, cutoff_len)
|
||||||
|
|
||||||
|
print(f"Sentences: {len(sentences)}")
|
||||||
|
sentencelist = []
|
||||||
|
currentSentence = ''
|
||||||
|
totalLength = 0
|
||||||
|
max_cut = cutoff_len-1
|
||||||
|
half_cut = cutoff_len//2
|
||||||
|
halfcut_length = 0
|
||||||
|
|
||||||
|
edgeindex = []
|
||||||
|
half_index = 0
|
||||||
|
|
||||||
|
for index, item in enumerate(sentences):
|
||||||
|
|
||||||
|
if halfcut_length+ item['size'] < half_cut:
|
||||||
|
halfcut_length += item['size']
|
||||||
|
half_index = index
|
||||||
|
else:
|
||||||
|
edgeindex.append(half_index)
|
||||||
|
halfcut_length = -2 * max_cut
|
||||||
|
|
||||||
|
|
||||||
|
if totalLength + item['size'] < max_cut and not currentSentence.endswith(EOSX_str):
|
||||||
|
currentSentence += item['text']
|
||||||
|
totalLength += item['size']
|
||||||
|
else:
|
||||||
|
|
||||||
|
if len(currentSentence.strip()) > min_chars_cut:
|
||||||
|
sentencelist.append(currentSentence.strip())
|
||||||
|
|
||||||
|
currentSentence = item['text']
|
||||||
|
totalLength = item['size']
|
||||||
|
halfcut_length = item['size']
|
||||||
|
|
||||||
|
if len(currentSentence.strip()) > min_chars_cut:
|
||||||
|
sentencelist.append(currentSentence.strip())
|
||||||
|
|
||||||
|
unique_blocks = len(sentencelist)
|
||||||
|
print(f"Text Blocks: {unique_blocks}")
|
||||||
|
|
||||||
|
#overlap strategies:
|
||||||
|
# don't overlap across HARD CUT (EOSX)
|
||||||
|
if overlap:
|
||||||
|
for edge_idx in edgeindex:
|
||||||
|
currentSentence = ''
|
||||||
|
totalLength = 0
|
||||||
|
|
||||||
|
for item in sentences[edge_idx:]:
|
||||||
|
if totalLength + item['size'] < max_cut:
|
||||||
|
currentSentence += item['text']
|
||||||
|
totalLength += item['size']
|
||||||
|
else:
|
||||||
|
#if by chance EOSX is at the end then it's acceptable
|
||||||
|
if currentSentence.endswith(EOSX_str) and len(currentSentence.strip()) > min_chars_cut:
|
||||||
|
sentencelist.append(currentSentence.strip())
|
||||||
|
# otherwise don't cross hard cut
|
||||||
|
elif EOSX_str not in currentSentence and len(currentSentence.strip()) > min_chars_cut:
|
||||||
|
sentencelist.append(currentSentence.strip())
|
||||||
|
|
||||||
|
currentSentence = ''
|
||||||
|
totalLength = 0
|
||||||
|
break
|
||||||
|
|
||||||
|
print(f"+ Overlapping blocks: {len(sentencelist)-unique_blocks}")
|
||||||
|
|
||||||
|
num_EOS = 0
|
||||||
|
for i in range(len(sentencelist)):
|
||||||
|
if eos_to_hc:
|
||||||
|
sentencelist[i] = sentencelist[i].replace(EOSX_str, EOS_str)
|
||||||
|
else:
|
||||||
|
sentencelist[i] = sentencelist[i].replace(EOSX_str, '')
|
||||||
|
|
||||||
|
#someone may have had stop strings in the raw text...
|
||||||
|
sentencelist[i] = sentencelist[i].replace("</s></s>", EOS_str)
|
||||||
|
num_EOS += sentencelist[i].count(EOS_str)
|
||||||
|
|
||||||
|
if num_EOS > 0:
|
||||||
|
print(f"+ EOS count: {num_EOS}")
|
||||||
|
|
||||||
|
#final check for useless lines
|
||||||
|
sentencelist = [item for item in sentencelist if item.strip() != "</s>"]
|
||||||
|
sentencelist = [item for item in sentencelist if item.strip() != ""]
|
||||||
|
|
||||||
|
|
||||||
|
if debug_slicer:
|
||||||
|
# Write the log file
|
||||||
|
Path('logs').mkdir(exist_ok=True)
|
||||||
|
sentencelist_dict = {index: sentence for index, sentence in enumerate(sentencelist)}
|
||||||
|
output_file = "logs/sentencelist.json"
|
||||||
|
with open(output_file, 'w') as f:
|
||||||
|
json.dump(sentencelist_dict, f,indent=2)
|
||||||
|
|
||||||
|
print("Saved sentencelist.json in logs folder")
|
||||||
|
|
||||||
|
return sentencelist
|
||||||
|
|
||||||
|
|
||||||
|
def sliding_block_cut(text: str, min_chars_cut: int, eos_to_hc: bool, cutoff_len: int, hard_cut_string: str, debug_slicer:bool):
|
||||||
|
|
||||||
|
EOSX_str = '<//>' #hardcut placeholder
|
||||||
|
EOS_str = '</s>'
|
||||||
|
print("Mega Block Overlap: ON")
|
||||||
|
|
||||||
|
cut_string = hard_cut_string.replace('\\n', '\n')
|
||||||
|
text = text.replace(cut_string, EOSX_str)
|
||||||
|
sentences = split_sentences(text, cutoff_len)
|
||||||
|
|
||||||
|
print(f"Sentences: {len(sentences)}")
|
||||||
|
sentencelist = []
|
||||||
|
|
||||||
|
max_cut = cutoff_len-1
|
||||||
|
|
||||||
|
#print(f"max_cut: {max_cut}")
|
||||||
|
advancing_to = 0
|
||||||
|
|
||||||
|
prev_block_lastsentence = ""
|
||||||
|
|
||||||
|
|
||||||
|
for i in range(len(sentences)):
|
||||||
|
totalLength = 0
|
||||||
|
currentSentence = ''
|
||||||
|
lastsentence = ""
|
||||||
|
|
||||||
|
if i >= advancing_to:
|
||||||
|
for k in range(i, len(sentences)):
|
||||||
|
|
||||||
|
current_length = sentences[k]['size']
|
||||||
|
|
||||||
|
if totalLength + current_length <= max_cut and not currentSentence.endswith(EOSX_str):
|
||||||
|
currentSentence += sentences[k]['text']
|
||||||
|
totalLength += current_length
|
||||||
|
lastsentence = sentences[k]['text']
|
||||||
|
else:
|
||||||
|
if len(currentSentence.strip()) > min_chars_cut:
|
||||||
|
if prev_block_lastsentence!=lastsentence:
|
||||||
|
sentencelist.append(currentSentence.strip())
|
||||||
|
prev_block_lastsentence = lastsentence
|
||||||
|
|
||||||
|
advancing_to = 0
|
||||||
|
if currentSentence.endswith(EOSX_str):
|
||||||
|
advancing_to = k
|
||||||
|
|
||||||
|
currentSentence = ""
|
||||||
|
totalLength = 0
|
||||||
|
break
|
||||||
|
|
||||||
|
if currentSentence != "":
|
||||||
|
if len(currentSentence.strip()) > min_chars_cut:
|
||||||
|
sentencelist.append(currentSentence.strip())
|
||||||
|
|
||||||
|
unique_blocks = len(sentencelist)
|
||||||
|
print(f"Text Blocks: {unique_blocks}")
|
||||||
|
num_EOS = 0
|
||||||
|
for i in range(len(sentencelist)):
|
||||||
|
if eos_to_hc:
|
||||||
|
sentencelist[i] = sentencelist[i].replace(EOSX_str, EOS_str)
|
||||||
|
else:
|
||||||
|
sentencelist[i] = sentencelist[i].replace(EOSX_str, '')
|
||||||
|
|
||||||
|
#someone may have had stop strings in the raw text...
|
||||||
|
sentencelist[i] = sentencelist[i].replace("</s></s>", EOS_str)
|
||||||
|
num_EOS += sentencelist[i].count(EOS_str)
|
||||||
|
|
||||||
|
if num_EOS > 0:
|
||||||
|
print(f"+ EOS count: {num_EOS}")
|
||||||
|
|
||||||
|
#final check for useless lines
|
||||||
|
sentencelist = [item for item in sentencelist if item.strip() != "</s>"]
|
||||||
|
sentencelist = [item for item in sentencelist if item.strip() != ""]
|
||||||
|
|
||||||
|
|
||||||
|
if debug_slicer:
|
||||||
|
# Write the log file
|
||||||
|
Path('logs').mkdir(exist_ok=True)
|
||||||
|
sentencelist_dict = {index: sentence for index, sentence in enumerate(sentencelist)}
|
||||||
|
output_file = "logs/sentencelist.json"
|
||||||
|
with open(output_file, 'w') as f:
|
||||||
|
json.dump(sentencelist_dict, f,indent=2)
|
||||||
|
|
||||||
|
print("Saved sentencelist.json in logs folder")
|
||||||
|
|
||||||
|
return sentencelist
|
||||||
|
|
||||||
|
# Example usage:
|
||||||
|
# download_file_from_url('https://example.com/path/to/your/file.ext', '/output/directory')
|
||||||
|
|
||||||
|
def download_file_from_url(url, overwrite, output_dir_in, valid_extensions = {'.txt', '.json'}):
|
||||||
|
try:
|
||||||
|
# Validate and sanitize the URL
|
||||||
|
#parsed_url = urllib.parse.urlparse(url)
|
||||||
|
#if not parsed_url.netloc:
|
||||||
|
# raise ValueError("Invalid URL")
|
||||||
|
#filename = os.path.basename(parsed_url.path)
|
||||||
|
|
||||||
|
# Get the filename from the URL
|
||||||
|
|
||||||
|
session = requests.Session()
|
||||||
|
headers = {}
|
||||||
|
mode = 'wb'
|
||||||
|
filename = url.split('/')[-1]
|
||||||
|
|
||||||
|
output_dir = str(output_dir_in)
|
||||||
|
# Construct the full path to the output file
|
||||||
|
local_filename = os.path.join(output_dir, filename)
|
||||||
|
|
||||||
|
# Check if the local file already exists
|
||||||
|
overw = ''
|
||||||
|
if os.path.exists(local_filename):
|
||||||
|
if not overwrite:
|
||||||
|
yield f"File '{local_filename}' already exists. Aborting."
|
||||||
|
return
|
||||||
|
else:
|
||||||
|
overw = ' [Overwrite existing]'
|
||||||
|
|
||||||
|
filename_lower = filename.lower()
|
||||||
|
|
||||||
|
# Send an HTTP GET request to the URL with a timeout
|
||||||
|
file_extension = os.path.splitext(filename_lower)[-1]
|
||||||
|
|
||||||
|
if file_extension not in valid_extensions:
|
||||||
|
yield f"Invalid file extension: {file_extension}. Only {valid_extensions} files are supported."
|
||||||
|
return
|
||||||
|
|
||||||
|
with session.get(url, stream=True, headers=headers, timeout=10) as r:
|
||||||
|
r.raise_for_status()
|
||||||
|
# total size can be wildly inaccurate
|
||||||
|
#total_size = int(r.headers.get('content-length', 0))
|
||||||
|
|
||||||
|
block_size = 1024 * 4
|
||||||
|
with open(local_filename, mode) as f:
|
||||||
|
count = 0
|
||||||
|
for data in r.iter_content(block_size):
|
||||||
|
f.write(data)
|
||||||
|
count += len(data)
|
||||||
|
|
||||||
|
yield f"Downloaded: {count} " + overw
|
||||||
|
|
||||||
|
# Verify file size if possible
|
||||||
|
if os.path.exists(local_filename):
|
||||||
|
downloaded_size = os.path.getsize(local_filename)
|
||||||
|
if downloaded_size > 0:
|
||||||
|
yield f"File '{filename}' downloaded to '{output_dir}' ({downloaded_size} bytes)."
|
||||||
|
print("File Downloaded")
|
||||||
|
else:
|
||||||
|
print("Downloaded file is zero")
|
||||||
|
yield f"Failed. Downloaded file size is zero)."
|
||||||
|
else:
|
||||||
|
print(f"Error: {local_filename} failed to download.")
|
||||||
|
yield f"Error: {local_filename} failed to download"
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"An error occurred: {e}")
|
||||||
|
yield f"An error occurred: {e}"
|
||||||
|
|
||||||
|
finally:
|
||||||
|
# Close the session to release resources
|
||||||
|
session.close()
|
||||||
|
|
||||||
@ -0,0 +1,83 @@
|
|||||||
|
import os
|
||||||
|
|
||||||
|
import gradio as gr
|
||||||
|
|
||||||
|
# get the current directory of the script
|
||||||
|
current_dir = os.path.dirname(os.path.abspath(__file__))
|
||||||
|
|
||||||
|
# check if the bias_options.txt file exists, if not, create it
|
||||||
|
bias_file = os.path.join(current_dir, "bias_options.txt")
|
||||||
|
if not os.path.isfile(bias_file):
|
||||||
|
with open(bias_file, "w") as f:
|
||||||
|
f.write("*I am so happy*\n*I am so sad*\n*I am so excited*\n*I am so bored*\n*I am so angry*")
|
||||||
|
|
||||||
|
# read bias options from the text file
|
||||||
|
with open(bias_file, "r") as f:
|
||||||
|
bias_options = [line.strip() for line in f.readlines()]
|
||||||
|
|
||||||
|
params = {
|
||||||
|
"activate": True,
|
||||||
|
"bias string": " *I am so happy*",
|
||||||
|
"use custom string": False,
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def input_modifier(string):
|
||||||
|
"""
|
||||||
|
This function is applied to your text inputs before
|
||||||
|
they are fed into the model.
|
||||||
|
"""
|
||||||
|
return string
|
||||||
|
|
||||||
|
|
||||||
|
def output_modifier(string):
|
||||||
|
"""
|
||||||
|
This function is applied to the model outputs.
|
||||||
|
"""
|
||||||
|
return string
|
||||||
|
|
||||||
|
|
||||||
|
def bot_prefix_modifier(string):
|
||||||
|
"""
|
||||||
|
This function is only applied in chat mode. It modifies
|
||||||
|
the prefix text for the Bot and can be used to bias its
|
||||||
|
behavior.
|
||||||
|
"""
|
||||||
|
if params['activate']:
|
||||||
|
if params['use custom string']:
|
||||||
|
return f'{string} {params["custom string"].strip()} '
|
||||||
|
else:
|
||||||
|
return f'{string} {params["bias string"].strip()} '
|
||||||
|
else:
|
||||||
|
return string
|
||||||
|
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
# Gradio elements
|
||||||
|
activate = gr.Checkbox(value=params['activate'], label='Activate character bias')
|
||||||
|
dropdown_string = gr.Dropdown(choices=bias_options, value=params["bias string"], label='Character bias', info='To edit the options in this dropdown edit the "bias_options.txt" file')
|
||||||
|
use_custom_string = gr.Checkbox(value=False, label='Use custom bias textbox instead of dropdown')
|
||||||
|
custom_string = gr.Textbox(value="", placeholder="Enter custom bias string", label="Custom Character Bias", info='To use this textbox activate the checkbox above')
|
||||||
|
|
||||||
|
# Event functions to update the parameters in the backend
|
||||||
|
def update_bias_string(x):
|
||||||
|
if x:
|
||||||
|
params.update({"bias string": x})
|
||||||
|
else:
|
||||||
|
params.update({"bias string": dropdown_string.get()})
|
||||||
|
return x
|
||||||
|
|
||||||
|
def update_custom_string(x):
|
||||||
|
params.update({"custom string": x})
|
||||||
|
|
||||||
|
dropdown_string.change(update_bias_string, dropdown_string, None)
|
||||||
|
custom_string.change(update_custom_string, custom_string, None)
|
||||||
|
activate.change(lambda x: params.update({"activate": x}), activate, None)
|
||||||
|
use_custom_string.change(lambda x: params.update({"use custom string": x}), use_custom_string, None)
|
||||||
|
|
||||||
|
# Group elements together depending on the selected option
|
||||||
|
def bias_string_group():
|
||||||
|
if use_custom_string.value:
|
||||||
|
return gr.Group([use_custom_string, custom_string])
|
||||||
|
else:
|
||||||
|
return dropdown_string
|
||||||
@ -0,0 +1 @@
|
|||||||
|
elevenlabs==0.2.24
|
||||||
@ -0,0 +1,197 @@
|
|||||||
|
import html
|
||||||
|
import re
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import elevenlabs
|
||||||
|
import gradio as gr
|
||||||
|
|
||||||
|
from modules import chat, shared, ui_chat
|
||||||
|
from modules.logging_colors import logger
|
||||||
|
from modules.utils import gradio
|
||||||
|
|
||||||
|
params = {
|
||||||
|
'activate': True,
|
||||||
|
'api_key': None,
|
||||||
|
'selected_voice': 'None',
|
||||||
|
'autoplay': False,
|
||||||
|
'show_text': True,
|
||||||
|
'model': 'eleven_monolingual_v1',
|
||||||
|
}
|
||||||
|
|
||||||
|
voices = None
|
||||||
|
wav_idx = 0
|
||||||
|
LANG_MODELS = ['eleven_monolingual_v1', 'eleven_multilingual_v1']
|
||||||
|
|
||||||
|
|
||||||
|
def update_api_key(key):
|
||||||
|
params['api_key'] = key
|
||||||
|
if key is not None:
|
||||||
|
elevenlabs.set_api_key(key)
|
||||||
|
|
||||||
|
|
||||||
|
def refresh_voices():
|
||||||
|
global params
|
||||||
|
your_voices = elevenlabs.voices()
|
||||||
|
voice_names = [voice.name for voice in your_voices]
|
||||||
|
return voice_names
|
||||||
|
|
||||||
|
|
||||||
|
def refresh_voices_dd():
|
||||||
|
all_voices = refresh_voices()
|
||||||
|
return gr.Dropdown.update(value=all_voices[0], choices=all_voices)
|
||||||
|
|
||||||
|
|
||||||
|
def remove_tts_from_history(history):
|
||||||
|
for i, entry in enumerate(history['internal']):
|
||||||
|
history['visible'][i] = [history['visible'][i][0], entry[1]]
|
||||||
|
|
||||||
|
return history
|
||||||
|
|
||||||
|
|
||||||
|
def toggle_text_in_history(history):
|
||||||
|
for i, entry in enumerate(history['visible']):
|
||||||
|
visible_reply = entry[1]
|
||||||
|
if visible_reply.startswith('<audio'):
|
||||||
|
if params['show_text']:
|
||||||
|
reply = history['internal'][i][1]
|
||||||
|
history['visible'][i] = [history['visible'][i][0], f"{visible_reply.split('</audio>')[0]}</audio>\n\n{reply}"]
|
||||||
|
else:
|
||||||
|
history['visible'][i] = [history['visible'][i][0], f"{visible_reply.split('</audio>')[0]}</audio>"]
|
||||||
|
|
||||||
|
return history
|
||||||
|
|
||||||
|
|
||||||
|
def remove_surrounded_chars(string):
|
||||||
|
# this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
|
||||||
|
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
||||||
|
return re.sub('\*[^\*]*?(\*|$)', '', string)
|
||||||
|
|
||||||
|
|
||||||
|
def state_modifier(state):
|
||||||
|
if not params['activate']:
|
||||||
|
return state
|
||||||
|
|
||||||
|
state['stream'] = False
|
||||||
|
return state
|
||||||
|
|
||||||
|
|
||||||
|
def input_modifier(string):
|
||||||
|
if not params['activate']:
|
||||||
|
return string
|
||||||
|
|
||||||
|
shared.processing_message = "*Is recording a voice message...*"
|
||||||
|
return string
|
||||||
|
|
||||||
|
|
||||||
|
def history_modifier(history):
|
||||||
|
# Remove autoplay from the last reply
|
||||||
|
if len(history['internal']) > 0:
|
||||||
|
history['visible'][-1] = [
|
||||||
|
history['visible'][-1][0],
|
||||||
|
history['visible'][-1][1].replace('controls autoplay>', 'controls>')
|
||||||
|
]
|
||||||
|
|
||||||
|
return history
|
||||||
|
|
||||||
|
|
||||||
|
def output_modifier(string):
|
||||||
|
global params, wav_idx
|
||||||
|
|
||||||
|
if not params['activate']:
|
||||||
|
return string
|
||||||
|
|
||||||
|
original_string = string
|
||||||
|
string = remove_surrounded_chars(string)
|
||||||
|
string = string.replace('"', '')
|
||||||
|
string = string.replace('“', '')
|
||||||
|
string = string.replace('\n', ' ')
|
||||||
|
string = string.strip()
|
||||||
|
if string == '':
|
||||||
|
string = 'empty reply, try regenerating'
|
||||||
|
|
||||||
|
output_file = Path(f'extensions/elevenlabs_tts/outputs/{wav_idx:06d}.mp3'.format(wav_idx))
|
||||||
|
print(f'Outputting audio to {str(output_file)}')
|
||||||
|
try:
|
||||||
|
audio = elevenlabs.generate(text=html.unescape(string), voice=params['selected_voice'], model=params['model'])
|
||||||
|
elevenlabs.save(audio, str(output_file))
|
||||||
|
|
||||||
|
autoplay = 'autoplay' if params['autoplay'] else ''
|
||||||
|
string = f'<audio src="file/{output_file.as_posix()}" controls {autoplay}></audio>'
|
||||||
|
wav_idx += 1
|
||||||
|
except elevenlabs.api.error.UnauthenticatedRateLimitError:
|
||||||
|
string = "🤖 ElevenLabs Unauthenticated Rate Limit Reached - Please create an API key to continue\n\n"
|
||||||
|
except elevenlabs.api.error.RateLimitError:
|
||||||
|
string = "🤖 ElevenLabs API Tier Limit Reached\n\n"
|
||||||
|
except elevenlabs.api.error.APIError as err:
|
||||||
|
string = f"🤖 ElevenLabs Error: {err}\n\n"
|
||||||
|
|
||||||
|
if params['show_text']:
|
||||||
|
string += f'\n\n{original_string}'
|
||||||
|
|
||||||
|
shared.processing_message = "*Is typing...*"
|
||||||
|
return string
|
||||||
|
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
global voices
|
||||||
|
if not voices:
|
||||||
|
voices = refresh_voices()
|
||||||
|
selected = params['selected_voice']
|
||||||
|
if selected == 'None':
|
||||||
|
params['selected_voice'] = voices[0]
|
||||||
|
elif selected not in voices:
|
||||||
|
logger.error(f'Selected voice {selected} not available, switching to {voices[0]}')
|
||||||
|
params['selected_voice'] = voices[0]
|
||||||
|
|
||||||
|
# Gradio elements
|
||||||
|
with gr.Row():
|
||||||
|
activate = gr.Checkbox(value=params['activate'], label='Activate TTS')
|
||||||
|
autoplay = gr.Checkbox(value=params['autoplay'], label='Play TTS automatically')
|
||||||
|
show_text = gr.Checkbox(value=params['show_text'], label='Show message text under audio player')
|
||||||
|
|
||||||
|
with gr.Row():
|
||||||
|
voice = gr.Dropdown(value=params['selected_voice'], choices=voices, label='TTS Voice')
|
||||||
|
refresh = gr.Button(value='Refresh')
|
||||||
|
|
||||||
|
with gr.Row():
|
||||||
|
if params['api_key']:
|
||||||
|
api_key = gr.Textbox(value=params['api_key'], label='API Key')
|
||||||
|
update_api_key(params['api_key'])
|
||||||
|
else:
|
||||||
|
api_key = gr.Textbox(placeholder="Enter your API key.", label='API Key')
|
||||||
|
|
||||||
|
with gr.Row():
|
||||||
|
model = gr.Dropdown(value=params['model'], choices=LANG_MODELS, label='Language model')
|
||||||
|
|
||||||
|
with gr.Row():
|
||||||
|
convert = gr.Button('Permanently replace audios with the message texts')
|
||||||
|
convert_cancel = gr.Button('Cancel', visible=False)
|
||||||
|
convert_confirm = gr.Button('Confirm (cannot be undone)', variant="stop", visible=False)
|
||||||
|
|
||||||
|
# Convert history with confirmation
|
||||||
|
convert_arr = [convert_confirm, convert, convert_cancel]
|
||||||
|
convert.click(lambda: [gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, convert_arr)
|
||||||
|
convert_confirm.click(
|
||||||
|
lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr).then(
|
||||||
|
remove_tts_from_history, gradio('history'), gradio('history')).then(
|
||||||
|
chat.save_history, gradio('history', 'unique_id', 'character_menu', 'mode'), None).then(
|
||||||
|
chat.redraw_html, gradio(ui_chat.reload_arr), gradio('display'))
|
||||||
|
|
||||||
|
convert_cancel.click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
|
||||||
|
|
||||||
|
# Toggle message text in history
|
||||||
|
show_text.change(
|
||||||
|
lambda x: params.update({"show_text": x}), show_text, None).then(
|
||||||
|
toggle_text_in_history, gradio('history'), gradio('history')).then(
|
||||||
|
chat.save_history, gradio('history', 'unique_id', 'character_menu', 'mode'), None).then(
|
||||||
|
chat.redraw_html, gradio(ui_chat.reload_arr), gradio('display'))
|
||||||
|
|
||||||
|
# Event functions to update the parameters in the backend
|
||||||
|
activate.change(lambda x: params.update({'activate': x}), activate, None)
|
||||||
|
voice.change(lambda x: params.update({'selected_voice': x}), voice, None)
|
||||||
|
api_key.change(update_api_key, api_key, None)
|
||||||
|
model.change(lambda x: params.update({'model': x}), model, None)
|
||||||
|
# connect.click(check_valid_api, [], connection_status)
|
||||||
|
refresh.click(refresh_voices_dd, [], voice)
|
||||||
|
# Event functions to update the parameters in the backend
|
||||||
|
autoplay.change(lambda x: params.update({"autoplay": x}), autoplay, None)
|
||||||
@ -0,0 +1,139 @@
|
|||||||
|
"""
|
||||||
|
An example of extension. It does nothing, but you can add transformations
|
||||||
|
before the return statements to customize the webui behavior.
|
||||||
|
|
||||||
|
Starting from history_modifier and ending in output_modifier, the
|
||||||
|
functions are declared in the same order that they are called at
|
||||||
|
generation time.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import gradio as gr
|
||||||
|
import torch
|
||||||
|
from transformers import LogitsProcessor
|
||||||
|
|
||||||
|
from modules import chat, shared
|
||||||
|
from modules.text_generation import (
|
||||||
|
decode,
|
||||||
|
encode,
|
||||||
|
generate_reply,
|
||||||
|
)
|
||||||
|
|
||||||
|
params = {
|
||||||
|
"display_name": "Example Extension",
|
||||||
|
"is_tab": False,
|
||||||
|
}
|
||||||
|
|
||||||
|
class MyLogits(LogitsProcessor):
|
||||||
|
"""
|
||||||
|
Manipulates the probabilities for the next token before it gets sampled.
|
||||||
|
Used in the logits_processor_modifier function below.
|
||||||
|
"""
|
||||||
|
def __init__(self):
|
||||||
|
pass
|
||||||
|
|
||||||
|
def __call__(self, input_ids, scores):
|
||||||
|
# probs = torch.softmax(scores, dim=-1, dtype=torch.float)
|
||||||
|
# probs[0] /= probs[0].sum()
|
||||||
|
# scores = torch.log(probs / (1 - probs))
|
||||||
|
return scores
|
||||||
|
|
||||||
|
def history_modifier(history):
|
||||||
|
"""
|
||||||
|
Modifies the chat history.
|
||||||
|
Only used in chat mode.
|
||||||
|
"""
|
||||||
|
return history
|
||||||
|
|
||||||
|
def state_modifier(state):
|
||||||
|
"""
|
||||||
|
Modifies the state variable, which is a dictionary containing the input
|
||||||
|
values in the UI like sliders and checkboxes.
|
||||||
|
"""
|
||||||
|
return state
|
||||||
|
|
||||||
|
def chat_input_modifier(text, visible_text, state):
|
||||||
|
"""
|
||||||
|
Modifies the user input string in chat mode (visible_text).
|
||||||
|
You can also modify the internal representation of the user
|
||||||
|
input (text) to change how it will appear in the prompt.
|
||||||
|
"""
|
||||||
|
return text, visible_text
|
||||||
|
|
||||||
|
def input_modifier(string, state, is_chat=False):
|
||||||
|
"""
|
||||||
|
In default/notebook modes, modifies the whole prompt.
|
||||||
|
|
||||||
|
In chat mode, it is the same as chat_input_modifier but only applied
|
||||||
|
to "text", here called "string", and not to "visible_text".
|
||||||
|
"""
|
||||||
|
return string
|
||||||
|
|
||||||
|
def bot_prefix_modifier(string, state):
|
||||||
|
"""
|
||||||
|
Modifies the prefix for the next bot reply in chat mode.
|
||||||
|
By default, the prefix will be something like "Bot Name:".
|
||||||
|
"""
|
||||||
|
return string
|
||||||
|
|
||||||
|
def tokenizer_modifier(state, prompt, input_ids, input_embeds):
|
||||||
|
"""
|
||||||
|
Modifies the input ids and embeds.
|
||||||
|
Used by the multimodal extension to put image embeddings in the prompt.
|
||||||
|
Only used by loaders that use the transformers library for sampling.
|
||||||
|
"""
|
||||||
|
return prompt, input_ids, input_embeds
|
||||||
|
|
||||||
|
def logits_processor_modifier(processor_list, input_ids):
|
||||||
|
"""
|
||||||
|
Adds logits processors to the list, allowing you to access and modify
|
||||||
|
the next token probabilities.
|
||||||
|
Only used by loaders that use the transformers library for sampling.
|
||||||
|
"""
|
||||||
|
processor_list.append(MyLogits())
|
||||||
|
return processor_list
|
||||||
|
|
||||||
|
def output_modifier(string, state, is_chat=False):
|
||||||
|
"""
|
||||||
|
Modifies the LLM output before it gets presented.
|
||||||
|
|
||||||
|
In chat mode, the modified version goes into history['visible'],
|
||||||
|
and the original version goes into history['internal'].
|
||||||
|
"""
|
||||||
|
return string
|
||||||
|
|
||||||
|
def custom_generate_chat_prompt(user_input, state, **kwargs):
|
||||||
|
"""
|
||||||
|
Replaces the function that generates the prompt from the chat history.
|
||||||
|
Only used in chat mode.
|
||||||
|
"""
|
||||||
|
result = chat.generate_chat_prompt(user_input, state, **kwargs)
|
||||||
|
return result
|
||||||
|
|
||||||
|
def custom_css():
|
||||||
|
"""
|
||||||
|
Returns a CSS string that gets appended to the CSS for the webui.
|
||||||
|
"""
|
||||||
|
return ''
|
||||||
|
|
||||||
|
def custom_js():
|
||||||
|
"""
|
||||||
|
Returns a javascript string that gets appended to the javascript
|
||||||
|
for the webui.
|
||||||
|
"""
|
||||||
|
return ''
|
||||||
|
|
||||||
|
def setup():
|
||||||
|
"""
|
||||||
|
Gets executed only once, when the extension is imported.
|
||||||
|
"""
|
||||||
|
pass
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
"""
|
||||||
|
Gets executed when the UI is drawn. Custom gradio elements and
|
||||||
|
their corresponding event handlers should be defined here.
|
||||||
|
|
||||||
|
To learn about gradio components, check out the docs:
|
||||||
|
https://gradio.app/docs/
|
||||||
|
"""
|
||||||
|
pass
|
||||||
@ -0,0 +1,33 @@
|
|||||||
|
let gallery_element = document.getElementById('gallery-extension');
|
||||||
|
let chat_mode_element = document.getElementById('chat-mode');
|
||||||
|
|
||||||
|
let extensions_block = document.getElementById('extensions');
|
||||||
|
let extensions_block_size = extensions_block.childNodes.length;
|
||||||
|
let gallery_only = (extensions_block_size == 5);
|
||||||
|
|
||||||
|
document.querySelector('.header_bar').addEventListener('click', function(event) {
|
||||||
|
if (event.target.tagName === 'BUTTON') {
|
||||||
|
const buttonText = event.target.textContent.trim();
|
||||||
|
|
||||||
|
let chat_visible = (buttonText == 'Chat');
|
||||||
|
let default_visible = (buttonText == 'Default');
|
||||||
|
let notebook_visible = (buttonText == 'Notebook');
|
||||||
|
let chat_mode_visible = (chat_mode_element.offsetHeight > 0 && chat_mode_element.offsetWidth > 0);
|
||||||
|
|
||||||
|
// Only show this extension in the Chat tab
|
||||||
|
if (chat_visible) {
|
||||||
|
if (chat_mode_visible) {
|
||||||
|
gallery_element.style.display = 'block';
|
||||||
|
extensions_block.style.display = '';
|
||||||
|
} else {
|
||||||
|
gallery_element.style.display = 'none';
|
||||||
|
extensions_block.style.display = 'none';
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
gallery_element.style.display = 'none';
|
||||||
|
if (gallery_only) {
|
||||||
|
extensions_block.style.display = 'none';
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
});
|
||||||
@ -0,0 +1,101 @@
|
|||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import gradio as gr
|
||||||
|
|
||||||
|
from modules.html_generator import get_image_cache
|
||||||
|
from modules.shared import gradio
|
||||||
|
|
||||||
|
|
||||||
|
def generate_css():
|
||||||
|
css = """
|
||||||
|
.character-gallery > .gallery {
|
||||||
|
margin: 1rem 0;
|
||||||
|
display: grid !important;
|
||||||
|
grid-template-columns: repeat(auto-fit, minmax(150px, 1fr));
|
||||||
|
grid-column-gap: 0.4rem;
|
||||||
|
grid-row-gap: 1.2rem;
|
||||||
|
}
|
||||||
|
|
||||||
|
.character-gallery > .label {
|
||||||
|
display: none !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.character-gallery button.gallery-item {
|
||||||
|
display: contents;
|
||||||
|
}
|
||||||
|
|
||||||
|
.character-container {
|
||||||
|
cursor: pointer;
|
||||||
|
text-align: center;
|
||||||
|
position: relative;
|
||||||
|
opacity: 0.85;
|
||||||
|
}
|
||||||
|
|
||||||
|
.character-container:hover {
|
||||||
|
opacity: 1;
|
||||||
|
}
|
||||||
|
|
||||||
|
.character-container .placeholder, .character-container img {
|
||||||
|
width: 150px;
|
||||||
|
height: 200px;
|
||||||
|
background-color: gray;
|
||||||
|
object-fit: cover;
|
||||||
|
margin: 0 auto;
|
||||||
|
border-radius: 1rem;
|
||||||
|
border: 3px solid white;
|
||||||
|
box-shadow: 3px 3px 6px 0px rgb(0 0 0 / 50%);
|
||||||
|
}
|
||||||
|
|
||||||
|
.character-name {
|
||||||
|
margin-top: 0.3rem;
|
||||||
|
display: block;
|
||||||
|
font-size: 1.2rem;
|
||||||
|
font-weight: 600;
|
||||||
|
overflow-wrap: anywhere;
|
||||||
|
}
|
||||||
|
"""
|
||||||
|
return css
|
||||||
|
|
||||||
|
|
||||||
|
def generate_html():
|
||||||
|
cards = []
|
||||||
|
# Iterate through files in image folder
|
||||||
|
for file in sorted(Path("characters").glob("*")):
|
||||||
|
if file.suffix in [".json", ".yml", ".yaml"]:
|
||||||
|
character = file.stem
|
||||||
|
container_html = '<div class="character-container">'
|
||||||
|
image_html = "<div class='placeholder'></div>"
|
||||||
|
|
||||||
|
for path in [Path(f"characters/{character}.{extension}") for extension in ['png', 'jpg', 'jpeg']]:
|
||||||
|
if path.exists():
|
||||||
|
image_html = f'<img src="file/{get_image_cache(path)}">'
|
||||||
|
break
|
||||||
|
|
||||||
|
container_html += f'{image_html} <span class="character-name">{character}</span>'
|
||||||
|
container_html += "</div>"
|
||||||
|
cards.append([container_html, character])
|
||||||
|
|
||||||
|
return cards
|
||||||
|
|
||||||
|
|
||||||
|
def select_character(evt: gr.SelectData):
|
||||||
|
return (evt.value[1])
|
||||||
|
|
||||||
|
|
||||||
|
def custom_js():
|
||||||
|
path_to_js = Path(__file__).parent.resolve() / 'script.js'
|
||||||
|
return open(path_to_js, 'r').read()
|
||||||
|
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
with gr.Accordion("Character gallery", open=False, elem_id='gallery-extension'):
|
||||||
|
update = gr.Button("Refresh")
|
||||||
|
gr.HTML(value="<style>" + generate_css() + "</style>")
|
||||||
|
gallery = gr.Dataset(components=[gr.HTML(visible=False)],
|
||||||
|
label="",
|
||||||
|
samples=generate_html(),
|
||||||
|
elem_classes=["character-gallery"],
|
||||||
|
samples_per_page=50
|
||||||
|
)
|
||||||
|
update.click(generate_html, [], gallery)
|
||||||
|
gallery.select(select_character, None, gradio['character_menu'])
|
||||||
@ -0,0 +1 @@
|
|||||||
|
deep-translator==1.9.2
|
||||||
@ -0,0 +1,59 @@
|
|||||||
|
import html
|
||||||
|
|
||||||
|
import gradio as gr
|
||||||
|
from deep_translator import GoogleTranslator
|
||||||
|
|
||||||
|
params = {
|
||||||
|
"activate": True,
|
||||||
|
"language string": "ja",
|
||||||
|
}
|
||||||
|
|
||||||
|
language_codes = {'Afrikaans': 'af', 'Albanian': 'sq', 'Amharic': 'am', 'Arabic': 'ar', 'Armenian': 'hy', 'Azerbaijani': 'az', 'Basque': 'eu', 'Belarusian': 'be', 'Bengali': 'bn', 'Bosnian': 'bs', 'Bulgarian': 'bg', 'Catalan': 'ca', 'Cebuano': 'ceb', 'Chinese (Simplified)': 'zh-CN', 'Chinese (Traditional)': 'zh-TW', 'Corsican': 'co', 'Croatian': 'hr', 'Czech': 'cs', 'Danish': 'da', 'Dutch': 'nl', 'English': 'en', 'Esperanto': 'eo', 'Estonian': 'et', 'Finnish': 'fi', 'French': 'fr', 'Frisian': 'fy', 'Galician': 'gl', 'Georgian': 'ka', 'German': 'de', 'Greek': 'el', 'Gujarati': 'gu', 'Haitian Creole': 'ht', 'Hausa': 'ha', 'Hawaiian': 'haw', 'Hebrew': 'iw', 'Hindi': 'hi', 'Hmong': 'hmn', 'Hungarian': 'hu', 'Icelandic': 'is', 'Igbo': 'ig', 'Indonesian': 'id', 'Irish': 'ga', 'Italian': 'it', 'Japanese': 'ja', 'Javanese': 'jw', 'Kannada': 'kn', 'Kazakh': 'kk', 'Khmer': 'km', 'Korean': 'ko', 'Kurdish': 'ku', 'Kyrgyz': 'ky', 'Lao': 'lo', 'Latin': 'la', 'Latvian': 'lv', 'Lithuanian': 'lt', 'Luxembourgish': 'lb', 'Macedonian': 'mk', 'Malagasy': 'mg', 'Malay': 'ms', 'Malayalam': 'ml', 'Maltese': 'mt', 'Maori': 'mi', 'Marathi': 'mr', 'Mongolian': 'mn', 'Myanmar (Burmese)': 'my', 'Nepali': 'ne', 'Norwegian': 'no', 'Nyanja (Chichewa)': 'ny', 'Pashto': 'ps', 'Persian': 'fa', 'Polish': 'pl', 'Portuguese (Portugal, Brazil)': 'pt', 'Punjabi': 'pa', 'Romanian': 'ro', 'Russian': 'ru', 'Samoan': 'sm', 'Scots Gaelic': 'gd', 'Serbian': 'sr', 'Sesotho': 'st', 'Shona': 'sn', 'Sindhi': 'sd', 'Sinhala (Sinhalese)': 'si', 'Slovak': 'sk', 'Slovenian': 'sl', 'Somali': 'so', 'Spanish': 'es', 'Sundanese': 'su', 'Swahili': 'sw', 'Swedish': 'sv', 'Tagalog (Filipino)': 'tl', 'Tajik': 'tg', 'Tamil': 'ta', 'Telugu': 'te', 'Thai': 'th', 'Turkish': 'tr', 'Ukrainian': 'uk', 'Urdu': 'ur', 'Uzbek': 'uz', 'Vietnamese': 'vi', 'Welsh': 'cy', 'Xhosa': 'xh', 'Yiddish': 'yi', 'Yoruba': 'yo', 'Zulu': 'zu'}
|
||||||
|
|
||||||
|
|
||||||
|
def input_modifier(string):
|
||||||
|
"""
|
||||||
|
This function is applied to your text inputs before
|
||||||
|
they are fed into the model.
|
||||||
|
"""
|
||||||
|
if not params['activate']:
|
||||||
|
return string
|
||||||
|
|
||||||
|
return GoogleTranslator(source=params['language string'], target='en').translate(string)
|
||||||
|
|
||||||
|
|
||||||
|
def output_modifier(string):
|
||||||
|
"""
|
||||||
|
This function is applied to the model outputs.
|
||||||
|
"""
|
||||||
|
if not params['activate']:
|
||||||
|
return string
|
||||||
|
|
||||||
|
translated_str = GoogleTranslator(source='en', target=params['language string']).translate(html.unescape(string))
|
||||||
|
return html.escape(translated_str)
|
||||||
|
|
||||||
|
|
||||||
|
def bot_prefix_modifier(string):
|
||||||
|
"""
|
||||||
|
This function is only applied in chat mode. It modifies
|
||||||
|
the prefix text for the Bot and can be used to bias its
|
||||||
|
behavior.
|
||||||
|
"""
|
||||||
|
|
||||||
|
return string
|
||||||
|
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
# Finding the language name from the language code to use as the default value
|
||||||
|
language_name = list(language_codes.keys())[list(language_codes.values()).index(params['language string'])]
|
||||||
|
|
||||||
|
# Gradio elements
|
||||||
|
with gr.Row():
|
||||||
|
activate = gr.Checkbox(value=params['activate'], label='Activate translation')
|
||||||
|
|
||||||
|
with gr.Row():
|
||||||
|
language = gr.Dropdown(value=language_name, choices=[k for k in language_codes], label='Language')
|
||||||
|
|
||||||
|
# Event functions to update the parameters in the backend
|
||||||
|
activate.change(lambda x: params.update({"activate": x}), activate, None)
|
||||||
|
language.change(lambda x: params.update({"language string": language_codes[x]}), language, None)
|
||||||
@ -0,0 +1,143 @@
|
|||||||
|
import torch
|
||||||
|
from modules import chat, shared
|
||||||
|
from modules.text_generation import (
|
||||||
|
decode,
|
||||||
|
encode,
|
||||||
|
generate_reply,
|
||||||
|
)
|
||||||
|
from transformers import LogitsProcessor
|
||||||
|
import gradio as gr
|
||||||
|
|
||||||
|
params = {
|
||||||
|
"display_name": "Long replies",
|
||||||
|
"is_tab": False,
|
||||||
|
"min_length": 120,
|
||||||
|
}
|
||||||
|
|
||||||
|
initial_size = 0
|
||||||
|
|
||||||
|
class MyLogits(LogitsProcessor):
|
||||||
|
"""
|
||||||
|
Manipulates the probabilities for the next token before it gets sampled.
|
||||||
|
Used in the logits_processor_modifier function below.
|
||||||
|
"""
|
||||||
|
def __init__(self):
|
||||||
|
self.newline_id = shared.tokenizer.encode('\n')[-1]
|
||||||
|
pass
|
||||||
|
|
||||||
|
def __call__(self, input_ids, scores):
|
||||||
|
if input_ids.shape[-1] - initial_size < params["min_length"]:
|
||||||
|
scores[...,self.newline_id] = -1000
|
||||||
|
# scores[...,shared.tokenizer.eos_token_id] = -1000
|
||||||
|
|
||||||
|
# probs = torch.softmax(scores, dim=-1, dtype=torch.float)
|
||||||
|
# probs[0] /= probs[0].sum()
|
||||||
|
# scores = torch.log(probs / (1 - probs))
|
||||||
|
return scores
|
||||||
|
|
||||||
|
def history_modifier(history):
|
||||||
|
"""
|
||||||
|
Modifies the chat history.
|
||||||
|
Only used in chat mode.
|
||||||
|
"""
|
||||||
|
return history
|
||||||
|
|
||||||
|
def state_modifier(state):
|
||||||
|
"""
|
||||||
|
Modifies the state variable, which is a dictionary containing the input
|
||||||
|
values in the UI like sliders and checkboxes.
|
||||||
|
"""
|
||||||
|
return state
|
||||||
|
|
||||||
|
def chat_input_modifier(text, visible_text, state):
|
||||||
|
"""
|
||||||
|
Modifies the user input string in chat mode (visible_text).
|
||||||
|
You can also modify the internal representation of the user
|
||||||
|
input (text) to change how it will appear in the prompt.
|
||||||
|
"""
|
||||||
|
return text, visible_text
|
||||||
|
|
||||||
|
def input_modifier(string, state):
|
||||||
|
"""
|
||||||
|
In default/notebook modes, modifies the whole prompt.
|
||||||
|
|
||||||
|
In chat mode, it is the same as chat_input_modifier but only applied
|
||||||
|
to "text", here called "string", and not to "visible_text".
|
||||||
|
"""
|
||||||
|
return string
|
||||||
|
|
||||||
|
def bot_prefix_modifier(string, state):
|
||||||
|
"""
|
||||||
|
Modifies the prefix for the next bot reply in chat mode.
|
||||||
|
By default, the prefix will be something like "Bot Name:".
|
||||||
|
"""
|
||||||
|
return string
|
||||||
|
|
||||||
|
def tokenizer_modifier(state, prompt, input_ids, input_embeds):
|
||||||
|
"""
|
||||||
|
Modifies the input ids and embeds.
|
||||||
|
Used by the multimodal extension to put image embeddings in the prompt.
|
||||||
|
Only used by loaders that use the transformers library for sampling.
|
||||||
|
"""
|
||||||
|
|
||||||
|
global initial_size
|
||||||
|
initial_size = input_ids.shape[-1]
|
||||||
|
|
||||||
|
return prompt, input_ids, input_embeds
|
||||||
|
|
||||||
|
def logits_processor_modifier(processor_list, input_ids):
|
||||||
|
"""
|
||||||
|
Adds logits processors to the list, allowing you to access and modify
|
||||||
|
the next token probabilities.
|
||||||
|
Only used by loaders that use the transformers library for sampling.
|
||||||
|
"""
|
||||||
|
processor_list.append(MyLogits())
|
||||||
|
return processor_list
|
||||||
|
|
||||||
|
def output_modifier(string, state):
|
||||||
|
"""
|
||||||
|
Modifies the LLM output before it gets presented.
|
||||||
|
|
||||||
|
In chat mode, the modified version goes into history['visible'],
|
||||||
|
and the original version goes into history['internal'].
|
||||||
|
"""
|
||||||
|
return string
|
||||||
|
|
||||||
|
def custom_generate_chat_prompt(user_input, state, **kwargs):
|
||||||
|
"""
|
||||||
|
Replaces the function that generates the prompt from the chat history.
|
||||||
|
Only used in chat mode.
|
||||||
|
"""
|
||||||
|
result = chat.generate_chat_prompt(user_input, state, **kwargs)
|
||||||
|
return result
|
||||||
|
|
||||||
|
def custom_css():
|
||||||
|
"""
|
||||||
|
Returns a CSS string that gets appended to the CSS for the webui.
|
||||||
|
"""
|
||||||
|
return ''
|
||||||
|
|
||||||
|
def custom_js():
|
||||||
|
"""
|
||||||
|
Returns a javascript string that gets appended to the javascript
|
||||||
|
for the webui.
|
||||||
|
"""
|
||||||
|
return ''
|
||||||
|
|
||||||
|
def setup():
|
||||||
|
"""
|
||||||
|
Gets executed only once, when the extension is imported.
|
||||||
|
"""
|
||||||
|
pass
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
"""
|
||||||
|
Gets executed when the UI is drawn. Custom gradio elements and
|
||||||
|
their corresponding event handlers should be defined here.
|
||||||
|
|
||||||
|
To learn about gradio components, check out the docs:
|
||||||
|
https://gradio.app/docs/
|
||||||
|
"""
|
||||||
|
|
||||||
|
min_length = gr.Slider(0, 800, step=10, value=params['min_length'], label='Minimum reply length')
|
||||||
|
min_length.change(lambda x: params.update({'min_length': x}), min_length, None)
|
||||||
@ -0,0 +1,85 @@
|
|||||||
|
# Technical description of multimodal extension
|
||||||
|
|
||||||
|
## Working principle
|
||||||
|
Multimodality extension does most of the stuff which is required for any image input:
|
||||||
|
|
||||||
|
- adds the UI
|
||||||
|
- saves the images as base64 JPEGs to history
|
||||||
|
- provides the hooks to the UI
|
||||||
|
- if there are images in the prompt, it:
|
||||||
|
- splits the prompt to text and image parts
|
||||||
|
- adds image start/end markers to text parts, then encodes and embeds the text parts
|
||||||
|
- calls the vision pipeline to embed the images
|
||||||
|
- stitches the embeddings together, and returns them to text generation
|
||||||
|
- loads the appropriate vision pipeline, selected either from model name, or by specifying --multimodal-pipeline parameter
|
||||||
|
|
||||||
|
Now, for the pipelines, they:
|
||||||
|
|
||||||
|
- load the required vision models
|
||||||
|
- return some consts, for example the number of tokens taken up by image
|
||||||
|
- and most importantly: return the embeddings for LLM, given a list of images
|
||||||
|
|
||||||
|
## Prompts/history
|
||||||
|
|
||||||
|
To save images in prompt/history, this extension is using a base64 JPEG, wrapped in a HTML tag, like so:
|
||||||
|
```
|
||||||
|
<img src="data:image/jpeg;base64,{img_str}">
|
||||||
|
```
|
||||||
|
where `{img_str}` is the actual image data. This format makes displaying them in the UI for free. Do note, that this format is required to be exactly the same, the regex used to find the images is: `<img src="data:image/jpeg;base64,([A-Za-z0-9+/=]+)">`.
|
||||||
|
|
||||||
|
## LLM input
|
||||||
|
To describe the input, let's see it on an example prompt:
|
||||||
|
```
|
||||||
|
text1<image1>text2<image2>text3
|
||||||
|
```
|
||||||
|
where `textN` is N-th text, `<imageN>` is N-th image, in HTML format specified above.
|
||||||
|
|
||||||
|
**The first step is to split the prompt into image/text parts**, so we get:
|
||||||
|
```
|
||||||
|
['text1', '<image1>', 'text2', '<image2>', 'text3']
|
||||||
|
```
|
||||||
|
this is done in `MultimodalEmbedder._split_prompt(...)` function, which returns a list of `PromptPart`s - dataclasses wrapping the separate parts.
|
||||||
|
|
||||||
|
This function also appends the image start/end markers to text, which are provided by `AbstractMultimodalPipeline.image_start()` / `AbstractMultimodalPipeline.image_end()` functions. If image start is `<Img>`, and end is `</Img>`, this function will return:
|
||||||
|
```
|
||||||
|
['text1<Img>', '<image1>', '</Img>text2<Img>', '<image2>', '</Img>text3']
|
||||||
|
```
|
||||||
|
|
||||||
|
**The returned prompt parts are then turned into token embeddings.**
|
||||||
|
|
||||||
|
First, they are modified to token IDs, for the text it is done using standard `modules.text_generation.encode()` function, and for the images the returned token IDs are changed to placeholders. The placeholder is a list of `N` times `placeholder token id`, where `N` is specified using `AbstractMultimodalPipeline.num_image_embeds()`, and placeholder token IDs using `AbstractMultimodalPipeline.placeholder_token_id()`.
|
||||||
|
|
||||||
|
Now, based on the token IDs, the prompt might get truncated, especially if `max_new_tokens` are unreasonably high. Unfortunately, it can't be done simply, just by trimming the prompt to be short enough. This way will lead to sometimes splitting the prompt in the middle of an image embedding, which usually breaks the generation. Therefore, in this case, the entire image needs to be removed from input. This is done inside `MultimodalEmbedder._encode_text(...)` function.
|
||||||
|
|
||||||
|
**After the tokenization, the tokens need to get embedded**, the text and images are once again treated separately.
|
||||||
|
|
||||||
|
The text parts are turned to embeddings, using `AbstractMultimodalPipeline.embed_tokens(...)` function. It uses standard embedding function from the model, but to support many LLMs, the actual function is returned by the pipeline (as it might be different for different LLMs), for LLaMA it is `shared.model.model.embed_tokens(...)`.
|
||||||
|
|
||||||
|
The image parts are turned to embeddings, using `AbstractMultimodalPipeline.embed_images(...)` function. This function is specific for a given pipeline, it takes the images as input, forwards them through vision model/projector, and returns the embeddings.
|
||||||
|
|
||||||
|
**Now, the returned embeddings are stitched together**, using `torch.cat()`, this is creating the final input to the LLM.
|
||||||
|
|
||||||
|
## Pipelines
|
||||||
|
|
||||||
|
All of the pipelines should subclass `AbstractMultimodalPipeline` class. The idea is to allow for new pipelines to be added in the same way as user extensions - git clone into `extensions/multimodal/pipelines`.
|
||||||
|
|
||||||
|
The pipelines are the description of the vision part, containing vision model/multimodal projector. All of the pipelines should have an unique `name()`, which is then selected by user, in `--multimodal-pipeline` CLI argument. For an example, see `pipelines/llava/llava.py`.
|
||||||
|
|
||||||
|
## Pipeline modules
|
||||||
|
|
||||||
|
Pipelines are organized into "pipeline modules" - subdirectories in `pipelines` directory. The pipeline modules should contain a file called `pipelines.py`, that should contain the following fields:
|
||||||
|
- `available_pipelines: List[str]` - list of pipelines provided by this module, shown as the list of available pipelines to the user
|
||||||
|
- `def get_pipeline(name: str, params: dict) -> Optional[AbstractMultimodalPipeline]`: - a function to get a concrete pipeline by `name`, if `name` doesn't match any, should return `None`. `params` is the user settings for multimodal extension
|
||||||
|
- `def get_pipeline_from_model_name(model_name: str, params: dict) -> Optional[AbstractMultimodalPipeline]`: - a function to get a pipeline from `model_name`, should be eager to return `None`, unless the determination can be done clearly (for example: minigpt-4 bases on vicuna - it should never return the pipeline, but llava can, as it has its own specific LLM finetune)
|
||||||
|
|
||||||
|
**NOTE**: A pipeline module should lazy-import the pipelines only when necessary, and it should keep its imports to minimum
|
||||||
|
|
||||||
|
## Pipeline params
|
||||||
|
|
||||||
|
The pipelines will get the extension `params` in the constructor. They should honor the following fields:
|
||||||
|
- `vision_device` - string, specifying `torch.device` to run the vision model (CLIP/ViT) on
|
||||||
|
- `vision_bits` - int, number of fp bits to load the vision model(s) in
|
||||||
|
- `projector_device` - string, specifying `torch.device` to run the projector models (Linear layers, QFormer, etc.) on
|
||||||
|
- `projector_bits` - int, number of fp bits to load the projector models in
|
||||||
|
|
||||||
|
As a helper, `AbstractMultimodalPipeline` has `_get_device(self, setting_name: str, params: dict)` and `_get_dtype(self, setting_name: str, params: dict)` helper functions, which parse string/int and return `torch.device` / `torch.dtype`.
|
||||||
@ -0,0 +1,91 @@
|
|||||||
|
# Multimodal
|
||||||
|
|
||||||
|
## Description
|
||||||
|
|
||||||
|
Adds support for multimodality (text+images) to text-generation-webui.
|
||||||
|
|
||||||
|
Note: multimodal currently only works for transformers, AutoGPTQ, and GPTQ-for-LLaMa loaders. ExLlama (v1 and v2) and llama.cpp support are planned.
|
||||||
|
|
||||||
|
https://user-images.githubusercontent.com/3718215/233817203-69b57e77-0c55-4fd6-b742-3204bb13b8fc.mp4
|
||||||
|
|
||||||
|
## Usage
|
||||||
|
|
||||||
|
To run this extension, download a LLM that supports multimodality, and then start server.py with the appropriate `--multimodal-pipeline` argument. Examples:
|
||||||
|
|
||||||
|
```
|
||||||
|
# LLaVA 1.5 13B has the best performance
|
||||||
|
python server.py --model liuhaotian_llava-v1.5-13b --multimodal-pipeline llava-v1.5-13b --load-in-4bit
|
||||||
|
# LLaVA 1.5 7B is relatively weaker, but requires less memory
|
||||||
|
python server.py --model liuhaotian_llava-v1.5-7b --multimodal-pipeline llava-v1.5-7b --load-in-4bit
|
||||||
|
python server.py --model TheBloke_llava-v1.5-13B-GPTQ_gptq-4bit-32g-actorder_True --multimodal-pipeline llava-v1.5-13b --disable_exllama --loader autogptq
|
||||||
|
python server.py --model wojtab_llava-7b-v0-4bit-128g --multimodal-pipeline llava-7b
|
||||||
|
python server.py --model wojtab_llava-13b-v0-4bit-128g --multimodal-pipeline llava-13b
|
||||||
|
python server.py --model anon8231489123_vicuna-13b-GPTQ-4bit-128g --multimodal-pipeline minigpt4-13b
|
||||||
|
python server.py --model llama-7b-4bit --multimodal-pipeline minigpt4-7b
|
||||||
|
```
|
||||||
|
|
||||||
|
There is built-in support for LLaVA-v0-13B, LLaVA-v0-7b, and LLaVA-v1.5-13B. To install `minigpt4`:
|
||||||
|
|
||||||
|
- clone https://github.com/Wojtab/minigpt-4-pipeline into `extensions/multimodal/pipelines`
|
||||||
|
- install the requirements.txt
|
||||||
|
|
||||||
|
The same procedure should be used to install other pipelines, which can then be used with `--multimodal-pipeline [pipeline name]`. For additional multimodal pipelines refer to the compatibility section below.
|
||||||
|
|
||||||
|
Do note, that each image takes up a considerable amount of tokens, so adjust `max_new_tokens` to be at most 1700 (recommended value is between 200 to 500), so the images don't get truncated.
|
||||||
|
|
||||||
|
To send an image, just upload it to the extension field below chat, and send a prompt as always. The image will be added to the end of your message. If you wish to modify the placement, include a string `<image>` in your prompt.
|
||||||
|
|
||||||
|
Additionally, there is *Embed all images, not only the last one* checkbox. It modifies the image embeddings, by default (if it's unchecked), all but the most recent images have their embeddings empty, so they are not fed to the network. It seems as if some multimodal networks consider the features in all images at the same time as if they were a single image. Due to this behavior, by default, the extension skips previous images. However, it can lead to sub-par generation on other pipelines. If you want to include all images, just tick this checkbox.
|
||||||
|
|
||||||
|
## Compatibility
|
||||||
|
|
||||||
|
As of now, the following multimodal pipelines are supported:
|
||||||
|
|Pipeline|`--multimodal-pipeline`|Default LLM|LLM info(for the linked model)|Pipeline repository|
|
||||||
|
|-|-|-|-|-|
|
||||||
|
|[LLaVA 13B](https://github.com/haotian-liu/LLaVA)|`llava-13b`|[LLaVA 13B](https://huggingface.co/wojtab/llava-13b-v0-4bit-128g)|GPTQ 4-bit quant, old CUDA|built-in|
|
||||||
|
|[LLaVA 7B](https://github.com/haotian-liu/LLaVA)|`llava-7b`|[LLaVA 7B](https://huggingface.co/wojtab/llava-7b-v0-4bit-128g)|GPTQ 4-bit quant, old CUDA|built-in|
|
||||||
|
|[MiniGPT-4 7B](https://github.com/Vision-CAIR/MiniGPT-4)|`minigpt4-7b`|[Vicuna v0 7B](https://huggingface.co/TheBloke/vicuna-7B-GPTQ-4bit-128g)|GPTQ 4-bit quant, new format|[Wojtab/minigpt-4-pipeline](https://github.com/Wojtab/minigpt-4-pipeline)|
|
||||||
|
|[MiniGPT-4 13B](https://github.com/Vision-CAIR/MiniGPT-4)|`minigpt4-13b`|[Vicuna v0 13B](https://huggingface.co/anon8231489123/vicuna-13b-GPTQ-4bit-128g)|GPTQ 4-bit quant, old CUDA|[Wojtab/minigpt-4-pipeline](https://github.com/Wojtab/minigpt-4-pipeline)|
|
||||||
|
|[InstructBLIP 7B](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip)|`instructblip-7b`|[Vicuna v1.1 7B](https://huggingface.co/TheBloke/vicuna-7B-1.1-GPTQ-4bit-128g)|GPTQ 4-bit quant|[kjerk/instructblip-pipeline](https://github.com/kjerk/instructblip-pipeline)|
|
||||||
|
|[InstructBLIP 13B](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip)|`instructblip-13b`|[Vicuna v1.1 13B](https://huggingface.co/TheBloke/vicuna-13B-1.1-GPTQ-4bit-128g)|GPTQ 4-bit quant|[kjerk/instructblip-pipeline](https://github.com/kjerk/instructblip-pipeline)|
|
||||||
|
|
||||||
|
Some pipelines could support different LLMs but do note that while it might work, it isn't a supported configuration.
|
||||||
|
|
||||||
|
DO NOT report bugs if you are using a different LLM.
|
||||||
|
|
||||||
|
DO NOT report bugs with pipelines in this repository (unless they are built-in)
|
||||||
|
|
||||||
|
## Extension config
|
||||||
|
This extension uses the following parameters (from `settings.json`):
|
||||||
|
|Parameter|Description|
|
||||||
|
|---------|-----------|
|
||||||
|
|`multimodal-vision_bits`|Number of bits to load vision models (CLIP/ViT) feature extractor in (most pipelines should support either 32 or 16, default=32)|
|
||||||
|
|`multimodal-vision_device`|Torch device to run the feature extractor on, for example, `cpu` or `cuda:0`, by default `cuda:0` if available|
|
||||||
|
|`multimodal-projector_bits`|Number of bits to load feature projector model(s) in (most pipelines should support either 32 or 16, default=32)|
|
||||||
|
|`multimodal-projector_device`|Torch device to run the feature projector model(s) on, for example `cpu` or `cuda:0`, by default `cuda:0` if available|
|
||||||
|
|`multimodal-add_all_images_to_prompt`|Default value of "Embed all images, not only the last one" checkbox|
|
||||||
|
|
||||||
|
## Usage through API
|
||||||
|
|
||||||
|
You can run the multimodal inference through API, by inputting the images to prompt. Images are embedded like so: `f'<img src="data:image/jpeg;base64,{img_str}">'`, where `img_str` is base-64 jpeg data. Note that you will need to launch `server.py` with the arguments `--api --extensions multimodal`.
|
||||||
|
|
||||||
|
Python example:
|
||||||
|
|
||||||
|
```Python
|
||||||
|
import base64
|
||||||
|
import requests
|
||||||
|
|
||||||
|
CONTEXT = "You are LLaVA, a large language and vision assistant trained by UW Madison WAIV Lab. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language. Follow the instructions carefully and explain your answers in detail.### Human: Hi!### Assistant: Hi there! How can I help you today?\n"
|
||||||
|
|
||||||
|
with open('extreme_ironing.jpg', 'rb') as f:
|
||||||
|
img_str = base64.b64encode(f.read()).decode('utf-8')
|
||||||
|
prompt = CONTEXT + f'### Human: What is unusual about this image: \n<img src="data:image/jpeg;base64,{img_str}">### Assistant: '
|
||||||
|
print(requests.post('http://127.0.0.1:5000/api/v1/generate', json={'prompt': prompt, 'stopping_strings': ['\n###']}).json())
|
||||||
|
```
|
||||||
|
script output:
|
||||||
|
```Python
|
||||||
|
{'results': [{'text': "The unusual aspect of this image is that a man is standing on top of a yellow minivan while doing his laundry. He has set up a makeshift clothes line using the car's rooftop as an outdoor drying area. This scene is uncommon because people typically do their laundry indoors, in a dedicated space like a laundromat or a room in their home, rather than on top of a moving vehicle. Additionally, hanging clothes on the car could be potentially hazardous or illegal in some jurisdictions due to the risk of damaging the vehicle or causing accidents on the road.\n##"}]}
|
||||||
|
```
|
||||||
|
|
||||||
|
## For pipeline developers/technical description
|
||||||
|
see [DOCS.md](https://github.com/oobabooga/text-generation-webui/blob/main/extensions/multimodal/DOCS.md)
|
||||||
@ -0,0 +1,63 @@
|
|||||||
|
from abc import ABC, abstractmethod
|
||||||
|
from typing import List, Optional
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from PIL import Image
|
||||||
|
from transformers import is_torch_xpu_available
|
||||||
|
|
||||||
|
|
||||||
|
class AbstractMultimodalPipeline(ABC):
|
||||||
|
@staticmethod
|
||||||
|
@abstractmethod
|
||||||
|
def name() -> str:
|
||||||
|
'name of the pipeline, should be same as in --multimodal-pipeline'
|
||||||
|
pass
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
@abstractmethod
|
||||||
|
def image_start() -> Optional[str]:
|
||||||
|
'return image start string, string representation of image start token, or None if not applicable'
|
||||||
|
pass
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
@abstractmethod
|
||||||
|
def image_end() -> Optional[str]:
|
||||||
|
'return image end string, string representation of image end token, or None if not applicable'
|
||||||
|
pass
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
@abstractmethod
|
||||||
|
def placeholder_token_id() -> int:
|
||||||
|
'return placeholder token id'
|
||||||
|
pass
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
@abstractmethod
|
||||||
|
def num_image_embeds() -> int:
|
||||||
|
'return the number of embeds used by a single image (for example: 256 for LLaVA)'
|
||||||
|
pass
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def embed_images(self, images: List[Image.Image]) -> torch.Tensor:
|
||||||
|
'forward the images through vision pipeline, and return their embeddings'
|
||||||
|
pass
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
@abstractmethod
|
||||||
|
def embed_tokens(input_ids: torch.Tensor) -> torch.Tensor:
|
||||||
|
'embed tokens, the exact function varies by LLM, for LLaMA it is `shared.model.model.embed_tokens`'
|
||||||
|
pass
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
@abstractmethod
|
||||||
|
def placeholder_embeddings() -> torch.Tensor:
|
||||||
|
'get placeholder embeddings if there are multiple images, and `add_all_images_to_prompt` is False'
|
||||||
|
pass
|
||||||
|
|
||||||
|
def _get_device(self, setting_name: str, params: dict):
|
||||||
|
if params[setting_name] is None:
|
||||||
|
return torch.device("cuda:0" if torch.cuda.is_available() else "xpu:0" if is_torch_xpu_available() else "cpu")
|
||||||
|
return torch.device(params[setting_name])
|
||||||
|
|
||||||
|
def _get_dtype(self, setting_name: str, params: dict):
|
||||||
|
return torch.float32 if int(params[setting_name]) == 32 else torch.float16
|
||||||
@ -0,0 +1,178 @@
|
|||||||
|
import base64
|
||||||
|
import re
|
||||||
|
from dataclasses import dataclass
|
||||||
|
from io import BytesIO
|
||||||
|
from typing import Any, List, Optional
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
|
from extensions.multimodal.pipeline_loader import load_pipeline
|
||||||
|
from modules import shared
|
||||||
|
from modules.logging_colors import logger
|
||||||
|
from modules.text_generation import encode, get_max_prompt_length
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class PromptPart:
|
||||||
|
text: str
|
||||||
|
image: Optional[Image.Image] = None
|
||||||
|
is_image: bool = False
|
||||||
|
input_ids: Optional[torch.Tensor] = None
|
||||||
|
embedding: Optional[torch.Tensor] = None
|
||||||
|
|
||||||
|
|
||||||
|
class MultimodalEmbedder:
|
||||||
|
def __init__(self, params: dict):
|
||||||
|
pipeline, source = load_pipeline(params)
|
||||||
|
self.pipeline = pipeline
|
||||||
|
logger.info(f'Multimodal: loaded pipeline {self.pipeline.name()} from pipelines/{source} ({self.pipeline.__class__.__name__})')
|
||||||
|
|
||||||
|
def _split_prompt(self, prompt: str, load_images: bool = False) -> List[PromptPart]:
|
||||||
|
"""Splits a prompt into a list of `PromptParts` to separate image data from text.
|
||||||
|
It will also append `image_start` and `image_end` before and after the image, and optionally parse and load the images,
|
||||||
|
if `load_images` is `True`.
|
||||||
|
"""
|
||||||
|
parts: List[PromptPart] = []
|
||||||
|
curr = 0
|
||||||
|
while True:
|
||||||
|
match = re.search(r'<img src="data:image/jpeg;base64,([A-Za-z0-9+/=]+)">', prompt[curr:])
|
||||||
|
if match is None:
|
||||||
|
# no more image tokens, append the rest of the prompt
|
||||||
|
if curr > 0:
|
||||||
|
# add image end token after last image
|
||||||
|
parts.append(PromptPart(text=self.pipeline.image_end() + prompt[curr:]))
|
||||||
|
else:
|
||||||
|
parts.append(PromptPart(text=prompt))
|
||||||
|
break
|
||||||
|
# found an image, append image start token to the text
|
||||||
|
if match.start() > 0:
|
||||||
|
parts.append(PromptPart(text=prompt[curr:curr + match.start()] + self.pipeline.image_start()))
|
||||||
|
else:
|
||||||
|
parts.append(PromptPart(text=self.pipeline.image_start()))
|
||||||
|
# append the image
|
||||||
|
parts.append(PromptPart(
|
||||||
|
text=match.group(0),
|
||||||
|
image=Image.open(BytesIO(base64.b64decode(match.group(1)))) if load_images else None,
|
||||||
|
is_image=True
|
||||||
|
))
|
||||||
|
curr += match.end()
|
||||||
|
return parts
|
||||||
|
|
||||||
|
def _len_in_tokens_prompt_parts(self, parts: List[PromptPart]) -> int:
|
||||||
|
"""Total length in tokens of all `parts`"""
|
||||||
|
tokens = 0
|
||||||
|
for part in parts:
|
||||||
|
if part.is_image:
|
||||||
|
tokens += self.pipeline.num_image_embeds()
|
||||||
|
elif part.input_ids is not None:
|
||||||
|
tokens += len(part.input_ids)
|
||||||
|
else:
|
||||||
|
tokens += len(encode(part.text)[0])
|
||||||
|
return tokens
|
||||||
|
|
||||||
|
def len_in_tokens(self, prompt: str) -> int:
|
||||||
|
"""Total length in tokens for a given text `prompt`"""
|
||||||
|
parts = self._split_prompt(prompt, False)
|
||||||
|
return self._len_in_tokens_prompt_parts(parts)
|
||||||
|
|
||||||
|
def _encode_single_text(self, part: PromptPart, add_bos_token: bool) -> PromptPart:
|
||||||
|
"""Encode a single prompt `part` to `input_ids`. Returns a `PromptPart`"""
|
||||||
|
if part.is_image:
|
||||||
|
placeholders = torch.ones((self.pipeline.num_image_embeds())) * self.pipeline.placeholder_token_id()
|
||||||
|
part.input_ids = placeholders.to(shared.model.device, dtype=torch.int64)
|
||||||
|
else:
|
||||||
|
part.input_ids = encode(part.text, add_bos_token=add_bos_token)[0].to(shared.model.device, dtype=torch.int64)
|
||||||
|
return part
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _num_images(parts: List[PromptPart]) -> int:
|
||||||
|
count = 0
|
||||||
|
for part in parts:
|
||||||
|
if part.is_image:
|
||||||
|
count += 1
|
||||||
|
return count
|
||||||
|
|
||||||
|
def _encode_text(self, state, parts: List[PromptPart]) -> List[PromptPart]:
|
||||||
|
"""Encode text to token_ids, also truncate the prompt, if necessary.
|
||||||
|
|
||||||
|
The chat/instruct mode should make prompts that fit in get_max_prompt_length, but if max_new_tokens are set
|
||||||
|
such that the context + min_rows don't fit, we can get a prompt which is too long.
|
||||||
|
We can't truncate image embeddings, as it leads to broken generation, so remove the images instead and warn the user
|
||||||
|
"""
|
||||||
|
encoded: List[PromptPart] = []
|
||||||
|
for i, part in enumerate(parts):
|
||||||
|
encoded.append(self._encode_single_text(part, i == 0 and state['add_bos_token']))
|
||||||
|
|
||||||
|
# truncation:
|
||||||
|
max_len = get_max_prompt_length(state)
|
||||||
|
removed_images = 0
|
||||||
|
|
||||||
|
# 1. remove entire text/image blocks
|
||||||
|
while self._len_in_tokens_prompt_parts(encoded[1:]) > max_len:
|
||||||
|
if encoded[0].is_image:
|
||||||
|
removed_images += 1
|
||||||
|
encoded = encoded[1:]
|
||||||
|
|
||||||
|
# 2. check if the last prompt part doesn't need to get truncated
|
||||||
|
if self._len_in_tokens_prompt_parts(encoded) > max_len:
|
||||||
|
if encoded[0].is_image:
|
||||||
|
# don't truncate image embeddings, just remove the image, otherwise generation will be broken
|
||||||
|
removed_images += 1
|
||||||
|
encoded = encoded[1:]
|
||||||
|
elif len(encoded) > 1 and encoded[0].text.endswith(self.pipeline.image_start()):
|
||||||
|
# see if we can keep image_start token
|
||||||
|
len_image_start = len(encode(self.pipeline.image_start(), add_bos_token=state['add_bos_token'])[0])
|
||||||
|
if self._len_in_tokens_prompt_parts(encoded[1:]) + len_image_start > max_len:
|
||||||
|
# we can't -> remove this text, and the image
|
||||||
|
encoded = encoded[2:]
|
||||||
|
removed_images += 1
|
||||||
|
else:
|
||||||
|
# we can -> just truncate the text
|
||||||
|
trunc_len = self._len_in_tokens_prompt_parts(encoded) - max_len
|
||||||
|
encoded[0].input_ids = encoded[0].input_ids[trunc_len:]
|
||||||
|
elif len(encoded) > 0:
|
||||||
|
# only one text left, truncate it normally
|
||||||
|
trunc_len = self._len_in_tokens_prompt_parts(encoded) - max_len
|
||||||
|
encoded[0].input_ids = encoded[0].input_ids[trunc_len:]
|
||||||
|
|
||||||
|
# notify user if we truncated an image
|
||||||
|
if removed_images > 0:
|
||||||
|
logger.warning(f"Multimodal: removed {removed_images} image(s) from prompt. Try decreasing max_new_tokens if generation is broken")
|
||||||
|
|
||||||
|
return encoded
|
||||||
|
|
||||||
|
def _embed(self, parts: List[PromptPart]) -> List[PromptPart]:
|
||||||
|
# batch images
|
||||||
|
image_indicies = [i for i, part in enumerate(parts) if part.is_image]
|
||||||
|
embedded = self.pipeline.embed_images([parts[i].image for i in image_indicies])
|
||||||
|
for i, embeds in zip(image_indicies, embedded):
|
||||||
|
parts[i].embedding = embeds
|
||||||
|
# embed text
|
||||||
|
for (i, part) in enumerate(parts):
|
||||||
|
if not part.is_image:
|
||||||
|
parts[i].embedding = self.pipeline.embed_tokens(part.input_ids)
|
||||||
|
return parts
|
||||||
|
|
||||||
|
def _remove_old_images(self, parts: List[PromptPart], params: dict) -> List[PromptPart]:
|
||||||
|
if params['add_all_images_to_prompt']:
|
||||||
|
return parts
|
||||||
|
already_added = False
|
||||||
|
for i, part in reversed(list(enumerate(parts))):
|
||||||
|
if part.is_image:
|
||||||
|
if already_added:
|
||||||
|
parts[i].embedding = self.pipeline.placeholder_embeddings()
|
||||||
|
else:
|
||||||
|
already_added = True
|
||||||
|
return parts
|
||||||
|
|
||||||
|
def forward(self, prompt: str, state: Any, params: dict):
|
||||||
|
prompt_parts = self._split_prompt(prompt, True)
|
||||||
|
prompt_parts = self._encode_text(state, prompt_parts)
|
||||||
|
prompt_parts = self._embed(prompt_parts)
|
||||||
|
prompt_parts = self._remove_old_images(prompt_parts, params)
|
||||||
|
embeds = tuple(part.embedding for part in prompt_parts)
|
||||||
|
ids = tuple(part.input_ids for part in prompt_parts)
|
||||||
|
input_embeds = torch.cat(embeds, dim=0)
|
||||||
|
input_ids = torch.cat(ids, dim=0)
|
||||||
|
return prompt, input_ids, input_embeds, self._num_images(prompt_parts)
|
||||||
@ -0,0 +1,52 @@
|
|||||||
|
import traceback
|
||||||
|
from importlib import import_module
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import Tuple
|
||||||
|
|
||||||
|
from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
|
||||||
|
from modules import shared
|
||||||
|
from modules.logging_colors import logger
|
||||||
|
|
||||||
|
|
||||||
|
def _get_available_pipeline_modules():
|
||||||
|
pipeline_path = Path(__file__).parent / 'pipelines'
|
||||||
|
modules = [p for p in pipeline_path.iterdir() if p.is_dir()]
|
||||||
|
return [m.name for m in modules if (m / 'pipelines.py').exists()]
|
||||||
|
|
||||||
|
|
||||||
|
def load_pipeline(params: dict) -> Tuple[AbstractMultimodalPipeline, str]:
|
||||||
|
pipeline_modules = {}
|
||||||
|
available_pipeline_modules = _get_available_pipeline_modules()
|
||||||
|
for name in available_pipeline_modules:
|
||||||
|
try:
|
||||||
|
pipeline_modules[name] = import_module(f'extensions.multimodal.pipelines.{name}.pipelines')
|
||||||
|
except:
|
||||||
|
logger.warning(f'Failed to get multimodal pipelines from {name}')
|
||||||
|
logger.warning(traceback.format_exc())
|
||||||
|
|
||||||
|
if shared.args.multimodal_pipeline is not None:
|
||||||
|
for k in pipeline_modules:
|
||||||
|
if hasattr(pipeline_modules[k], 'get_pipeline'):
|
||||||
|
pipeline = getattr(pipeline_modules[k], 'get_pipeline')(shared.args.multimodal_pipeline, params)
|
||||||
|
if pipeline is not None:
|
||||||
|
return (pipeline, k)
|
||||||
|
else:
|
||||||
|
model_name = shared.args.model.lower()
|
||||||
|
for k in pipeline_modules:
|
||||||
|
if hasattr(pipeline_modules[k], 'get_pipeline_from_model_name'):
|
||||||
|
pipeline = getattr(pipeline_modules[k], 'get_pipeline_from_model_name')(model_name, params)
|
||||||
|
if pipeline is not None:
|
||||||
|
return (pipeline, k)
|
||||||
|
|
||||||
|
available = []
|
||||||
|
for k in pipeline_modules:
|
||||||
|
if hasattr(pipeline_modules[k], 'available_pipelines'):
|
||||||
|
pipelines = getattr(pipeline_modules[k], 'available_pipelines')
|
||||||
|
available += pipelines
|
||||||
|
|
||||||
|
if shared.args.multimodal_pipeline is not None:
|
||||||
|
log = f'Multimodal - ERROR: Failed to load multimodal pipeline "{shared.args.multimodal_pipeline}", available pipelines are: {available}.'
|
||||||
|
else:
|
||||||
|
log = f'Multimodal - ERROR: Failed to determine multimodal pipeline for model {shared.args.model}, please select one manually using --multimodal-pipeline [PIPELINE]. Available pipelines are: {available}.'
|
||||||
|
logger.critical(f'{log} Please specify a correct pipeline, or disable the extension')
|
||||||
|
raise RuntimeError(f'{log} Please specify a correct pipeline, or disable the extension')
|
||||||
@ -0,0 +1,9 @@
|
|||||||
|
## LLaVA pipeline
|
||||||
|
|
||||||
|
This module provides 2 pipelines:
|
||||||
|
- `llava-7b` - for use with LLaVA v0 7B model (finetuned LLaMa 7B)
|
||||||
|
- `llava-13b` - for use with LLaVA v0 13B model (finetuned LLaMa 13B)
|
||||||
|
|
||||||
|
[LLaVA](https://github.com/haotian-liu/LLaVA) uses CLIP `openai/clip-vit-large-patch14` as the vision model, and then a single linear layer. For 13B the projector weights are in `liuhaotian/LLaVA-13b-delta-v0`, and for 7B they are in `liuhaotian/LLaVA-7b-delta-v0`.
|
||||||
|
|
||||||
|
The supported parameter combinations for both the vision model, and the projector are: CUDA/32bit, CUDA/16bit, CPU/32bit
|
||||||
@ -0,0 +1,262 @@
|
|||||||
|
import time
|
||||||
|
from abc import abstractmethod
|
||||||
|
from typing import List, Tuple
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from huggingface_hub import hf_hub_download
|
||||||
|
from PIL import Image
|
||||||
|
from transformers import CLIPImageProcessor, CLIPVisionModel
|
||||||
|
|
||||||
|
from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
|
||||||
|
from modules import shared
|
||||||
|
from modules.logging_colors import logger
|
||||||
|
from modules.text_generation import encode
|
||||||
|
|
||||||
|
|
||||||
|
def expand2square(pil_img: Image.Image, background_color: Tuple[int]) -> Image.Image:
|
||||||
|
width, height = pil_img.size
|
||||||
|
if width == height:
|
||||||
|
return pil_img
|
||||||
|
elif width > height:
|
||||||
|
result = Image.new(pil_img.mode, (width, width), background_color)
|
||||||
|
result.paste(pil_img, (0, (width - height) // 2))
|
||||||
|
return result
|
||||||
|
else:
|
||||||
|
result = Image.new(pil_img.mode, (height, height), background_color)
|
||||||
|
result.paste(pil_img, ((height - width) // 2, 0))
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
class LLaVA_v0_Pipeline(AbstractMultimodalPipeline):
|
||||||
|
CLIP_REPO = "openai/clip-vit-large-patch14"
|
||||||
|
|
||||||
|
def __init__(self, params: dict) -> None:
|
||||||
|
super().__init__()
|
||||||
|
self.clip_device = self._get_device("vision_device", params)
|
||||||
|
self.clip_dtype = self._get_dtype("vision_bits", params)
|
||||||
|
self.projector_device = self._get_device("projector_device", params)
|
||||||
|
self.projector_dtype = self._get_dtype("projector_bits", params)
|
||||||
|
self.image_processor, self.vision_tower, self.mm_projector = self._load_models()
|
||||||
|
|
||||||
|
def _load_models(self):
|
||||||
|
start_ts = time.time()
|
||||||
|
|
||||||
|
logger.info(f"LLaVA - Loading CLIP from {self.CLIP_REPO} as {self.clip_dtype} on {self.clip_device}...")
|
||||||
|
image_processor = CLIPImageProcessor.from_pretrained(self.CLIP_REPO, torch_dtype=self.clip_dtype)
|
||||||
|
vision_tower = CLIPVisionModel.from_pretrained(self.CLIP_REPO, torch_dtype=self.clip_dtype).to(self.clip_device)
|
||||||
|
|
||||||
|
logger.info(f"LLaVA - Loading projector from {self.llava_projector_repo()} as {self.projector_dtype} on {self.projector_device}...")
|
||||||
|
projector_path = hf_hub_download(self.llava_projector_repo(), self.llava_projector_filename())
|
||||||
|
mm_projector = self.build_mm_projector()
|
||||||
|
projector_data = torch.load(projector_path)
|
||||||
|
projector_data = {k[19:]: v for k, v in projector_data.items() if k.startswith('model.mm_projector.')}
|
||||||
|
mm_projector.load_state_dict(projector_data)
|
||||||
|
mm_projector = mm_projector.to(self.projector_device)
|
||||||
|
|
||||||
|
logger.info(f"LLaVA supporting models loaded, took {time.time() - start_ts:.2f} seconds")
|
||||||
|
return image_processor, vision_tower, mm_projector
|
||||||
|
|
||||||
|
def build_mm_projector(self) -> torch.nn.Module:
|
||||||
|
projector_shape = self.llava_projector_shape()
|
||||||
|
if len(projector_shape) == 2:
|
||||||
|
return torch.nn.Linear(*projector_shape)
|
||||||
|
else:
|
||||||
|
modules = []
|
||||||
|
modules.append(torch.nn.Linear(projector_shape[0], projector_shape[1]))
|
||||||
|
for i in range(2, len(projector_shape)):
|
||||||
|
modules.append(torch.nn.GELU())
|
||||||
|
modules.append(torch.nn.Linear(projector_shape[i-1], projector_shape[i]))
|
||||||
|
return torch.nn.Sequential(*modules)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def image_start() -> str:
|
||||||
|
return "<im_start>"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def image_end() -> str:
|
||||||
|
return "<im_end>"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def num_image_embeds() -> int:
|
||||||
|
return 256
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def embed_tokens(input_ids: torch.Tensor) -> torch.Tensor:
|
||||||
|
for attr in ['', 'model', 'model.model', 'model.model.model']:
|
||||||
|
tmp = getattr(shared.model, attr, None) if attr != '' else shared.model
|
||||||
|
if tmp is not None and hasattr(tmp, 'embed_tokens'):
|
||||||
|
func = tmp.embed_tokens
|
||||||
|
break
|
||||||
|
else:
|
||||||
|
raise ValueError('The embed_tokens method has not been found for this loader.')
|
||||||
|
|
||||||
|
return func(input_ids).to(shared.model.device, dtype=shared.model.dtype)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def placeholder_embeddings() -> torch.Tensor:
|
||||||
|
return LLaVA_v0_Pipeline.embed_tokens(encode("<im_patch>"*256, add_bos_token=False)[0])
|
||||||
|
|
||||||
|
def embed_images(self, images: List[Image.Image]) -> torch.Tensor:
|
||||||
|
images = self.image_processor(images, return_tensors='pt')['pixel_values']
|
||||||
|
images = images.to(self.clip_device, dtype=self.clip_dtype)
|
||||||
|
|
||||||
|
with torch.no_grad():
|
||||||
|
image_forward_outs = self.vision_tower(images, output_hidden_states=True)
|
||||||
|
select_hidden_state_layer = -2
|
||||||
|
select_hidden_state = image_forward_outs.hidden_states[select_hidden_state_layer]
|
||||||
|
image_features = select_hidden_state[:, 1:].to(self.projector_device, dtype=self.projector_dtype)
|
||||||
|
image_features = self.mm_projector(image_features)
|
||||||
|
return image_features.to(shared.model.device, dtype=shared.model.dtype)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
@abstractmethod
|
||||||
|
def llava_projector_repo() -> str:
|
||||||
|
pass
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
@abstractmethod
|
||||||
|
def llava_projector_filename() -> str:
|
||||||
|
pass
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
@abstractmethod
|
||||||
|
def llava_projector_shape() -> Tuple[int, int]:
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class LLaVA_v0_13B_Pipeline(LLaVA_v0_Pipeline):
|
||||||
|
def __init__(self, params: dict) -> None:
|
||||||
|
super().__init__(params)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def name() -> str:
|
||||||
|
return "llava-13b"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def placeholder_token_id() -> int:
|
||||||
|
return 32000
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_shape() -> Tuple[int, int]:
|
||||||
|
return (1024, 5120)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_filename() -> str:
|
||||||
|
return "mm_projector.bin"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_repo() -> str:
|
||||||
|
return "liuhaotian/LLaVA-13b-delta-v0"
|
||||||
|
|
||||||
|
|
||||||
|
class LLaVA_v0_7B_Pipeline(LLaVA_v0_Pipeline):
|
||||||
|
def __init__(self, params: dict) -> None:
|
||||||
|
super().__init__(params)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def name() -> str:
|
||||||
|
return "llava-7b"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def placeholder_token_id() -> int:
|
||||||
|
return 32001
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_shape() -> Tuple[int, int]:
|
||||||
|
return (1024, 4096)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_filename() -> str:
|
||||||
|
return "mm_projector.bin"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_repo() -> str:
|
||||||
|
return "liuhaotian/LLaVA-7b-delta-v0"
|
||||||
|
|
||||||
|
|
||||||
|
class LLaVA_LLaMA_2_13B_Pipeline(LLaVA_v0_13B_Pipeline):
|
||||||
|
def __init__(self, params: dict) -> None:
|
||||||
|
super().__init__(params)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def name() -> str:
|
||||||
|
return "llava-llama-2-13b"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def placeholder_token_id() -> int:
|
||||||
|
return 0
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_repo() -> str:
|
||||||
|
return "liuhaotian/llava-llama-2-13b-chat-lightning-preview"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def image_start() -> str:
|
||||||
|
return ""
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def image_end() -> str:
|
||||||
|
return ""
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def placeholder_embeddings() -> torch.Tensor:
|
||||||
|
return LLaVA_v0_Pipeline.embed_tokens(encode("<unk>"*256, add_bos_token=False)[0])
|
||||||
|
|
||||||
|
|
||||||
|
class LLaVA_v1_5_13B_Pipeline(LLaVA_v0_13B_Pipeline):
|
||||||
|
CLIP_REPO = "openai/clip-vit-large-patch14-336"
|
||||||
|
|
||||||
|
def __init__(self, params: dict) -> None:
|
||||||
|
super().__init__(params)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def name() -> str:
|
||||||
|
return "llava-v1.5-13b"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_shape() -> Tuple[int, int]:
|
||||||
|
return (1024, 5120, 5120)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def placeholder_token_id() -> int:
|
||||||
|
return 0
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_repo() -> str:
|
||||||
|
return "liuhaotian/llava-v1.5-13b"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def image_start() -> str:
|
||||||
|
return ""
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def image_end() -> str:
|
||||||
|
return ""
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def num_image_embeds() -> int:
|
||||||
|
return 576
|
||||||
|
|
||||||
|
def embed_images(self, images: List[Image.Image]) -> torch.Tensor:
|
||||||
|
# pad it to square first
|
||||||
|
images = [
|
||||||
|
expand2square(image, tuple(int(x*255) for x in self.image_processor.image_mean))
|
||||||
|
for image in images
|
||||||
|
]
|
||||||
|
return super().embed_images(images)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def placeholder_embeddings() -> torch.Tensor:
|
||||||
|
return LLaVA_v0_Pipeline.embed_tokens(encode("<unk>"*576, add_bos_token=False)[0])
|
||||||
|
|
||||||
|
class LLaVA_v1_5_7B_Pipeline(LLaVA_v1_5_13B_Pipeline):
|
||||||
|
@staticmethod
|
||||||
|
def name() -> str:
|
||||||
|
return "llava-v1.5-7b"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_shape() -> Tuple[int, int]:
|
||||||
|
return (1024, 4096, 4096)
|
||||||
|
@staticmethod
|
||||||
|
def llava_projector_repo() -> str:
|
||||||
|
return "liuhaotian/llava-v1.5-7b"
|
||||||
@ -0,0 +1,48 @@
|
|||||||
|
from typing import Optional
|
||||||
|
|
||||||
|
from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
|
||||||
|
|
||||||
|
available_pipelines = ['llava-7b', 'llava-13b', 'llava-llama-2-13b', 'llava-v1.5-13b', 'llava-v1.5-7b']
|
||||||
|
|
||||||
|
|
||||||
|
def get_pipeline(name: str, params: dict) -> Optional[AbstractMultimodalPipeline]:
|
||||||
|
if name == 'llava-7b':
|
||||||
|
from .llava import LLaVA_v0_7B_Pipeline
|
||||||
|
return LLaVA_v0_7B_Pipeline(params)
|
||||||
|
if name == 'llava-13b':
|
||||||
|
from .llava import LLaVA_v0_13B_Pipeline
|
||||||
|
return LLaVA_v0_13B_Pipeline(params)
|
||||||
|
if name == 'llava-llama-2-13b':
|
||||||
|
from .llava import LLaVA_LLaMA_2_13B_Pipeline
|
||||||
|
return LLaVA_LLaMA_2_13B_Pipeline(params)
|
||||||
|
if name == 'llava-v1.5-7b':
|
||||||
|
from .llava import LLaVA_v1_5_7B_Pipeline
|
||||||
|
return LLaVA_v1_5_7B_Pipeline(params)
|
||||||
|
if name == 'llava-v1.5-13b':
|
||||||
|
from .llava import LLaVA_v1_5_13B_Pipeline
|
||||||
|
return LLaVA_v1_5_13B_Pipeline(params)
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
def get_pipeline_from_model_name(model_name: str, params: dict) -> Optional[AbstractMultimodalPipeline]:
|
||||||
|
if 'llava' not in model_name.lower():
|
||||||
|
return None
|
||||||
|
if 'llama-2' in model_name.lower():
|
||||||
|
if '13b' in model_name.lower():
|
||||||
|
from .llava import LLaVA_LLaMA_2_13B_Pipeline
|
||||||
|
return LLaVA_LLaMA_2_13B_Pipeline(params)
|
||||||
|
elif 'llava-v1.5' in model_name.lower():
|
||||||
|
if '13b' in model_name.lower():
|
||||||
|
from .llava import LLaVA_v1_5_13B_Pipeline
|
||||||
|
return LLaVA_v1_5_13B_Pipeline(params)
|
||||||
|
if '7b' in model_name.lower():
|
||||||
|
from .llava import LLaVA_v1_5_7B_Pipeline
|
||||||
|
return LLaVA_v1_5_7B_Pipeline(params)
|
||||||
|
else:
|
||||||
|
if '7b' in model_name.lower():
|
||||||
|
from .llava import LLaVA_v0_7B_Pipeline
|
||||||
|
return LLaVA_v0_7B_Pipeline(params)
|
||||||
|
if '13b' in model_name.lower():
|
||||||
|
from .llava import LLaVA_v0_13B_Pipeline
|
||||||
|
return LLaVA_v0_13B_Pipeline(params)
|
||||||
|
return None
|
||||||
@ -0,0 +1,113 @@
|
|||||||
|
import base64
|
||||||
|
import re
|
||||||
|
import time
|
||||||
|
from functools import partial
|
||||||
|
from io import BytesIO
|
||||||
|
|
||||||
|
import gradio as gr
|
||||||
|
import torch
|
||||||
|
|
||||||
|
from extensions.multimodal.multimodal_embedder import MultimodalEmbedder
|
||||||
|
from modules import shared
|
||||||
|
from modules.logging_colors import logger
|
||||||
|
|
||||||
|
params = {
|
||||||
|
"add_all_images_to_prompt": False,
|
||||||
|
# device to run vision encoder on
|
||||||
|
"vision_device": None,
|
||||||
|
# bits to load vision encoder in, either 16 or 32
|
||||||
|
"vision_bits": 32,
|
||||||
|
# device to run multimodal projector on
|
||||||
|
"projector_device": None,
|
||||||
|
# multimodal projector bits, either 32 or 16
|
||||||
|
"projector_bits": 32
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
# If 'state' is True, will hijack the next chat generation
|
||||||
|
input_hijack = {
|
||||||
|
'state': False,
|
||||||
|
'value': ["", ""]
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
# initialized in ui, so that params are loaded from settings
|
||||||
|
multimodal_embedder: MultimodalEmbedder = None
|
||||||
|
|
||||||
|
|
||||||
|
def chat_input_modifier(text, visible_text, state):
|
||||||
|
global input_hijack
|
||||||
|
if input_hijack['state']:
|
||||||
|
input_hijack['state'] = False
|
||||||
|
return input_hijack['value'](text, visible_text)
|
||||||
|
else:
|
||||||
|
return text, visible_text
|
||||||
|
|
||||||
|
|
||||||
|
def add_chat_picture(picture, text, visible_text):
|
||||||
|
# resize the image, so that shortest edge is at least 224 (size for CLIP), and at most 300 (to keep history manageable)
|
||||||
|
# Adjusted to 336 for the values here, due to the increased resolution in llava-v1.5
|
||||||
|
max_hw, min_hw = max(picture.size), min(picture.size)
|
||||||
|
aspect_ratio = max_hw / min_hw
|
||||||
|
shortest_edge = int(max(336 / aspect_ratio, 336))
|
||||||
|
longest_edge = int(shortest_edge * aspect_ratio)
|
||||||
|
w = shortest_edge if picture.width < picture.height else longest_edge
|
||||||
|
h = shortest_edge if picture.width >= picture.height else longest_edge
|
||||||
|
picture = picture.resize((w, h))
|
||||||
|
|
||||||
|
buffer = BytesIO()
|
||||||
|
picture.save(buffer, format="PNG")
|
||||||
|
img_str = base64.b64encode(buffer.getvalue()).decode('utf-8')
|
||||||
|
image = f'<img src="data:image/jpeg;base64,{img_str}">'
|
||||||
|
|
||||||
|
if '<image>' in text:
|
||||||
|
text = text.replace('<image>', image)
|
||||||
|
else:
|
||||||
|
text = image + '\n' + text
|
||||||
|
|
||||||
|
if visible_text == '' or visible_text is None:
|
||||||
|
visible_text = text
|
||||||
|
elif '<image>' in visible_text:
|
||||||
|
visible_text = visible_text.replace('<image>', image)
|
||||||
|
else:
|
||||||
|
visible_text = visible_text + '\n' + image
|
||||||
|
|
||||||
|
return text, visible_text
|
||||||
|
|
||||||
|
|
||||||
|
def custom_tokenized_length(prompt):
|
||||||
|
return multimodal_embedder.len_in_tokens(prompt)
|
||||||
|
|
||||||
|
|
||||||
|
def tokenizer_modifier(state, prompt, input_ids, input_embeds):
|
||||||
|
global params
|
||||||
|
start_ts = time.time()
|
||||||
|
image_match = re.search(r'<img src="data:image/jpeg;base64,[A-Za-z0-9+/=]+">', prompt)
|
||||||
|
|
||||||
|
if image_match is None:
|
||||||
|
return prompt, input_ids, input_embeds
|
||||||
|
|
||||||
|
prompt, input_ids, input_embeds, total_embedded = multimodal_embedder.forward(prompt, state, params)
|
||||||
|
logger.info(f'Embedded {total_embedded} image(s) in {time.time()-start_ts:.2f}s')
|
||||||
|
return (prompt,
|
||||||
|
input_ids.unsqueeze(0).to(shared.model.device, dtype=torch.int64),
|
||||||
|
input_embeds.unsqueeze(0).to(shared.model.device, dtype=shared.model.dtype))
|
||||||
|
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
global multimodal_embedder
|
||||||
|
multimodal_embedder = MultimodalEmbedder(params)
|
||||||
|
with gr.Column():
|
||||||
|
picture_select = gr.Image(label='Send a picture', type='pil')
|
||||||
|
# The models don't seem to deal well with multiple images
|
||||||
|
single_image_checkbox = gr.Checkbox(False, label='Embed all images, not only the last one')
|
||||||
|
# Prepare the input hijack
|
||||||
|
picture_select.upload(
|
||||||
|
lambda picture: input_hijack.update({"state": True, "value": partial(add_chat_picture, picture)}),
|
||||||
|
[picture_select],
|
||||||
|
None
|
||||||
|
)
|
||||||
|
picture_select.clear(lambda: input_hijack.update({"state": False, "value": ["", ""]}), None, None)
|
||||||
|
single_image_checkbox.change(lambda x: params.update({"add_all_images_to_prompt": x}), single_image_checkbox, None)
|
||||||
|
shared.gradio['Generate'].click(lambda: None, None, picture_select)
|
||||||
|
shared.gradio['textbox'].submit(lambda: None, None, picture_select)
|
||||||
@ -0,0 +1,69 @@
|
|||||||
|
# Adding an ingress URL through the ngrok Agent SDK for Python
|
||||||
|
|
||||||
|
[ngrok](https://ngrok.com) is a globally distributed reverse proxy commonly used for quickly getting a public URL to a
|
||||||
|
service running inside a private network, such as on your local laptop. The ngrok agent is usually
|
||||||
|
deployed inside a private network and is used to communicate with the ngrok cloud service.
|
||||||
|
|
||||||
|
By default the authtoken in the NGROK_AUTHTOKEN environment variable will be used. Alternatively one may be specified in
|
||||||
|
the `settings.json` file, see the Examples below. Retrieve your authtoken on the [Auth Token page of your ngrok dashboard](https://dashboard.ngrok.com/get-started/your-authtoken), signing up is free.
|
||||||
|
|
||||||
|
# Documentation
|
||||||
|
|
||||||
|
For a list of all available options, see [the configuration documentation](https://ngrok.com/docs/ngrok-agent/config/) or [the connect example](https://github.com/ngrok/ngrok-py/blob/main/examples/ngrok-connect-full.py).
|
||||||
|
|
||||||
|
The ngrok Python SDK is [on github here](https://github.com/ngrok/ngrok-py). A quickstart guide and a full API reference are included in the [ngrok-py Python API documentation](https://ngrok.github.io/ngrok-py/).
|
||||||
|
|
||||||
|
# Running
|
||||||
|
|
||||||
|
To enable ngrok install the requirements and then add `--extension ngrok` to the command line options, for instance:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install -r extensions/ngrok/requirements.txt
|
||||||
|
python server.py --extension ngrok
|
||||||
|
```
|
||||||
|
|
||||||
|
In the output you should then see something like this:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
INFO:Loading the extension "ngrok"...
|
||||||
|
INFO:Session created
|
||||||
|
INFO:Created tunnel "9d9d0944dc75ff9d3aae653e5eb29fe9" with url "https://d83706cf7be7.ngrok.app"
|
||||||
|
INFO:Tunnel "9d9d0944dc75ff9d3aae653e5eb29fe9" TCP forwarding to "localhost:7860"
|
||||||
|
INFO:Ingress established at https://d83706cf7be7.ngrok.app
|
||||||
|
```
|
||||||
|
|
||||||
|
You can now access the webui via the url shown, in this case `https://d83706cf7be7.ngrok.app`. It is recommended to add some authentication to the ingress, see below.
|
||||||
|
|
||||||
|
# Example Settings
|
||||||
|
|
||||||
|
In `settings.json` add a `ngrok` key with a dictionary of options, for instance:
|
||||||
|
|
||||||
|
To enable basic authentication:
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"ngrok": {
|
||||||
|
"basic_auth": "user:password"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
To enable OAUTH authentication:
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"ngrok": {
|
||||||
|
"oauth_provider": "google",
|
||||||
|
"oauth_allow_domains": "asdf.com",
|
||||||
|
"oauth_allow_emails": "asdf@asdf.com"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
To add an authtoken instead of using the NGROK_AUTHTOKEN environment variable:
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"ngrok": {
|
||||||
|
"authtoken": "<token>",
|
||||||
|
"authtoken_from_env":false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
@ -0,0 +1 @@
|
|||||||
|
ngrok==0.*
|
||||||
@ -0,0 +1,36 @@
|
|||||||
|
# Adds ngrok ingress, to use add `--extension ngrok` to the command line options
|
||||||
|
#
|
||||||
|
# Parameters can be customized in settings.json of webui, e.g.:
|
||||||
|
# {"ngrok": {"basic_auth":"user:password"} }
|
||||||
|
# or
|
||||||
|
# {"ngrok": {"oauth_provider":"google", "oauth_allow_emails":["asdf@asdf.com"]} }
|
||||||
|
#
|
||||||
|
# See this example for full list of options: https://github.com/ngrok/ngrok-py/blob/main/examples/ngrok-connect-full.py
|
||||||
|
# or the README.md in this directory.
|
||||||
|
|
||||||
|
import logging
|
||||||
|
from modules import shared
|
||||||
|
|
||||||
|
# Pick up host/port command line arguments
|
||||||
|
host = shared.args.listen_host if shared.args.listen_host and shared.args.listen else '127.0.0.1'
|
||||||
|
port = shared.args.listen_port if shared.args.listen_port else '7860'
|
||||||
|
|
||||||
|
# Default options
|
||||||
|
options = {
|
||||||
|
'addr': f"{host}:{port}",
|
||||||
|
'authtoken_from_env': True,
|
||||||
|
'session_metadata': 'text-generation-webui',
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
settings = shared.settings.get("ngrok")
|
||||||
|
if settings:
|
||||||
|
options.update(settings)
|
||||||
|
|
||||||
|
try:
|
||||||
|
import ngrok
|
||||||
|
tunnel = ngrok.connect(**options)
|
||||||
|
logging.info(f"Ingress established at: {tunnel.url()}")
|
||||||
|
except ModuleNotFoundError:
|
||||||
|
logging.error("===> ngrok library not found, please run `pip install -r extensions/ngrok/requirements.txt`")
|
||||||
@ -0,0 +1,11 @@
|
|||||||
|
#!/usr/bin/env python3
|
||||||
|
# preload the embedding model, useful for Docker images to prevent re-download on config change
|
||||||
|
# Dockerfile:
|
||||||
|
# ENV OPENEDAI_EMBEDDING_MODEL="sentence-transformers/all-mpnet-base-v2" # Optional
|
||||||
|
# RUN python3 cache_embedded_model.py
|
||||||
|
import os
|
||||||
|
|
||||||
|
import sentence_transformers
|
||||||
|
|
||||||
|
st_model = os.environ.get("OPENEDAI_EMBEDDING_MODEL", "sentence-transformers/all-mpnet-base-v2")
|
||||||
|
model = sentence_transformers.SentenceTransformer(st_model)
|
||||||
@ -0,0 +1,507 @@
|
|||||||
|
import copy
|
||||||
|
import time
|
||||||
|
from collections import deque
|
||||||
|
|
||||||
|
import tiktoken
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from transformers import LogitsProcessor, LogitsProcessorList
|
||||||
|
|
||||||
|
from extensions.openai.errors import InvalidRequestError
|
||||||
|
from extensions.openai.utils import debug_msg
|
||||||
|
from modules import shared
|
||||||
|
from modules.chat import (
|
||||||
|
generate_chat_prompt,
|
||||||
|
generate_chat_reply,
|
||||||
|
load_character_memoized
|
||||||
|
)
|
||||||
|
from modules.presets import load_preset_memoized
|
||||||
|
from modules.text_generation import decode, encode, generate_reply
|
||||||
|
|
||||||
|
|
||||||
|
class LogitsBiasProcessor(LogitsProcessor):
|
||||||
|
def __init__(self, logit_bias={}):
|
||||||
|
self.logit_bias = logit_bias
|
||||||
|
if self.logit_bias:
|
||||||
|
self.keys = list([int(key) for key in self.logit_bias.keys()])
|
||||||
|
values = [self.logit_bias[str(key)] for key in self.keys]
|
||||||
|
self.values = torch.tensor(values, dtype=torch.float, device=shared.model.device)
|
||||||
|
debug_msg(f"{self})")
|
||||||
|
|
||||||
|
def __call__(self, input_ids: torch.LongTensor, logits: torch.FloatTensor) -> torch.FloatTensor:
|
||||||
|
if self.logit_bias:
|
||||||
|
debug_msg(logits[0, self.keys], " + ", self.values)
|
||||||
|
logits[0, self.keys] += self.values
|
||||||
|
debug_msg(" --> ", logits[0, self.keys])
|
||||||
|
debug_msg(" max/min ", float(torch.max(logits[0])), float(torch.min(logits[0])))
|
||||||
|
|
||||||
|
return logits
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return f"<{self.__class__.__name__}(logit_bias={self.logit_bias})>"
|
||||||
|
|
||||||
|
|
||||||
|
class LogprobProcessor(LogitsProcessor):
|
||||||
|
def __init__(self, logprobs=None):
|
||||||
|
self.logprobs = logprobs
|
||||||
|
self.token_alternatives = {}
|
||||||
|
|
||||||
|
def __call__(self, input_ids: torch.LongTensor, logits: torch.FloatTensor) -> torch.FloatTensor:
|
||||||
|
if self.logprobs is not None: # 0-5
|
||||||
|
log_e_probabilities = F.log_softmax(logits, dim=1)
|
||||||
|
top_values, top_indices = torch.topk(log_e_probabilities, k=self.logprobs + 1)
|
||||||
|
top_tokens = [decode(tok) for tok in top_indices[0]]
|
||||||
|
top_probs = [float(x) for x in top_values[0]]
|
||||||
|
self.token_alternatives = dict(zip(top_tokens, top_probs))
|
||||||
|
debug_msg(repr(self))
|
||||||
|
|
||||||
|
return logits
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return f"<{self.__class__.__name__}(logprobs={self.logprobs}, token_alternatives={self.token_alternatives})>"
|
||||||
|
|
||||||
|
|
||||||
|
def convert_logprobs_to_tiktoken(model, logprobs):
|
||||||
|
# more problems than it's worth.
|
||||||
|
# try:
|
||||||
|
# encoder = tiktoken.encoding_for_model(model)
|
||||||
|
# # just pick the first one if it encodes to multiple tokens... 99.9% not required and maybe worse overall.
|
||||||
|
# return dict([(encoder.decode([encoder.encode(token)[0]]), prob) for token, prob in logprobs.items()])
|
||||||
|
# except KeyError:
|
||||||
|
# # assume native tokens if we can't find the tokenizer
|
||||||
|
# return logprobs
|
||||||
|
|
||||||
|
return logprobs
|
||||||
|
|
||||||
|
|
||||||
|
def process_parameters(body, is_legacy=False):
|
||||||
|
generate_params = body
|
||||||
|
max_tokens_str = 'length' if is_legacy else 'max_tokens'
|
||||||
|
generate_params['max_new_tokens'] = body.pop(max_tokens_str)
|
||||||
|
if generate_params['truncation_length'] == 0:
|
||||||
|
generate_params['truncation_length'] = shared.settings['truncation_length']
|
||||||
|
|
||||||
|
if body['preset'] is not None:
|
||||||
|
preset = load_preset_memoized(body['preset'])
|
||||||
|
generate_params.update(preset)
|
||||||
|
|
||||||
|
generate_params['custom_stopping_strings'] = []
|
||||||
|
if 'stop' in body: # str or array, max len 4 (ignored)
|
||||||
|
if isinstance(body['stop'], str):
|
||||||
|
generate_params['custom_stopping_strings'] = [body['stop']]
|
||||||
|
elif isinstance(body['stop'], list):
|
||||||
|
generate_params['custom_stopping_strings'] = body['stop']
|
||||||
|
|
||||||
|
logits_processor = []
|
||||||
|
logit_bias = body.get('logit_bias', None)
|
||||||
|
if logit_bias: # {str: float, ...}
|
||||||
|
# XXX convert tokens from tiktoken based on requested model
|
||||||
|
# Ex.: 'logit_bias': {'1129': 100, '11442': 100, '16243': 100}
|
||||||
|
try:
|
||||||
|
encoder = tiktoken.encoding_for_model(generate_params['model'])
|
||||||
|
new_logit_bias = {}
|
||||||
|
for logit, bias in logit_bias.items():
|
||||||
|
for x in encode(encoder.decode([int(logit)]), add_special_tokens=False)[0]:
|
||||||
|
if int(x) in [0, 1, 2, 29871]: # XXX LLAMA tokens
|
||||||
|
continue
|
||||||
|
|
||||||
|
new_logit_bias[str(int(x))] = bias
|
||||||
|
debug_msg('logit_bias_map', logit_bias, '->', new_logit_bias)
|
||||||
|
logit_bias = new_logit_bias
|
||||||
|
except KeyError:
|
||||||
|
pass # assume native tokens if we can't find the tokenizer
|
||||||
|
|
||||||
|
logits_processor = [LogitsBiasProcessor(logit_bias)]
|
||||||
|
|
||||||
|
logprobs = None # coming to chat eventually
|
||||||
|
if 'logprobs' in body:
|
||||||
|
logprobs = body.get('logprobs', 0) # maybe cap at topk? don't clamp 0-5.
|
||||||
|
generate_params['logprob_proc'] = LogprobProcessor(logprobs)
|
||||||
|
logits_processor.extend([generate_params['logprob_proc']])
|
||||||
|
else:
|
||||||
|
logprobs = None
|
||||||
|
|
||||||
|
if logits_processor: # requires logits_processor support
|
||||||
|
generate_params['logits_processor'] = LogitsProcessorList(logits_processor)
|
||||||
|
|
||||||
|
return generate_params
|
||||||
|
|
||||||
|
|
||||||
|
def convert_history(history):
|
||||||
|
'''
|
||||||
|
Chat histories in this program are in the format [message, reply].
|
||||||
|
This function converts OpenAI histories to that format.
|
||||||
|
'''
|
||||||
|
chat_dialogue = []
|
||||||
|
current_message = ""
|
||||||
|
current_reply = ""
|
||||||
|
user_input = ""
|
||||||
|
system_message = ""
|
||||||
|
|
||||||
|
for entry in history:
|
||||||
|
content = entry["content"]
|
||||||
|
role = entry["role"]
|
||||||
|
|
||||||
|
if role == "user":
|
||||||
|
user_input = content
|
||||||
|
if current_message:
|
||||||
|
chat_dialogue.append([current_message, ''])
|
||||||
|
current_message = ""
|
||||||
|
current_message = content
|
||||||
|
elif role == "assistant":
|
||||||
|
current_reply = content
|
||||||
|
if current_message:
|
||||||
|
chat_dialogue.append([current_message, current_reply])
|
||||||
|
current_message = ""
|
||||||
|
current_reply = ""
|
||||||
|
else:
|
||||||
|
chat_dialogue.append(['', current_reply])
|
||||||
|
elif role == "system":
|
||||||
|
system_message = content
|
||||||
|
|
||||||
|
# if current_message:
|
||||||
|
# chat_dialogue.append([current_message, ''])
|
||||||
|
|
||||||
|
return user_input, system_message, {'internal': chat_dialogue, 'visible': copy.deepcopy(chat_dialogue)}
|
||||||
|
|
||||||
|
|
||||||
|
def chat_completions_common(body: dict, is_legacy: bool = False, stream=False) -> dict:
|
||||||
|
if body.get('functions', []):
|
||||||
|
raise InvalidRequestError(message="functions is not supported.", param='functions')
|
||||||
|
|
||||||
|
if body.get('function_call', ''):
|
||||||
|
raise InvalidRequestError(message="function_call is not supported.", param='function_call')
|
||||||
|
|
||||||
|
if 'messages' not in body:
|
||||||
|
raise InvalidRequestError(message="messages is required", param='messages')
|
||||||
|
|
||||||
|
messages = body['messages']
|
||||||
|
for m in messages:
|
||||||
|
if 'role' not in m:
|
||||||
|
raise InvalidRequestError(message="messages: missing role", param='messages')
|
||||||
|
elif m['role'] == 'function':
|
||||||
|
raise InvalidRequestError(message="role: function is not supported.", param='messages')
|
||||||
|
if 'content' not in m:
|
||||||
|
raise InvalidRequestError(message="messages: missing content", param='messages')
|
||||||
|
|
||||||
|
# Chat Completions
|
||||||
|
object_type = 'chat.completions' if not stream else 'chat.completions.chunk'
|
||||||
|
created_time = int(time.time())
|
||||||
|
cmpl_id = "chatcmpl-%d" % (int(time.time() * 1000000000))
|
||||||
|
resp_list = 'data' if is_legacy else 'choices'
|
||||||
|
|
||||||
|
# generation parameters
|
||||||
|
generate_params = process_parameters(body, is_legacy=is_legacy)
|
||||||
|
continue_ = body['continue_']
|
||||||
|
|
||||||
|
# Instruction template
|
||||||
|
instruction_template = body['instruction_template'] or shared.settings['instruction_template']
|
||||||
|
instruction_template = "Alpaca" if instruction_template == "None" else instruction_template
|
||||||
|
name1_instruct, name2_instruct, _, _, context_instruct, turn_template, system_message = load_character_memoized(instruction_template, '', '', instruct=True)
|
||||||
|
name1_instruct = body['name1_instruct'] or name1_instruct
|
||||||
|
name2_instruct = body['name2_instruct'] or name2_instruct
|
||||||
|
turn_template = body['turn_template'] or turn_template
|
||||||
|
context_instruct = body['context_instruct'] or context_instruct
|
||||||
|
system_message = body['system_message'] or system_message
|
||||||
|
|
||||||
|
# Chat character
|
||||||
|
character = body['character'] or shared.settings['character']
|
||||||
|
character = "Assistant" if character == "None" else character
|
||||||
|
name1 = body['name1'] or shared.settings['name1']
|
||||||
|
name1, name2, _, greeting, context, _, _ = load_character_memoized(character, name1, '', instruct=False)
|
||||||
|
name2 = body['name2'] or name2
|
||||||
|
context = body['context'] or context
|
||||||
|
greeting = body['greeting'] or greeting
|
||||||
|
|
||||||
|
# History
|
||||||
|
user_input, custom_system_message, history = convert_history(messages)
|
||||||
|
|
||||||
|
generate_params.update({
|
||||||
|
'mode': body['mode'],
|
||||||
|
'name1': name1,
|
||||||
|
'name2': name2,
|
||||||
|
'context': context,
|
||||||
|
'greeting': greeting,
|
||||||
|
'name1_instruct': name1_instruct,
|
||||||
|
'name2_instruct': name2_instruct,
|
||||||
|
'context_instruct': context_instruct,
|
||||||
|
'system_message': system_message,
|
||||||
|
'custom_system_message': custom_system_message,
|
||||||
|
'turn_template': turn_template,
|
||||||
|
'chat-instruct_command': body['chat_instruct_command'],
|
||||||
|
'history': history,
|
||||||
|
'stream': stream
|
||||||
|
})
|
||||||
|
|
||||||
|
max_tokens = generate_params['max_new_tokens']
|
||||||
|
if max_tokens in [None, 0]:
|
||||||
|
generate_params['max_new_tokens'] = 200
|
||||||
|
generate_params['auto_max_new_tokens'] = True
|
||||||
|
|
||||||
|
requested_model = generate_params.pop('model')
|
||||||
|
logprob_proc = generate_params.pop('logprob_proc', None)
|
||||||
|
|
||||||
|
def chat_streaming_chunk(content):
|
||||||
|
# begin streaming
|
||||||
|
chunk = {
|
||||||
|
"id": cmpl_id,
|
||||||
|
"object": object_type,
|
||||||
|
"created": created_time,
|
||||||
|
"model": shared.model_name,
|
||||||
|
resp_list: [{
|
||||||
|
"index": 0,
|
||||||
|
"finish_reason": None,
|
||||||
|
# So yeah... do both methods? delta and messages.
|
||||||
|
"message": {'role': 'assistant', 'content': content},
|
||||||
|
"delta": {'role': 'assistant', 'content': content},
|
||||||
|
}],
|
||||||
|
}
|
||||||
|
|
||||||
|
if logprob_proc: # not official for chat yet
|
||||||
|
top_logprobs = convert_logprobs_to_tiktoken(model=requested_model, logprobs=logprob_proc.token_alternatives)
|
||||||
|
chunk[resp_list][0]["logprobs"] = {'top_logprobs': [top_logprobs]}
|
||||||
|
# else:
|
||||||
|
# chunk[resp_list][0]["logprobs"] = None
|
||||||
|
return chunk
|
||||||
|
|
||||||
|
if stream:
|
||||||
|
yield chat_streaming_chunk('')
|
||||||
|
|
||||||
|
# generate reply #######################################
|
||||||
|
prompt = generate_chat_prompt(user_input, generate_params)
|
||||||
|
token_count = len(encode(prompt)[0])
|
||||||
|
debug_msg({'prompt': prompt, 'generate_params': generate_params})
|
||||||
|
|
||||||
|
generator = generate_chat_reply(
|
||||||
|
user_input, generate_params, regenerate=False, _continue=continue_, loading_message=False)
|
||||||
|
|
||||||
|
answer = ''
|
||||||
|
seen_content = ''
|
||||||
|
completion_token_count = 0
|
||||||
|
|
||||||
|
for a in generator:
|
||||||
|
answer = a['internal'][-1][1]
|
||||||
|
if stream:
|
||||||
|
len_seen = len(seen_content)
|
||||||
|
new_content = answer[len_seen:]
|
||||||
|
|
||||||
|
if not new_content or chr(0xfffd) in new_content: # partial unicode character, don't send it yet.
|
||||||
|
continue
|
||||||
|
|
||||||
|
seen_content = answer
|
||||||
|
chunk = chat_streaming_chunk(new_content)
|
||||||
|
yield chunk
|
||||||
|
|
||||||
|
completion_token_count = len(encode(answer)[0])
|
||||||
|
stop_reason = "stop"
|
||||||
|
if token_count + completion_token_count >= generate_params['truncation_length'] or completion_token_count >= generate_params['max_new_tokens']:
|
||||||
|
stop_reason = "length"
|
||||||
|
|
||||||
|
if stream:
|
||||||
|
chunk = chat_streaming_chunk('')
|
||||||
|
chunk[resp_list][0]['finish_reason'] = stop_reason
|
||||||
|
chunk['usage'] = {
|
||||||
|
"prompt_tokens": token_count,
|
||||||
|
"completion_tokens": completion_token_count,
|
||||||
|
"total_tokens": token_count + completion_token_count
|
||||||
|
}
|
||||||
|
|
||||||
|
yield chunk
|
||||||
|
else:
|
||||||
|
resp = {
|
||||||
|
"id": cmpl_id,
|
||||||
|
"object": object_type,
|
||||||
|
"created": created_time,
|
||||||
|
"model": shared.model_name,
|
||||||
|
resp_list: [{
|
||||||
|
"index": 0,
|
||||||
|
"finish_reason": stop_reason,
|
||||||
|
"message": {"role": "assistant", "content": answer}
|
||||||
|
}],
|
||||||
|
"usage": {
|
||||||
|
"prompt_tokens": token_count,
|
||||||
|
"completion_tokens": completion_token_count,
|
||||||
|
"total_tokens": token_count + completion_token_count
|
||||||
|
}
|
||||||
|
}
|
||||||
|
if logprob_proc: # not official for chat yet
|
||||||
|
top_logprobs = convert_logprobs_to_tiktoken(model=requested_model, logprobs=logprob_proc.token_alternatives)
|
||||||
|
resp[resp_list][0]["logprobs"] = {'top_logprobs': [top_logprobs]}
|
||||||
|
# else:
|
||||||
|
# resp[resp_list][0]["logprobs"] = None
|
||||||
|
|
||||||
|
yield resp
|
||||||
|
|
||||||
|
|
||||||
|
def completions_common(body: dict, is_legacy: bool = False, stream=False):
|
||||||
|
object_type = 'text_completion.chunk' if stream else 'text_completion'
|
||||||
|
created_time = int(time.time())
|
||||||
|
cmpl_id = "conv-%d" % (int(time.time() * 1000000000))
|
||||||
|
resp_list = 'data' if is_legacy else 'choices'
|
||||||
|
|
||||||
|
prompt_str = 'context' if is_legacy else 'prompt'
|
||||||
|
|
||||||
|
# ... encoded as a string, array of strings, array of tokens, or array of token arrays.
|
||||||
|
if prompt_str not in body:
|
||||||
|
raise InvalidRequestError("Missing required input", param=prompt_str)
|
||||||
|
|
||||||
|
# common params
|
||||||
|
generate_params = process_parameters(body, is_legacy=is_legacy)
|
||||||
|
max_tokens = generate_params['max_new_tokens']
|
||||||
|
generate_params['stream'] = stream
|
||||||
|
requested_model = generate_params.pop('model')
|
||||||
|
logprob_proc = generate_params.pop('logprob_proc', None)
|
||||||
|
suffix = body['suffix'] if body['suffix'] else ''
|
||||||
|
echo = body['echo']
|
||||||
|
|
||||||
|
if not stream:
|
||||||
|
prompt_arg = body[prompt_str]
|
||||||
|
if isinstance(prompt_arg, str) or (isinstance(prompt_arg, list) and isinstance(prompt_arg[0], int)):
|
||||||
|
prompt_arg = [prompt_arg]
|
||||||
|
|
||||||
|
resp_list_data = []
|
||||||
|
total_completion_token_count = 0
|
||||||
|
total_prompt_token_count = 0
|
||||||
|
|
||||||
|
for idx, prompt in enumerate(prompt_arg, start=0):
|
||||||
|
if isinstance(prompt[0], int):
|
||||||
|
# token lists
|
||||||
|
if requested_model == shared.model_name:
|
||||||
|
prompt = decode(prompt)[0]
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
encoder = tiktoken.encoding_for_model(requested_model)
|
||||||
|
prompt = encoder.decode(prompt)
|
||||||
|
except KeyError:
|
||||||
|
prompt = decode(prompt)[0]
|
||||||
|
|
||||||
|
prefix = prompt if echo else ''
|
||||||
|
token_count = len(encode(prompt)[0])
|
||||||
|
total_prompt_token_count += token_count
|
||||||
|
|
||||||
|
# generate reply #######################################
|
||||||
|
debug_msg({'prompt': prompt, 'generate_params': generate_params})
|
||||||
|
generator = generate_reply(prompt, generate_params, is_chat=False)
|
||||||
|
answer = ''
|
||||||
|
|
||||||
|
for a in generator:
|
||||||
|
answer = a
|
||||||
|
|
||||||
|
completion_token_count = len(encode(answer)[0])
|
||||||
|
total_completion_token_count += completion_token_count
|
||||||
|
stop_reason = "stop"
|
||||||
|
if token_count + completion_token_count >= generate_params['truncation_length'] or completion_token_count >= max_tokens:
|
||||||
|
stop_reason = "length"
|
||||||
|
|
||||||
|
respi = {
|
||||||
|
"index": idx,
|
||||||
|
"finish_reason": stop_reason,
|
||||||
|
"text": prefix + answer + suffix,
|
||||||
|
"logprobs": {'top_logprobs': [logprob_proc.token_alternatives]} if logprob_proc else None,
|
||||||
|
}
|
||||||
|
|
||||||
|
resp_list_data.extend([respi])
|
||||||
|
|
||||||
|
resp = {
|
||||||
|
"id": cmpl_id,
|
||||||
|
"object": object_type,
|
||||||
|
"created": created_time,
|
||||||
|
"model": shared.model_name,
|
||||||
|
resp_list: resp_list_data,
|
||||||
|
"usage": {
|
||||||
|
"prompt_tokens": total_prompt_token_count,
|
||||||
|
"completion_tokens": total_completion_token_count,
|
||||||
|
"total_tokens": total_prompt_token_count + total_completion_token_count
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
yield resp
|
||||||
|
else:
|
||||||
|
prompt = body[prompt_str]
|
||||||
|
if isinstance(prompt, list):
|
||||||
|
if prompt and isinstance(prompt[0], int):
|
||||||
|
try:
|
||||||
|
encoder = tiktoken.encoding_for_model(requested_model)
|
||||||
|
prompt = encoder.decode(prompt)
|
||||||
|
except KeyError:
|
||||||
|
prompt = decode(prompt)[0]
|
||||||
|
else:
|
||||||
|
raise InvalidRequestError(message="API Batched generation not yet supported.", param=prompt_str)
|
||||||
|
|
||||||
|
prefix = prompt if echo else ''
|
||||||
|
token_count = len(encode(prompt)[0])
|
||||||
|
|
||||||
|
def text_streaming_chunk(content):
|
||||||
|
# begin streaming
|
||||||
|
chunk = {
|
||||||
|
"id": cmpl_id,
|
||||||
|
"object": object_type,
|
||||||
|
"created": created_time,
|
||||||
|
"model": shared.model_name,
|
||||||
|
resp_list: [{
|
||||||
|
"index": 0,
|
||||||
|
"finish_reason": None,
|
||||||
|
"text": content,
|
||||||
|
"logprobs": {'top_logprobs': [logprob_proc.token_alternatives]} if logprob_proc else None,
|
||||||
|
}],
|
||||||
|
}
|
||||||
|
|
||||||
|
return chunk
|
||||||
|
|
||||||
|
yield text_streaming_chunk(prefix)
|
||||||
|
|
||||||
|
# generate reply #######################################
|
||||||
|
debug_msg({'prompt': prompt, 'generate_params': generate_params})
|
||||||
|
generator = generate_reply(prompt, generate_params, is_chat=False)
|
||||||
|
|
||||||
|
answer = ''
|
||||||
|
seen_content = ''
|
||||||
|
completion_token_count = 0
|
||||||
|
|
||||||
|
for a in generator:
|
||||||
|
answer = a
|
||||||
|
|
||||||
|
len_seen = len(seen_content)
|
||||||
|
new_content = answer[len_seen:]
|
||||||
|
|
||||||
|
if not new_content or chr(0xfffd) in new_content: # partial unicode character, don't send it yet.
|
||||||
|
continue
|
||||||
|
|
||||||
|
seen_content = answer
|
||||||
|
chunk = text_streaming_chunk(new_content)
|
||||||
|
yield chunk
|
||||||
|
|
||||||
|
completion_token_count = len(encode(answer)[0])
|
||||||
|
stop_reason = "stop"
|
||||||
|
if token_count + completion_token_count >= generate_params['truncation_length'] or completion_token_count >= max_tokens:
|
||||||
|
stop_reason = "length"
|
||||||
|
|
||||||
|
chunk = text_streaming_chunk(suffix)
|
||||||
|
chunk[resp_list][0]["finish_reason"] = stop_reason
|
||||||
|
chunk["usage"] = {
|
||||||
|
"prompt_tokens": token_count,
|
||||||
|
"completion_tokens": completion_token_count,
|
||||||
|
"total_tokens": token_count + completion_token_count
|
||||||
|
}
|
||||||
|
|
||||||
|
yield chunk
|
||||||
|
|
||||||
|
|
||||||
|
def chat_completions(body: dict, is_legacy: bool = False) -> dict:
|
||||||
|
generator = chat_completions_common(body, is_legacy, stream=False)
|
||||||
|
return deque(generator, maxlen=1).pop()
|
||||||
|
|
||||||
|
|
||||||
|
def stream_chat_completions(body: dict, is_legacy: bool = False):
|
||||||
|
for resp in chat_completions_common(body, is_legacy, stream=True):
|
||||||
|
yield resp
|
||||||
|
|
||||||
|
|
||||||
|
def completions(body: dict, is_legacy: bool = False) -> dict:
|
||||||
|
generator = completions_common(body, is_legacy, stream=False)
|
||||||
|
return deque(generator, maxlen=1).pop()
|
||||||
|
|
||||||
|
|
||||||
|
def stream_completions(body: dict, is_legacy: bool = False):
|
||||||
|
for resp in completions_common(body, is_legacy, stream=True):
|
||||||
|
yield resp
|
||||||
@ -0,0 +1,92 @@
|
|||||||
|
import os
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
from extensions.openai.errors import ServiceUnavailableError
|
||||||
|
from extensions.openai.utils import debug_msg, float_list_to_base64
|
||||||
|
from modules.logging_colors import logger
|
||||||
|
|
||||||
|
embeddings_params_initialized = False
|
||||||
|
|
||||||
|
|
||||||
|
def initialize_embedding_params():
|
||||||
|
'''
|
||||||
|
using 'lazy loading' to avoid circular import
|
||||||
|
so this function will be executed only once
|
||||||
|
'''
|
||||||
|
global embeddings_params_initialized
|
||||||
|
if not embeddings_params_initialized:
|
||||||
|
from extensions.openai.script import params
|
||||||
|
|
||||||
|
global st_model, embeddings_model, embeddings_device
|
||||||
|
|
||||||
|
st_model = os.environ.get("OPENEDAI_EMBEDDING_MODEL", params.get('embedding_model', 'all-mpnet-base-v2'))
|
||||||
|
embeddings_model = None
|
||||||
|
# OPENEDAI_EMBEDDING_DEVICE: auto (best or cpu), cpu, cuda, ipu, xpu, mkldnn, opengl, opencl, ideep, hip, ve, fpga, ort, xla, lazy, vulkan, mps, meta, hpu, mtia, privateuseone
|
||||||
|
embeddings_device = os.environ.get("OPENEDAI_EMBEDDING_DEVICE", params.get('embedding_device', 'cpu'))
|
||||||
|
if embeddings_device.lower() == 'auto':
|
||||||
|
embeddings_device = None
|
||||||
|
|
||||||
|
embeddings_params_initialized = True
|
||||||
|
|
||||||
|
|
||||||
|
def load_embedding_model(model: str):
|
||||||
|
try:
|
||||||
|
from sentence_transformers import SentenceTransformer
|
||||||
|
except ModuleNotFoundError:
|
||||||
|
logger.error("The sentence_transformers module has not been found. Please install it manually with pip install -U sentence-transformers.")
|
||||||
|
raise ModuleNotFoundError
|
||||||
|
|
||||||
|
initialize_embedding_params()
|
||||||
|
global embeddings_device, embeddings_model
|
||||||
|
try:
|
||||||
|
print(f"Try embedding model: {model} on {embeddings_device}")
|
||||||
|
embeddings_model = SentenceTransformer(model, device=embeddings_device)
|
||||||
|
print(f"Loaded embedding model: {model}")
|
||||||
|
except Exception as e:
|
||||||
|
embeddings_model = None
|
||||||
|
raise ServiceUnavailableError(f"Error: Failed to load embedding model: {model}", internal_message=repr(e))
|
||||||
|
|
||||||
|
|
||||||
|
def get_embeddings_model():
|
||||||
|
initialize_embedding_params()
|
||||||
|
global embeddings_model, st_model
|
||||||
|
if st_model and not embeddings_model:
|
||||||
|
load_embedding_model(st_model) # lazy load the model
|
||||||
|
|
||||||
|
return embeddings_model
|
||||||
|
|
||||||
|
|
||||||
|
def get_embeddings_model_name() -> str:
|
||||||
|
initialize_embedding_params()
|
||||||
|
global st_model
|
||||||
|
return st_model
|
||||||
|
|
||||||
|
|
||||||
|
def get_embeddings(input: list) -> np.ndarray:
|
||||||
|
model = get_embeddings_model()
|
||||||
|
debug_msg(f"embedding model : {model}")
|
||||||
|
embedding = model.encode(input, convert_to_numpy=True, normalize_embeddings=True, convert_to_tensor=False)
|
||||||
|
debug_msg(f"embedding result : {embedding}") # might be too long even for debug, use at you own will
|
||||||
|
return embedding
|
||||||
|
|
||||||
|
|
||||||
|
def embeddings(input: list, encoding_format: str) -> dict:
|
||||||
|
embeddings = get_embeddings(input)
|
||||||
|
if encoding_format == "base64":
|
||||||
|
data = [{"object": "embedding", "embedding": float_list_to_base64(emb), "index": n} for n, emb in enumerate(embeddings)]
|
||||||
|
else:
|
||||||
|
data = [{"object": "embedding", "embedding": emb.tolist(), "index": n} for n, emb in enumerate(embeddings)]
|
||||||
|
|
||||||
|
response = {
|
||||||
|
"object": "list",
|
||||||
|
"data": data,
|
||||||
|
"model": st_model, # return the real model
|
||||||
|
"usage": {
|
||||||
|
"prompt_tokens": 0,
|
||||||
|
"total_tokens": 0,
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
debug_msg(f"Embeddings return size: {len(embeddings[0])}, number: {len(embeddings)}")
|
||||||
|
return response
|
||||||
@ -0,0 +1,31 @@
|
|||||||
|
class OpenAIError(Exception):
|
||||||
|
def __init__(self, message=None, code=500, internal_message=''):
|
||||||
|
self.message = message
|
||||||
|
self.code = code
|
||||||
|
self.internal_message = internal_message
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return "%s(message=%r, code=%d)" % (
|
||||||
|
self.__class__.__name__,
|
||||||
|
self.message,
|
||||||
|
self.code,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidRequestError(OpenAIError):
|
||||||
|
def __init__(self, message, param, code=400, internal_message=''):
|
||||||
|
super().__init__(message, code, internal_message)
|
||||||
|
self.param = param
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return "%s(message=%r, code=%d, param=%s)" % (
|
||||||
|
self.__class__.__name__,
|
||||||
|
self.message,
|
||||||
|
self.code,
|
||||||
|
self.param,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class ServiceUnavailableError(OpenAIError):
|
||||||
|
def __init__(self, message="Service unavailable, please try again later.", code=503, internal_message=''):
|
||||||
|
super().__init__(message, code, internal_message)
|
||||||
@ -0,0 +1,70 @@
|
|||||||
|
import os
|
||||||
|
import time
|
||||||
|
|
||||||
|
import requests
|
||||||
|
|
||||||
|
from extensions.openai.errors import ServiceUnavailableError
|
||||||
|
|
||||||
|
|
||||||
|
def generations(prompt: str, size: str, response_format: str, n: int):
|
||||||
|
# Stable Diffusion callout wrapper for txt2img
|
||||||
|
# Low effort implementation for compatibility. With only "prompt" being passed and assuming DALL-E
|
||||||
|
# the results will be limited and likely poor. SD has hundreds of models and dozens of settings.
|
||||||
|
# If you want high quality tailored results you should just use the Stable Diffusion API directly.
|
||||||
|
# it's too general an API to try and shape the result with specific tags like negative prompts
|
||||||
|
# or "masterpiece", etc. SD configuration is beyond the scope of this API.
|
||||||
|
# At this point I will not add the edits and variations endpoints (ie. img2img) because they
|
||||||
|
# require changing the form data handling to accept multipart form data, also to properly support
|
||||||
|
# url return types will require file management and a web serving files... Perhaps later!
|
||||||
|
base_model_size = 512 if 'SD_BASE_MODEL_SIZE' not in os.environ else int(os.environ.get('SD_BASE_MODEL_SIZE', 512))
|
||||||
|
sd_defaults = {
|
||||||
|
'sampler_name': 'DPM++ 2M Karras', # vast improvement
|
||||||
|
'steps': 30,
|
||||||
|
}
|
||||||
|
|
||||||
|
width, height = [int(x) for x in size.split('x')] # ignore the restrictions on size
|
||||||
|
|
||||||
|
# to hack on better generation, edit default payload.
|
||||||
|
payload = {
|
||||||
|
'prompt': prompt, # ignore prompt limit of 1000 characters
|
||||||
|
'width': width,
|
||||||
|
'height': height,
|
||||||
|
'batch_size': n,
|
||||||
|
}
|
||||||
|
payload.update(sd_defaults)
|
||||||
|
|
||||||
|
scale = min(width, height) / base_model_size
|
||||||
|
if scale >= 1.2:
|
||||||
|
# for better performance with the default size (1024), and larger res.
|
||||||
|
scaler = {
|
||||||
|
'width': width // scale,
|
||||||
|
'height': height // scale,
|
||||||
|
'hr_scale': scale,
|
||||||
|
'enable_hr': True,
|
||||||
|
'hr_upscaler': 'Latent',
|
||||||
|
'denoising_strength': 0.68,
|
||||||
|
}
|
||||||
|
payload.update(scaler)
|
||||||
|
|
||||||
|
resp = {
|
||||||
|
'created': int(time.time()),
|
||||||
|
'data': []
|
||||||
|
}
|
||||||
|
from extensions.openai.script import params
|
||||||
|
|
||||||
|
# TODO: support SD_WEBUI_AUTH username:password pair.
|
||||||
|
sd_url = f"{os.environ.get('SD_WEBUI_URL', params.get('sd_webui_url', ''))}/sdapi/v1/txt2img"
|
||||||
|
|
||||||
|
response = requests.post(url=sd_url, json=payload)
|
||||||
|
r = response.json()
|
||||||
|
if response.status_code != 200 or 'images' not in r:
|
||||||
|
print(r)
|
||||||
|
raise ServiceUnavailableError(r.get('error', 'Unknown error calling Stable Diffusion'), code=response.status_code, internal_message=r.get('errors', None))
|
||||||
|
# r['parameters']...
|
||||||
|
for b64_json in r['images']:
|
||||||
|
if response_format == 'b64_json':
|
||||||
|
resp['data'].extend([{'b64_json': b64_json}])
|
||||||
|
else:
|
||||||
|
resp['data'].extend([{'url': f'data:image/png;base64,{b64_json}'}]) # yeah it's lazy. requests.get() will not work with this
|
||||||
|
|
||||||
|
return resp
|
||||||
@ -0,0 +1,69 @@
|
|||||||
|
from modules import shared
|
||||||
|
from modules.logging_colors import logger
|
||||||
|
from modules.models import load_model, unload_model
|
||||||
|
from modules.models_settings import get_model_metadata, update_model_parameters
|
||||||
|
from modules.utils import get_available_models
|
||||||
|
|
||||||
|
|
||||||
|
def get_current_model_info():
|
||||||
|
return {
|
||||||
|
'model_name': shared.model_name,
|
||||||
|
'lora_names': shared.lora_names
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def list_models():
|
||||||
|
result = {
|
||||||
|
"object": "list",
|
||||||
|
"data": []
|
||||||
|
}
|
||||||
|
|
||||||
|
for model in get_dummy_models() + get_available_models()[1:]:
|
||||||
|
result["data"].append(model_info_dict(model))
|
||||||
|
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
def model_info_dict(model_name: str) -> dict:
|
||||||
|
return {
|
||||||
|
"id": model_name,
|
||||||
|
"object": "model",
|
||||||
|
"created": 0,
|
||||||
|
"owned_by": "user"
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def get_dummy_models() -> list:
|
||||||
|
return [ # these are expected by so much, so include some here as a dummy
|
||||||
|
'gpt-3.5-turbo',
|
||||||
|
'text-embedding-ada-002',
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def _load_model(data):
|
||||||
|
model_name = data["model_name"]
|
||||||
|
args = data["args"]
|
||||||
|
settings = data["settings"]
|
||||||
|
|
||||||
|
unload_model()
|
||||||
|
model_settings = get_model_metadata(model_name)
|
||||||
|
update_model_parameters(model_settings)
|
||||||
|
|
||||||
|
# Update shared.args with custom model loading settings
|
||||||
|
if args:
|
||||||
|
for k in args:
|
||||||
|
if hasattr(shared.args, k):
|
||||||
|
setattr(shared.args, k, args[k])
|
||||||
|
|
||||||
|
shared.model, shared.tokenizer = load_model(model_name)
|
||||||
|
shared.model_name = model_name
|
||||||
|
|
||||||
|
# Update shared.settings with custom generation defaults
|
||||||
|
if settings:
|
||||||
|
for k in settings:
|
||||||
|
if k in shared.settings:
|
||||||
|
shared.settings[k] = settings[k]
|
||||||
|
if k == 'truncation_length':
|
||||||
|
logger.info(f"TRUNCATION LENGTH (UPDATED): {shared.settings['truncation_length']}")
|
||||||
|
elif k == 'instruction_template':
|
||||||
|
logger.info(f"INSTRUCTION TEMPLATE (UPDATED): {shared.settings['instruction_template']}")
|
||||||
@ -0,0 +1,69 @@
|
|||||||
|
import time
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
from numpy.linalg import norm
|
||||||
|
|
||||||
|
from extensions.openai.embeddings import get_embeddings
|
||||||
|
|
||||||
|
moderations_disabled = False # return 0/false
|
||||||
|
category_embeddings = None
|
||||||
|
antonym_embeddings = None
|
||||||
|
categories = ["sexual", "hate", "harassment", "self-harm", "sexual/minors", "hate/threatening", "violence/graphic", "self-harm/intent", "self-harm/instructions", "harassment/threatening", "violence"]
|
||||||
|
flag_threshold = 0.5
|
||||||
|
|
||||||
|
|
||||||
|
def get_category_embeddings() -> dict:
|
||||||
|
global category_embeddings, categories
|
||||||
|
if category_embeddings is None:
|
||||||
|
embeddings = get_embeddings(categories).tolist()
|
||||||
|
category_embeddings = dict(zip(categories, embeddings))
|
||||||
|
|
||||||
|
return category_embeddings
|
||||||
|
|
||||||
|
|
||||||
|
def cosine_similarity(a: np.ndarray, b: np.ndarray) -> float:
|
||||||
|
return np.dot(a, b) / (norm(a) * norm(b))
|
||||||
|
|
||||||
|
|
||||||
|
# seems most openai like with all-mpnet-base-v2
|
||||||
|
def mod_score(a: np.ndarray, b: np.ndarray) -> float:
|
||||||
|
return 2.0 * np.dot(a, b)
|
||||||
|
|
||||||
|
|
||||||
|
def moderations(input):
|
||||||
|
global category_embeddings, categories, flag_threshold, moderations_disabled
|
||||||
|
results = {
|
||||||
|
"id": f"modr-{int(time.time()*1e9)}",
|
||||||
|
"model": "text-moderation-001",
|
||||||
|
"results": [],
|
||||||
|
}
|
||||||
|
|
||||||
|
if moderations_disabled:
|
||||||
|
results['results'] = [{
|
||||||
|
'categories': dict([(C, False) for C in categories]),
|
||||||
|
'category_scores': dict([(C, 0.0) for C in categories]),
|
||||||
|
'flagged': False,
|
||||||
|
}]
|
||||||
|
return results
|
||||||
|
|
||||||
|
category_embeddings = get_category_embeddings()
|
||||||
|
|
||||||
|
# input, string or array
|
||||||
|
if isinstance(input, str):
|
||||||
|
input = [input]
|
||||||
|
|
||||||
|
for in_str in input:
|
||||||
|
for ine in get_embeddings([in_str]):
|
||||||
|
category_scores = dict([(C, mod_score(category_embeddings[C], ine)) for C in categories])
|
||||||
|
category_flags = dict([(C, bool(category_scores[C] > flag_threshold)) for C in categories])
|
||||||
|
flagged = any(category_flags.values())
|
||||||
|
|
||||||
|
results['results'].extend([{
|
||||||
|
'flagged': flagged,
|
||||||
|
'categories': category_flags,
|
||||||
|
'category_scores': category_scores,
|
||||||
|
}])
|
||||||
|
|
||||||
|
print(results)
|
||||||
|
|
||||||
|
return results
|
||||||
@ -0,0 +1,4 @@
|
|||||||
|
SpeechRecognition==3.10.0
|
||||||
|
flask_cloudflared==0.0.14
|
||||||
|
sse-starlette==1.6.5
|
||||||
|
tiktoken
|
||||||
@ -0,0 +1,317 @@
|
|||||||
|
import asyncio
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import traceback
|
||||||
|
from threading import Thread
|
||||||
|
|
||||||
|
import speech_recognition as sr
|
||||||
|
import uvicorn
|
||||||
|
from fastapi import Depends, FastAPI, Header, HTTPException
|
||||||
|
from fastapi.middleware.cors import CORSMiddleware
|
||||||
|
from fastapi.requests import Request
|
||||||
|
from fastapi.responses import JSONResponse
|
||||||
|
from pydub import AudioSegment
|
||||||
|
from sse_starlette import EventSourceResponse
|
||||||
|
|
||||||
|
import extensions.openai.completions as OAIcompletions
|
||||||
|
import extensions.openai.embeddings as OAIembeddings
|
||||||
|
import extensions.openai.images as OAIimages
|
||||||
|
import extensions.openai.models as OAImodels
|
||||||
|
import extensions.openai.moderations as OAImoderations
|
||||||
|
from extensions.openai.errors import ServiceUnavailableError
|
||||||
|
from extensions.openai.tokens import token_count, token_decode, token_encode
|
||||||
|
from extensions.openai.utils import _start_cloudflared
|
||||||
|
from modules import shared
|
||||||
|
from modules.logging_colors import logger
|
||||||
|
from modules.models import unload_model
|
||||||
|
from modules.text_generation import stop_everything_event
|
||||||
|
|
||||||
|
from .typing import (
|
||||||
|
ChatCompletionRequest,
|
||||||
|
ChatCompletionResponse,
|
||||||
|
CompletionRequest,
|
||||||
|
CompletionResponse,
|
||||||
|
DecodeRequest,
|
||||||
|
DecodeResponse,
|
||||||
|
EmbeddingsRequest,
|
||||||
|
EmbeddingsResponse,
|
||||||
|
EncodeRequest,
|
||||||
|
EncodeResponse,
|
||||||
|
LoadModelRequest,
|
||||||
|
ModelInfoResponse,
|
||||||
|
TokenCountResponse,
|
||||||
|
to_dict
|
||||||
|
)
|
||||||
|
|
||||||
|
params = {
|
||||||
|
'embedding_device': 'cpu',
|
||||||
|
'embedding_model': 'sentence-transformers/all-mpnet-base-v2',
|
||||||
|
'sd_webui_url': '',
|
||||||
|
'debug': 0
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
streaming_semaphore = asyncio.Semaphore(1)
|
||||||
|
|
||||||
|
|
||||||
|
def verify_api_key(authorization: str = Header(None)) -> None:
|
||||||
|
expected_api_key = shared.args.api_key
|
||||||
|
if expected_api_key and (authorization is None or authorization != f"Bearer {expected_api_key}"):
|
||||||
|
raise HTTPException(status_code=401, detail="Unauthorized")
|
||||||
|
|
||||||
|
|
||||||
|
app = FastAPI(dependencies=[Depends(verify_api_key)])
|
||||||
|
|
||||||
|
# Configure CORS settings to allow all origins, methods, and headers
|
||||||
|
app.add_middleware(
|
||||||
|
CORSMiddleware,
|
||||||
|
allow_origins=["*"],
|
||||||
|
allow_credentials=True,
|
||||||
|
allow_methods=["*"],
|
||||||
|
allow_headers=["*"]
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
@app.options("/")
|
||||||
|
async def options_route():
|
||||||
|
return JSONResponse(content="OK")
|
||||||
|
|
||||||
|
|
||||||
|
@app.post('/v1/completions', response_model=CompletionResponse)
|
||||||
|
async def openai_completions(request: Request, request_data: CompletionRequest):
|
||||||
|
path = request.url.path
|
||||||
|
is_legacy = "/generate" in path
|
||||||
|
|
||||||
|
if request_data.stream:
|
||||||
|
async def generator():
|
||||||
|
async with streaming_semaphore:
|
||||||
|
response = OAIcompletions.stream_completions(to_dict(request_data), is_legacy=is_legacy)
|
||||||
|
for resp in response:
|
||||||
|
disconnected = await request.is_disconnected()
|
||||||
|
if disconnected:
|
||||||
|
break
|
||||||
|
|
||||||
|
yield {"data": json.dumps(resp)}
|
||||||
|
|
||||||
|
return EventSourceResponse(generator()) # SSE streaming
|
||||||
|
|
||||||
|
else:
|
||||||
|
response = OAIcompletions.completions(to_dict(request_data), is_legacy=is_legacy)
|
||||||
|
return JSONResponse(response)
|
||||||
|
|
||||||
|
|
||||||
|
@app.post('/v1/chat/completions', response_model=ChatCompletionResponse)
|
||||||
|
async def openai_chat_completions(request: Request, request_data: ChatCompletionRequest):
|
||||||
|
path = request.url.path
|
||||||
|
is_legacy = "/generate" in path
|
||||||
|
|
||||||
|
if request_data.stream:
|
||||||
|
async def generator():
|
||||||
|
async with streaming_semaphore:
|
||||||
|
response = OAIcompletions.stream_chat_completions(to_dict(request_data), is_legacy=is_legacy)
|
||||||
|
for resp in response:
|
||||||
|
disconnected = await request.is_disconnected()
|
||||||
|
if disconnected:
|
||||||
|
break
|
||||||
|
|
||||||
|
yield {"data": json.dumps(resp)}
|
||||||
|
|
||||||
|
return EventSourceResponse(generator()) # SSE streaming
|
||||||
|
|
||||||
|
else:
|
||||||
|
response = OAIcompletions.chat_completions(to_dict(request_data), is_legacy=is_legacy)
|
||||||
|
return JSONResponse(response)
|
||||||
|
|
||||||
|
|
||||||
|
@app.get("/v1/models")
|
||||||
|
@app.get("/v1/models/{model}")
|
||||||
|
async def handle_models(request: Request):
|
||||||
|
path = request.url.path
|
||||||
|
is_list = request.url.path.split('?')[0].split('#')[0] == '/v1/models'
|
||||||
|
|
||||||
|
if is_list:
|
||||||
|
response = OAImodels.list_models()
|
||||||
|
else:
|
||||||
|
model_name = path[len('/v1/models/'):]
|
||||||
|
response = OAImodels.model_info_dict(model_name)
|
||||||
|
|
||||||
|
return JSONResponse(response)
|
||||||
|
|
||||||
|
|
||||||
|
@app.get('/v1/billing/usage')
|
||||||
|
def handle_billing_usage():
|
||||||
|
'''
|
||||||
|
Ex. /v1/dashboard/billing/usage?start_date=2023-05-01&end_date=2023-05-31
|
||||||
|
'''
|
||||||
|
return JSONResponse(content={"total_usage": 0})
|
||||||
|
|
||||||
|
|
||||||
|
@app.post('/v1/audio/transcriptions')
|
||||||
|
async def handle_audio_transcription(request: Request):
|
||||||
|
r = sr.Recognizer()
|
||||||
|
|
||||||
|
form = await request.form()
|
||||||
|
audio_file = await form["file"].read()
|
||||||
|
audio_data = AudioSegment.from_file(audio_file)
|
||||||
|
|
||||||
|
# Convert AudioSegment to raw data
|
||||||
|
raw_data = audio_data.raw_data
|
||||||
|
|
||||||
|
# Create AudioData object
|
||||||
|
audio_data = sr.AudioData(raw_data, audio_data.frame_rate, audio_data.sample_width)
|
||||||
|
whipser_language = form.getvalue('language', None)
|
||||||
|
whipser_model = form.getvalue('model', 'tiny') # Use the model from the form data if it exists, otherwise default to tiny
|
||||||
|
|
||||||
|
transcription = {"text": ""}
|
||||||
|
|
||||||
|
try:
|
||||||
|
transcription["text"] = r.recognize_whisper(audio_data, language=whipser_language, model=whipser_model)
|
||||||
|
except sr.UnknownValueError:
|
||||||
|
print("Whisper could not understand audio")
|
||||||
|
transcription["text"] = "Whisper could not understand audio UnknownValueError"
|
||||||
|
except sr.RequestError as e:
|
||||||
|
print("Could not request results from Whisper", e)
|
||||||
|
transcription["text"] = "Whisper could not understand audio RequestError"
|
||||||
|
|
||||||
|
return JSONResponse(content=transcription)
|
||||||
|
|
||||||
|
|
||||||
|
@app.post('/v1/images/generations')
|
||||||
|
async def handle_image_generation(request: Request):
|
||||||
|
|
||||||
|
if not os.environ.get('SD_WEBUI_URL', params.get('sd_webui_url', '')):
|
||||||
|
raise ServiceUnavailableError("Stable Diffusion not available. SD_WEBUI_URL not set.")
|
||||||
|
|
||||||
|
body = await request.json()
|
||||||
|
prompt = body['prompt']
|
||||||
|
size = body.get('size', '1024x1024')
|
||||||
|
response_format = body.get('response_format', 'url') # or b64_json
|
||||||
|
n = body.get('n', 1) # ignore the batch limits of max 10
|
||||||
|
|
||||||
|
response = await OAIimages.generations(prompt=prompt, size=size, response_format=response_format, n=n)
|
||||||
|
return JSONResponse(response)
|
||||||
|
|
||||||
|
|
||||||
|
@app.post("/v1/embeddings", response_model=EmbeddingsResponse)
|
||||||
|
async def handle_embeddings(request: Request, request_data: EmbeddingsRequest):
|
||||||
|
input = request_data.input
|
||||||
|
if not input:
|
||||||
|
raise HTTPException(status_code=400, detail="Missing required argument input")
|
||||||
|
|
||||||
|
if type(input) is str:
|
||||||
|
input = [input]
|
||||||
|
|
||||||
|
response = OAIembeddings.embeddings(input, request_data.encoding_format)
|
||||||
|
return JSONResponse(response)
|
||||||
|
|
||||||
|
|
||||||
|
@app.post("/v1/moderations")
|
||||||
|
async def handle_moderations(request: Request):
|
||||||
|
body = await request.json()
|
||||||
|
input = body["input"]
|
||||||
|
if not input:
|
||||||
|
raise HTTPException(status_code=400, detail="Missing required argument input")
|
||||||
|
|
||||||
|
response = OAImoderations.moderations(input)
|
||||||
|
return JSONResponse(response)
|
||||||
|
|
||||||
|
|
||||||
|
@app.post("/v1/internal/encode", response_model=EncodeResponse)
|
||||||
|
async def handle_token_encode(request_data: EncodeRequest):
|
||||||
|
response = token_encode(request_data.text)
|
||||||
|
return JSONResponse(response)
|
||||||
|
|
||||||
|
|
||||||
|
@app.post("/v1/internal/decode", response_model=DecodeResponse)
|
||||||
|
async def handle_token_decode(request_data: DecodeRequest):
|
||||||
|
response = token_decode(request_data.tokens)
|
||||||
|
return JSONResponse(response)
|
||||||
|
|
||||||
|
|
||||||
|
@app.post("/v1/internal/token-count", response_model=TokenCountResponse)
|
||||||
|
async def handle_token_count(request_data: EncodeRequest):
|
||||||
|
response = token_count(request_data.text)
|
||||||
|
return JSONResponse(response)
|
||||||
|
|
||||||
|
|
||||||
|
@app.post("/v1/internal/stop-generation")
|
||||||
|
async def handle_stop_generation(request: Request):
|
||||||
|
stop_everything_event()
|
||||||
|
return JSONResponse(content="OK")
|
||||||
|
|
||||||
|
|
||||||
|
@app.get("/v1/internal/model/info", response_model=ModelInfoResponse)
|
||||||
|
async def handle_model_info():
|
||||||
|
payload = OAImodels.get_current_model_info()
|
||||||
|
return JSONResponse(content=payload)
|
||||||
|
|
||||||
|
|
||||||
|
@app.post("/v1/internal/model/load")
|
||||||
|
async def handle_load_model(request_data: LoadModelRequest):
|
||||||
|
'''
|
||||||
|
This endpoint is experimental and may change in the future.
|
||||||
|
|
||||||
|
The "args" parameter can be used to modify flags like "--load-in-4bit"
|
||||||
|
or "--n-gpu-layers" before loading a model. Example:
|
||||||
|
|
||||||
|
```
|
||||||
|
"args": {
|
||||||
|
"load_in_4bit": true,
|
||||||
|
"n_gpu_layers": 12
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Note that those settings will remain after loading the model. So you
|
||||||
|
may need to change them back to load a second model.
|
||||||
|
|
||||||
|
The "settings" parameter is also a dict but with keys for the
|
||||||
|
shared.settings object. It can be used to modify the default instruction
|
||||||
|
template like this:
|
||||||
|
|
||||||
|
```
|
||||||
|
"settings": {
|
||||||
|
"instruction_template": "Alpaca"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
'''
|
||||||
|
|
||||||
|
try:
|
||||||
|
OAImodels._load_model(to_dict(request_data))
|
||||||
|
return JSONResponse(content="OK")
|
||||||
|
except:
|
||||||
|
traceback.print_exc()
|
||||||
|
return HTTPException(status_code=400, detail="Failed to load the model.")
|
||||||
|
|
||||||
|
|
||||||
|
@app.post("/v1/internal/model/unload")
|
||||||
|
async def handle_unload_model():
|
||||||
|
unload_model()
|
||||||
|
return JSONResponse(content="OK")
|
||||||
|
|
||||||
|
|
||||||
|
def run_server():
|
||||||
|
server_addr = '0.0.0.0' if shared.args.listen else '127.0.0.1'
|
||||||
|
port = int(os.environ.get('OPENEDAI_PORT', shared.args.api_port))
|
||||||
|
|
||||||
|
ssl_certfile = os.environ.get('OPENEDAI_CERT_PATH', shared.args.ssl_certfile)
|
||||||
|
ssl_keyfile = os.environ.get('OPENEDAI_KEY_PATH', shared.args.ssl_keyfile)
|
||||||
|
|
||||||
|
if shared.args.public_api:
|
||||||
|
def on_start(public_url: str):
|
||||||
|
logger.info(f'OpenAI-compatible API URL:\n\n{public_url}\n')
|
||||||
|
|
||||||
|
_start_cloudflared(port, shared.args.public_api_id, max_attempts=3, on_start=on_start)
|
||||||
|
else:
|
||||||
|
if ssl_keyfile and ssl_certfile:
|
||||||
|
logger.info(f'OpenAI-compatible API URL:\n\nhttps://{server_addr}:{port}\n')
|
||||||
|
else:
|
||||||
|
logger.info(f'OpenAI-compatible API URL:\n\nhttp://{server_addr}:{port}\n')
|
||||||
|
|
||||||
|
if shared.args.api_key:
|
||||||
|
logger.info(f'OpenAI API key:\n\n{shared.args.api_key}\n')
|
||||||
|
|
||||||
|
uvicorn.run(app, host=server_addr, port=port, ssl_certfile=ssl_certfile, ssl_keyfile=ssl_keyfile)
|
||||||
|
|
||||||
|
|
||||||
|
def setup():
|
||||||
|
Thread(target=run_server, daemon=True).start()
|
||||||
@ -0,0 +1,26 @@
|
|||||||
|
from modules.text_generation import decode, encode
|
||||||
|
|
||||||
|
|
||||||
|
def token_count(prompt):
|
||||||
|
tokens = encode(prompt)[0]
|
||||||
|
return {
|
||||||
|
'length': len(tokens)
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def token_encode(input):
|
||||||
|
tokens = encode(input)[0]
|
||||||
|
if tokens.__class__.__name__ in ['Tensor', 'ndarray']:
|
||||||
|
tokens = tokens.tolist()
|
||||||
|
|
||||||
|
return {
|
||||||
|
'tokens': tokens,
|
||||||
|
'length': len(tokens),
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def token_decode(tokens):
|
||||||
|
output = decode(tokens)
|
||||||
|
return {
|
||||||
|
'text': output
|
||||||
|
}
|
||||||
@ -0,0 +1,175 @@
|
|||||||
|
import json
|
||||||
|
import time
|
||||||
|
from typing import List
|
||||||
|
|
||||||
|
from pydantic import BaseModel, Field
|
||||||
|
|
||||||
|
|
||||||
|
class GenerationOptions(BaseModel):
|
||||||
|
preset: str | None = Field(default=None, description="The name of a file under text-generation-webui/presets (without the .yaml extension). The sampling parameters that get overwritten by this option are the keys in the default_preset() function in modules/presets.py.")
|
||||||
|
min_p: float = 0
|
||||||
|
top_k: int = 0
|
||||||
|
repetition_penalty: float = 1
|
||||||
|
repetition_penalty_range: int = 0
|
||||||
|
typical_p: float = 1
|
||||||
|
tfs: float = 1
|
||||||
|
top_a: float = 0
|
||||||
|
epsilon_cutoff: float = 0
|
||||||
|
eta_cutoff: float = 0
|
||||||
|
guidance_scale: float = 1
|
||||||
|
negative_prompt: str = ''
|
||||||
|
penalty_alpha: float = 0
|
||||||
|
mirostat_mode: int = 0
|
||||||
|
mirostat_tau: float = 5
|
||||||
|
mirostat_eta: float = 0.1
|
||||||
|
temperature_last: bool = False
|
||||||
|
do_sample: bool = True
|
||||||
|
seed: int = -1
|
||||||
|
encoder_repetition_penalty: float = 1
|
||||||
|
no_repeat_ngram_size: int = 0
|
||||||
|
min_length: int = 0
|
||||||
|
num_beams: int = 1
|
||||||
|
length_penalty: float = 1
|
||||||
|
early_stopping: bool = False
|
||||||
|
truncation_length: int = 0
|
||||||
|
max_tokens_second: int = 0
|
||||||
|
custom_token_bans: str = ""
|
||||||
|
auto_max_new_tokens: bool = False
|
||||||
|
ban_eos_token: bool = False
|
||||||
|
add_bos_token: bool = True
|
||||||
|
skip_special_tokens: bool = True
|
||||||
|
grammar_string: str = ""
|
||||||
|
|
||||||
|
|
||||||
|
class CompletionRequestParams(BaseModel):
|
||||||
|
model: str | None = Field(default=None, description="Unused parameter. To change the model, use the /v1/internal/model/load endpoint.")
|
||||||
|
prompt: str | List[str]
|
||||||
|
best_of: int | None = Field(default=1, description="Unused parameter.")
|
||||||
|
echo: bool | None = False
|
||||||
|
frequency_penalty: float | None = 0
|
||||||
|
logit_bias: dict | None = None
|
||||||
|
logprobs: int | None = None
|
||||||
|
max_tokens: int | None = 16
|
||||||
|
n: int | None = Field(default=1, description="Unused parameter.")
|
||||||
|
presence_penalty: float | None = 0
|
||||||
|
stop: str | List[str] | None = None
|
||||||
|
stream: bool | None = False
|
||||||
|
suffix: str | None = None
|
||||||
|
temperature: float | None = 1
|
||||||
|
top_p: float | None = 1
|
||||||
|
user: str | None = Field(default=None, description="Unused parameter.")
|
||||||
|
|
||||||
|
|
||||||
|
class CompletionRequest(GenerationOptions, CompletionRequestParams):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class CompletionResponse(BaseModel):
|
||||||
|
id: str
|
||||||
|
choices: List[dict]
|
||||||
|
created: int = int(time.time())
|
||||||
|
model: str
|
||||||
|
object: str = "text_completion"
|
||||||
|
usage: dict
|
||||||
|
|
||||||
|
|
||||||
|
class ChatCompletionRequestParams(BaseModel):
|
||||||
|
messages: List[dict]
|
||||||
|
model: str | None = Field(default=None, description="Unused parameter. To change the model, use the /v1/internal/model/load endpoint.")
|
||||||
|
frequency_penalty: float | None = 0
|
||||||
|
function_call: str | dict | None = Field(default=None, description="Unused parameter.")
|
||||||
|
functions: List[dict] | None = Field(default=None, description="Unused parameter.")
|
||||||
|
logit_bias: dict | None = None
|
||||||
|
max_tokens: int | None = None
|
||||||
|
n: int | None = Field(default=1, description="Unused parameter.")
|
||||||
|
presence_penalty: float | None = 0
|
||||||
|
stop: str | List[str] | None = None
|
||||||
|
stream: bool | None = False
|
||||||
|
temperature: float | None = 1
|
||||||
|
top_p: float | None = 1
|
||||||
|
user: str | None = Field(default=None, description="Unused parameter.")
|
||||||
|
|
||||||
|
mode: str = Field(default='instruct', description="Valid options: instruct, chat, chat-instruct.")
|
||||||
|
|
||||||
|
instruction_template: str | None = Field(default=None, description="An instruction template defined under text-generation-webui/instruction-templates. If not set, the correct template will be guessed using the regex expressions in models/config.yaml.")
|
||||||
|
turn_template: str | None = Field(default=None, description="Overwrites the value set by instruction_template.")
|
||||||
|
name1_instruct: str | None = Field(default=None, description="Overwrites the value set by instruction_template.")
|
||||||
|
name2_instruct: str | None = Field(default=None, description="Overwrites the value set by instruction_template.")
|
||||||
|
context_instruct: str | None = Field(default=None, description="Overwrites the value set by instruction_template.")
|
||||||
|
system_message: str | None = Field(default=None, description="Overwrites the value set by instruction_template.")
|
||||||
|
|
||||||
|
character: str | None = Field(default=None, description="A character defined under text-generation-webui/characters. If not set, the default \"Assistant\" character will be used.")
|
||||||
|
name1: str | None = Field(default=None, description="Your name (the user). By default, it's \"You\".")
|
||||||
|
name2: str | None = Field(default=None, description="Overwrites the value set by character.")
|
||||||
|
context: str | None = Field(default=None, description="Overwrites the value set by character.")
|
||||||
|
greeting: str | None = Field(default=None, description="Overwrites the value set by character.")
|
||||||
|
|
||||||
|
chat_instruct_command: str | None = None
|
||||||
|
|
||||||
|
continue_: bool = Field(default=False, description="Makes the last bot message in the history be continued instead of starting a new message.")
|
||||||
|
|
||||||
|
|
||||||
|
class ChatCompletionRequest(GenerationOptions, ChatCompletionRequestParams):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class ChatCompletionResponse(BaseModel):
|
||||||
|
id: str
|
||||||
|
choices: List[dict]
|
||||||
|
created: int = int(time.time())
|
||||||
|
model: str
|
||||||
|
object: str = "chat.completion"
|
||||||
|
usage: dict
|
||||||
|
|
||||||
|
|
||||||
|
class EncodeRequest(BaseModel):
|
||||||
|
text: str
|
||||||
|
|
||||||
|
|
||||||
|
class DecodeRequest(BaseModel):
|
||||||
|
tokens: List[int]
|
||||||
|
|
||||||
|
|
||||||
|
class EncodeResponse(BaseModel):
|
||||||
|
tokens: List[int]
|
||||||
|
length: int
|
||||||
|
|
||||||
|
|
||||||
|
class DecodeResponse(BaseModel):
|
||||||
|
text: str
|
||||||
|
|
||||||
|
|
||||||
|
class TokenCountResponse(BaseModel):
|
||||||
|
length: int
|
||||||
|
|
||||||
|
|
||||||
|
class ModelInfoResponse(BaseModel):
|
||||||
|
model_name: str
|
||||||
|
lora_names: List[str]
|
||||||
|
|
||||||
|
|
||||||
|
class LoadModelRequest(BaseModel):
|
||||||
|
model_name: str
|
||||||
|
args: dict | None = None
|
||||||
|
settings: dict | None = None
|
||||||
|
|
||||||
|
|
||||||
|
class EmbeddingsRequest(BaseModel):
|
||||||
|
input: str | List[str]
|
||||||
|
model: str | None = Field(default=None, description="Unused parameter. To change the model, set the OPENEDAI_EMBEDDING_MODEL and OPENEDAI_EMBEDDING_DEVICE environment variables before starting the server.")
|
||||||
|
encoding_format: str = Field(default="float", description="Can be float or base64.")
|
||||||
|
user: str | None = Field(default=None, description="Unused parameter.")
|
||||||
|
|
||||||
|
|
||||||
|
class EmbeddingsResponse(BaseModel):
|
||||||
|
index: int
|
||||||
|
embedding: List[float]
|
||||||
|
object: str = "embedding"
|
||||||
|
|
||||||
|
|
||||||
|
def to_json(obj):
|
||||||
|
return json.dumps(obj.__dict__, indent=4)
|
||||||
|
|
||||||
|
|
||||||
|
def to_dict(obj):
|
||||||
|
return obj.__dict__
|
||||||
@ -0,0 +1,54 @@
|
|||||||
|
import base64
|
||||||
|
import os
|
||||||
|
import time
|
||||||
|
import traceback
|
||||||
|
from typing import Callable, Optional
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
|
||||||
|
def float_list_to_base64(float_array: np.ndarray) -> str:
|
||||||
|
# Convert the list to a float32 array that the OpenAPI client expects
|
||||||
|
# float_array = np.array(float_list, dtype="float32")
|
||||||
|
|
||||||
|
# Get raw bytes
|
||||||
|
bytes_array = float_array.tobytes()
|
||||||
|
|
||||||
|
# Encode bytes into base64
|
||||||
|
encoded_bytes = base64.b64encode(bytes_array)
|
||||||
|
|
||||||
|
# Turn raw base64 encoded bytes into ASCII
|
||||||
|
ascii_string = encoded_bytes.decode('ascii')
|
||||||
|
return ascii_string
|
||||||
|
|
||||||
|
|
||||||
|
def debug_msg(*args, **kwargs):
|
||||||
|
from extensions.openai.script import params
|
||||||
|
if os.environ.get("OPENEDAI_DEBUG", params.get('debug', 0)):
|
||||||
|
print(*args, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def _start_cloudflared(port: int, tunnel_id: str, max_attempts: int = 3, on_start: Optional[Callable[[str], None]] = None):
|
||||||
|
try:
|
||||||
|
from flask_cloudflared import _run_cloudflared
|
||||||
|
except ImportError:
|
||||||
|
print('You should install flask_cloudflared manually')
|
||||||
|
raise Exception(
|
||||||
|
'flask_cloudflared not installed. Make sure you installed the requirements.txt for this extension.')
|
||||||
|
|
||||||
|
for _ in range(max_attempts):
|
||||||
|
try:
|
||||||
|
if tunnel_id is not None:
|
||||||
|
public_url = _run_cloudflared(port, port + 1, tunnel_id=tunnel_id)
|
||||||
|
else:
|
||||||
|
public_url = _run_cloudflared(port, port + 1)
|
||||||
|
|
||||||
|
if on_start:
|
||||||
|
on_start(public_url)
|
||||||
|
|
||||||
|
return
|
||||||
|
except Exception:
|
||||||
|
traceback.print_exc()
|
||||||
|
time.sleep(3)
|
||||||
|
|
||||||
|
raise Exception('Could not start cloudflared.')
|
||||||
@ -0,0 +1,309 @@
|
|||||||
|
import time
|
||||||
|
|
||||||
|
import gradio
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
from transformers import LogitsProcessor
|
||||||
|
|
||||||
|
from modules import html_generator, shared
|
||||||
|
|
||||||
|
params = {
|
||||||
|
'active': True,
|
||||||
|
'color_by_perplexity': False,
|
||||||
|
'color_by_probability': False,
|
||||||
|
'ppl_scale': 15.0, # No slider for this right now, because I don't think it really needs to be changed. Very large perplexity scores don't show up often.
|
||||||
|
'probability_dropdown': False,
|
||||||
|
'verbose': False # For debugging mostly
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
class PerplexityLogits(LogitsProcessor):
|
||||||
|
def __init__(self, verbose=False):
|
||||||
|
self.generated_token_ids = []
|
||||||
|
self.selected_probs = []
|
||||||
|
self.top_token_ids_list = []
|
||||||
|
self.top_probs_list = []
|
||||||
|
self.perplexities_list = []
|
||||||
|
self.last_probs = None
|
||||||
|
self.verbose = verbose
|
||||||
|
|
||||||
|
def __call__(self, input_ids, scores):
|
||||||
|
# t0 = time.time()
|
||||||
|
probs = torch.softmax(scores, dim=-1, dtype=torch.float)
|
||||||
|
log_probs = torch.nan_to_num(torch.log(probs)) # Note: This is to convert log(0) nan to 0, but probs*log_probs makes this 0 not affect the perplexity.
|
||||||
|
entropy = -torch.sum(probs * log_probs)
|
||||||
|
entropy = entropy.cpu().numpy()
|
||||||
|
perplexity = round(float(np.exp(entropy)), 4)
|
||||||
|
self.perplexities_list.append(perplexity)
|
||||||
|
last_token_id = int(input_ids[0][-1].cpu().numpy().item())
|
||||||
|
# Store the generated tokens (not sure why this isn't accessible in the output endpoint!)
|
||||||
|
self.generated_token_ids.append(last_token_id)
|
||||||
|
# Get last probability, and add to the list if it wasn't there
|
||||||
|
if len(self.selected_probs) > 0:
|
||||||
|
# Is the selected token in the top tokens?
|
||||||
|
if self.verbose:
|
||||||
|
print('Probs: Token after', shared.tokenizer.decode(last_token_id))
|
||||||
|
print('Probs:', [shared.tokenizer.decode(token_id) for token_id in self.top_token_ids_list[-1][0]])
|
||||||
|
print('Probs:', [round(float(prob), 4) for prob in self.top_probs_list[-1][0]])
|
||||||
|
if last_token_id in self.top_token_ids_list[-1][0]:
|
||||||
|
idx = self.top_token_ids_list[-1][0].index(last_token_id)
|
||||||
|
self.selected_probs.append(self.top_probs_list[-1][0][idx])
|
||||||
|
else:
|
||||||
|
self.top_token_ids_list[-1][0].append(last_token_id)
|
||||||
|
last_prob = round(float(self.last_probs[last_token_id]), 4)
|
||||||
|
self.top_probs_list[-1][0].append(last_prob)
|
||||||
|
self.selected_probs.append(last_prob)
|
||||||
|
else:
|
||||||
|
self.selected_probs.append(1.0) # Placeholder for the last token of the prompt
|
||||||
|
|
||||||
|
if self.verbose:
|
||||||
|
pplbar = "-"
|
||||||
|
if not np.isnan(perplexity):
|
||||||
|
pplbar = "*" * round(perplexity)
|
||||||
|
print(f"PPL: Token after {shared.tokenizer.decode(last_token_id)}\t{perplexity:.2f}\t{pplbar}")
|
||||||
|
|
||||||
|
# Get top 5 probabilities
|
||||||
|
top_tokens_and_probs = torch.topk(probs, 5)
|
||||||
|
top_probs = top_tokens_and_probs.values.cpu().numpy().astype(float).tolist()
|
||||||
|
top_token_ids = top_tokens_and_probs.indices.cpu().numpy().astype(int).tolist()
|
||||||
|
|
||||||
|
self.top_token_ids_list.append(top_token_ids)
|
||||||
|
self.top_probs_list.append(top_probs)
|
||||||
|
|
||||||
|
probs = probs.cpu().numpy().flatten()
|
||||||
|
self.last_probs = probs # Need to keep this as a reference for top probs
|
||||||
|
|
||||||
|
# t1 = time.time()
|
||||||
|
# print(f"PPL Processor: {(t1-t0):.3f} s")
|
||||||
|
# About 1 ms, though occasionally up to around 100 ms, not sure why...
|
||||||
|
# Doesn't actually modify the logits!
|
||||||
|
return scores
|
||||||
|
|
||||||
|
|
||||||
|
# Stores the perplexity and top probabilities
|
||||||
|
ppl_logits_processor = None
|
||||||
|
|
||||||
|
|
||||||
|
def logits_processor_modifier(logits_processor_list, input_ids):
|
||||||
|
global ppl_logits_processor
|
||||||
|
if params['active']:
|
||||||
|
ppl_logits_processor = PerplexityLogits(verbose=params['verbose'])
|
||||||
|
logits_processor_list.append(ppl_logits_processor)
|
||||||
|
|
||||||
|
|
||||||
|
def output_modifier(text):
|
||||||
|
global ppl_logits_processor
|
||||||
|
# t0 = time.time()
|
||||||
|
|
||||||
|
if not params['active']:
|
||||||
|
return text
|
||||||
|
|
||||||
|
# TODO: It's probably more efficient to do this above rather than modifying all these lists
|
||||||
|
# Remove last element of perplexities_list, top_token_ids_list, top_tokens_list, top_probs_list since everything is off by one because this extension runs before generation
|
||||||
|
perplexities = ppl_logits_processor.perplexities_list[:-1]
|
||||||
|
top_token_ids_list = ppl_logits_processor.top_token_ids_list[:-1]
|
||||||
|
top_tokens_list = [[shared.tokenizer.decode(token_id) for token_id in top_token_ids[0]] for top_token_ids in top_token_ids_list]
|
||||||
|
top_probs_list = ppl_logits_processor.top_probs_list[:-1]
|
||||||
|
# Remove first element of generated_token_ids, generated_tokens, selected_probs because they are for the last token of the prompt
|
||||||
|
gen_token_ids = ppl_logits_processor.generated_token_ids[1:]
|
||||||
|
gen_tokens = [shared.tokenizer.decode(token_id) for token_id in gen_token_ids]
|
||||||
|
sel_probs = ppl_logits_processor.selected_probs[1:]
|
||||||
|
|
||||||
|
end_part = '</div></div>' if params['probability_dropdown'] else '</span>' # Helps with finding the index after replacing part of the text.
|
||||||
|
|
||||||
|
i = 0
|
||||||
|
for token, prob, ppl, top_tokens, top_probs in zip(gen_tokens, sel_probs, perplexities, top_tokens_list, top_probs_list):
|
||||||
|
color = 'ffffff'
|
||||||
|
if params['color_by_probability'] and params['color_by_perplexity']:
|
||||||
|
color = probability_perplexity_color_scale(prob, ppl)
|
||||||
|
elif params['color_by_perplexity']:
|
||||||
|
color = perplexity_color_scale(ppl)
|
||||||
|
elif params['color_by_probability']:
|
||||||
|
color = probability_color_scale(prob)
|
||||||
|
if token in text[i:]:
|
||||||
|
if params['probability_dropdown']:
|
||||||
|
text = text[:i] + text[i:].replace(token, add_dropdown_html(token, color, top_tokens, top_probs[0], ppl), 1)
|
||||||
|
else:
|
||||||
|
text = text[:i] + text[i:].replace(token, add_color_html(token, color), 1)
|
||||||
|
i += text[i:].find(end_part) + len(end_part)
|
||||||
|
|
||||||
|
# Use full perplexity list for calculating the average here.
|
||||||
|
print('Average perplexity:', round(np.mean(ppl_logits_processor.perplexities_list[:-1]), 4))
|
||||||
|
# t1 = time.time()
|
||||||
|
# print(f"Modifier: {(t1-t0):.3f} s")
|
||||||
|
# About 50 ms
|
||||||
|
return text
|
||||||
|
|
||||||
|
|
||||||
|
def probability_color_scale(prob):
|
||||||
|
'''
|
||||||
|
Green-yellow-red color scale
|
||||||
|
'''
|
||||||
|
|
||||||
|
rv = 0
|
||||||
|
gv = 0
|
||||||
|
if prob <= 0.5:
|
||||||
|
rv = 'ff'
|
||||||
|
gv = hex(int(255 * prob * 2))[2:]
|
||||||
|
if len(gv) < 2:
|
||||||
|
gv = '0' * (2 - len(gv)) + gv
|
||||||
|
else:
|
||||||
|
rv = hex(int(255 - 255 * (prob - 0.5) * 2))[2:]
|
||||||
|
gv = 'ff'
|
||||||
|
if len(rv) < 2:
|
||||||
|
rv = '0' * (2 - len(rv)) + rv
|
||||||
|
|
||||||
|
return rv + gv + '00'
|
||||||
|
|
||||||
|
|
||||||
|
def perplexity_color_scale(ppl):
|
||||||
|
'''
|
||||||
|
Red component only, white for 0 perplexity (sorry if you're not in dark mode)
|
||||||
|
'''
|
||||||
|
value = hex(max(int(255.0 - params['ppl_scale'] * (float(ppl) - 1.0)), 0))[2:]
|
||||||
|
if len(value) < 2:
|
||||||
|
value = '0' * (2 - len(value)) + value
|
||||||
|
|
||||||
|
return 'ff' + value + value
|
||||||
|
|
||||||
|
|
||||||
|
def probability_perplexity_color_scale(prob, ppl):
|
||||||
|
'''
|
||||||
|
Green-yellow-red for probability and blue component for perplexity
|
||||||
|
'''
|
||||||
|
|
||||||
|
rv = 0
|
||||||
|
gv = 0
|
||||||
|
bv = hex(min(max(int(params['ppl_scale'] * (float(ppl) - 1.0)), 0), 255))[2:]
|
||||||
|
if len(bv) < 2:
|
||||||
|
bv = '0' * (2 - len(bv)) + bv
|
||||||
|
|
||||||
|
if prob <= 0.5:
|
||||||
|
rv = 'ff'
|
||||||
|
gv = hex(int(255 * prob * 2))[2:]
|
||||||
|
if len(gv) < 2:
|
||||||
|
gv = '0' * (2 - len(gv)) + gv
|
||||||
|
else:
|
||||||
|
rv = hex(int(255 - 255 * (prob - 0.5) * 2))[2:]
|
||||||
|
gv = 'ff'
|
||||||
|
if len(rv) < 2:
|
||||||
|
rv = '0' * (2 - len(rv)) + rv
|
||||||
|
|
||||||
|
return rv + gv + bv
|
||||||
|
|
||||||
|
|
||||||
|
def add_color_html(token, color):
|
||||||
|
return f'<span style="color: #{color}">{token}</span>'
|
||||||
|
|
||||||
|
|
||||||
|
# TODO: Major issue: Applying this to too many tokens will cause a permanent slowdown in generation speed until the messages are removed from the history.
|
||||||
|
# I think the issue is from HTML elements taking up space in the visible history, and things like history deepcopy add latency proportional to the size of the history.
|
||||||
|
# Potential solution is maybe to modify the main generation code to send just the internal text and not the visible history, to avoid moving too much around.
|
||||||
|
# I wonder if we can also avoid using deepcopy here.
|
||||||
|
def add_dropdown_html(token, color, top_tokens, top_probs, perplexity=0):
|
||||||
|
html = f'<div class="hoverable"><span style="color: #{color}">{token}</span><div class="dropdown"><table class="dropdown-content"><tbody>'
|
||||||
|
for token_option, prob in zip(top_tokens, top_probs):
|
||||||
|
# TODO: Bold for selected token?
|
||||||
|
# Using divs prevented the problem of divs inside spans causing issues.
|
||||||
|
# Now the problem is that divs show the same whitespace of one space between every token.
|
||||||
|
# There is probably some way to fix this in CSS that I don't know about.
|
||||||
|
row_color = probability_color_scale(prob)
|
||||||
|
row_class = ' class="selected"' if token_option == token else ''
|
||||||
|
html += f'<tr{row_class}><td style="color: #{row_color}">{token_option}</td><td style="color: #{row_color}">{prob:.4f}</td></tr>'
|
||||||
|
if perplexity != 0:
|
||||||
|
ppl_color = perplexity_color_scale(perplexity)
|
||||||
|
html += f'<tr><td>Perplexity:</td><td style="color: #{ppl_color}">{perplexity:.4f}</td></tr>'
|
||||||
|
html += '</tbody></table></div></div>'
|
||||||
|
return html # About 750 characters per token...
|
||||||
|
|
||||||
|
|
||||||
|
def custom_css():
|
||||||
|
return """
|
||||||
|
.dropdown {
|
||||||
|
display: none;
|
||||||
|
position: absolute;
|
||||||
|
z-index: 50;
|
||||||
|
background-color: var(--block-background-fill);
|
||||||
|
box-shadow: 0px 8px 16px 0px rgba(0,0,0,0.2);
|
||||||
|
width: max-content;
|
||||||
|
overflow: visible;
|
||||||
|
padding: 5px;
|
||||||
|
border-radius: 10px;
|
||||||
|
border: 1px solid var(--border-color-primary);
|
||||||
|
}
|
||||||
|
|
||||||
|
.dropdown-content {
|
||||||
|
border: none;
|
||||||
|
z-index: 50;
|
||||||
|
}
|
||||||
|
|
||||||
|
.dropdown-content tr.selected {
|
||||||
|
background-color: var(--block-label-background-fill);
|
||||||
|
}
|
||||||
|
|
||||||
|
.dropdown-content td {
|
||||||
|
color: var(--body-text-color);
|
||||||
|
}
|
||||||
|
|
||||||
|
.hoverable {
|
||||||
|
color: var(--body-text-color);
|
||||||
|
position: relative;
|
||||||
|
display: inline-block;
|
||||||
|
overflow: visible;
|
||||||
|
font-size: 15px;
|
||||||
|
line-height: 1.75;
|
||||||
|
margin: 0;
|
||||||
|
padding: 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
.hoverable:hover .dropdown {
|
||||||
|
display: block;
|
||||||
|
}
|
||||||
|
|
||||||
|
pre {
|
||||||
|
white-space: pre-wrap;
|
||||||
|
}
|
||||||
|
|
||||||
|
# TODO: This makes the hover menus extend outside the bounds of the chat area, which is good.
|
||||||
|
# However, it also makes the scrollbar disappear, which is bad.
|
||||||
|
# The scroll bar needs to still be present. So for now, we can't see dropdowns that extend past the edge of the chat area.
|
||||||
|
#.chat {
|
||||||
|
# overflow-y: auto;
|
||||||
|
#}
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
# Monkeypatch applied to html_generator.py
|
||||||
|
# We simply don't render markdown into HTML. We wrap everything in <pre> tags to preserve whitespace
|
||||||
|
# formatting. If you're coloring tokens by perplexity or probability, or especially if you're using
|
||||||
|
# the probability dropdown, you probably care more about seeing the tokens the model actually outputted
|
||||||
|
# rather than rendering ```code blocks``` or *italics*.
|
||||||
|
def convert_to_markdown(string):
|
||||||
|
return '<pre>' + string + '</pre>'
|
||||||
|
|
||||||
|
|
||||||
|
html_generator.convert_to_markdown = convert_to_markdown
|
||||||
|
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
def update_active_check(x):
|
||||||
|
params.update({'active': x})
|
||||||
|
|
||||||
|
def update_color_by_ppl_check(x):
|
||||||
|
params.update({'color_by_perplexity': x})
|
||||||
|
|
||||||
|
def update_color_by_prob_check(x):
|
||||||
|
params.update({'color_by_probability': x})
|
||||||
|
|
||||||
|
def update_prob_dropdown_check(x):
|
||||||
|
params.update({'probability_dropdown': x})
|
||||||
|
|
||||||
|
active_check = gradio.Checkbox(value=True, label="Compute probabilities and perplexity scores", info="Activate this extension. Note that this extension currently does not work with exllama or llama.cpp.")
|
||||||
|
color_by_ppl_check = gradio.Checkbox(value=False, label="Color by perplexity", info="Higher perplexity is more red. If also showing probability, higher perplexity has more blue component.")
|
||||||
|
color_by_prob_check = gradio.Checkbox(value=False, label="Color by probability", info="Green-yellow-red linear scale, with 100% green, 50% yellow, 0% red.")
|
||||||
|
prob_dropdown_check = gradio.Checkbox(value=False, label="Probability dropdown", info="Hover over a token to show a dropdown of top token probabilities. Currently slightly buggy with whitespace between tokens.")
|
||||||
|
|
||||||
|
active_check.change(update_active_check, active_check, None)
|
||||||
|
color_by_ppl_check.change(update_color_by_ppl_check, color_by_ppl_check, None)
|
||||||
|
color_by_prob_check.change(update_color_by_prob_check, color_by_prob_check, None)
|
||||||
|
prob_dropdown_check.change(update_prob_dropdown_check, prob_dropdown_check, None)
|
||||||
@ -0,0 +1,90 @@
|
|||||||
|
## Description:
|
||||||
|
TL;DR: Lets the bot answer you with a picture!
|
||||||
|
|
||||||
|
Stable Diffusion API pictures for TextGen, v.1.2.0
|
||||||
|
An extension to [oobabooga's textgen-webui](https://github.com/oobabooga/text-generation-webui) allowing you to receive pics generated by [Automatic1111's SD-WebUI API](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
|
||||||
|
|
||||||
|
<details>
|
||||||
|
<summary>Interface overview</summary>
|
||||||
|
|
||||||
|
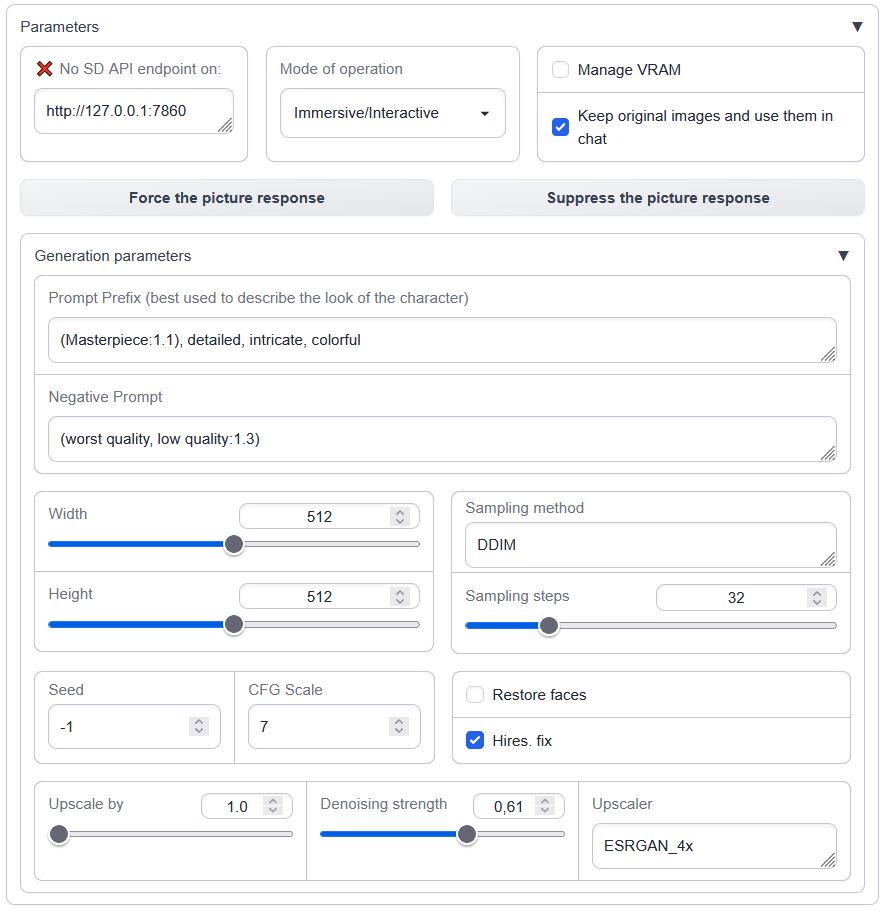
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
Load it in the `--chat` mode with `--extension sd_api_pictures` alongside `send_pictures`
|
||||||
|
(it's not really required, but completes the picture, *pun intended*).
|
||||||
|
|
||||||
|
|
||||||
|
## History
|
||||||
|
|
||||||
|
Consider the version included with [oobabooga's repository](https://github.com/oobabooga/text-generation-webui/tree/main/extensions/sd_api_pictures) to be STABLE, experimental developments and untested features are pushed in [Brawlence/SD_api_pics](https://github.com/Brawlence/SD_api_pics)
|
||||||
|
|
||||||
|
Lastest change:
|
||||||
|
1.1.0 → 1.1.1 Fixed not having Auto1111's metadata in received images
|
||||||
|
|
||||||
|
## Details
|
||||||
|
|
||||||
|
The image generation is triggered:
|
||||||
|
- manually through the 'Force the picture response' button while in `Manual` or `Immersive/Interactive` modes OR
|
||||||
|
- automatically in `Immersive/Interactive` mode if the words `'send|main|message|me'` are followed by `'image|pic|picture|photo|snap|snapshot|selfie|meme'` in the user's prompt
|
||||||
|
- always on in `Picturebook/Adventure` mode (if not currently suppressed by 'Suppress the picture response')
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
One needs an available instance of Automatic1111's webui running with an `--api` flag. Ain't tested with a notebook / cloud hosted one but should be possible.
|
||||||
|
To run it locally in parallel on the same machine, specify custom `--listen-port` for either Auto1111's or ooba's webUIs.
|
||||||
|
|
||||||
|
## Features overview
|
||||||
|
- Connection to API check (press enter in the address box)
|
||||||
|
- [VRAM management (model shuffling)](https://github.com/Brawlence/SD_api_pics/wiki/VRAM-management-feature)
|
||||||
|
- [Three different operation modes](https://github.com/Brawlence/SD_api_pics/wiki/Modes-of-operation) (manual, interactive, always-on)
|
||||||
|
- User-defined persistent settings via settings.json
|
||||||
|
|
||||||
|
### Connection check
|
||||||
|
|
||||||
|
Insert the Automatic1111's WebUI address and press Enter:
|
||||||
|
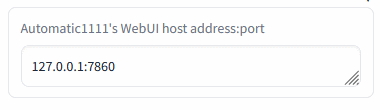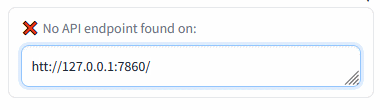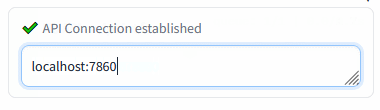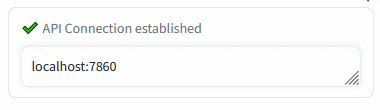
|
||||||
|
Green mark confirms the ability to communicate with Auto1111's API on this address. Red cross means something's not right (the ext won't work).
|
||||||
|
|
||||||
|
### Persistents settings
|
||||||
|
|
||||||
|
Create or modify the `settings.json` in the `text-generation-webui` root directory to override the defaults
|
||||||
|
present in script.py, ex:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"sd_api_pictures-manage_VRAM": 1,
|
||||||
|
"sd_api_pictures-save_img": 1,
|
||||||
|
"sd_api_pictures-prompt_prefix": "(Masterpiece:1.1), detailed, intricate, colorful, (solo:1.1)",
|
||||||
|
"sd_api_pictures-sampler_name": "DPM++ 2M Karras"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
will automatically set the `Manage VRAM` & `Keep original images` checkboxes and change the texts in `Prompt Prefix` and `Sampler name` on load.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Demonstrations:
|
||||||
|
|
||||||
|
Those are examples of the version 1.0.0, but the core functionality is still the same
|
||||||
|
|
||||||
|
<details>
|
||||||
|
<summary>Conversation 1</summary>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
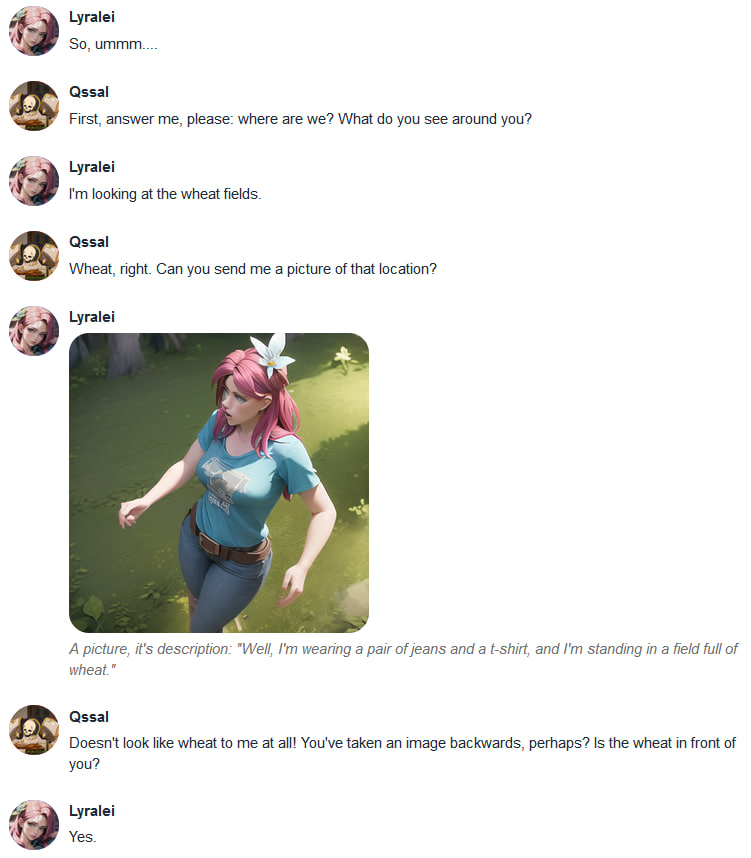
|
||||||
|
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details>
|
||||||
|
<summary>Conversation 2</summary>
|
||||||
|
|
||||||
|
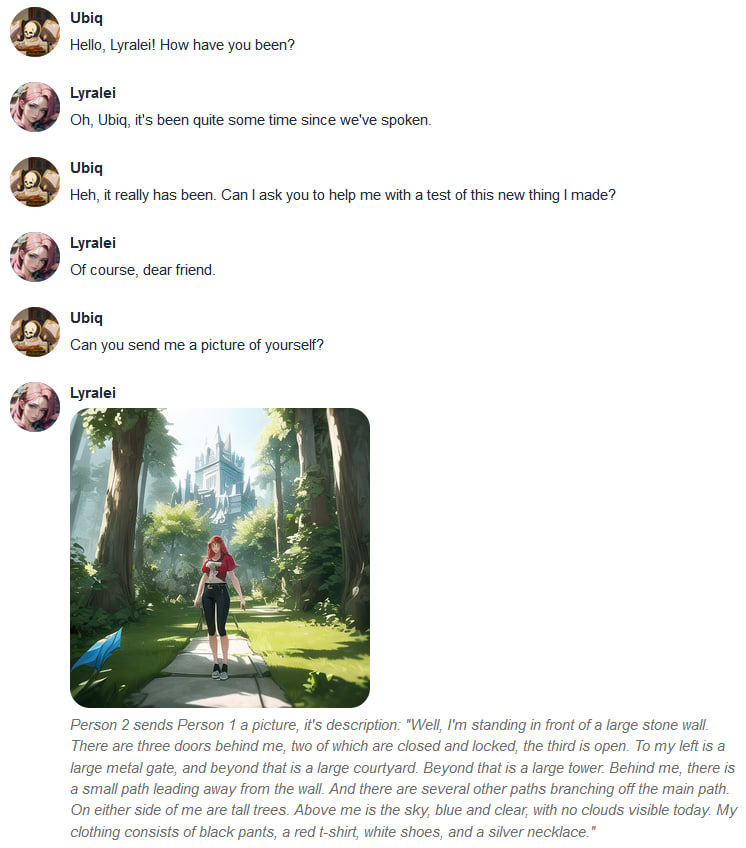
|
||||||
|
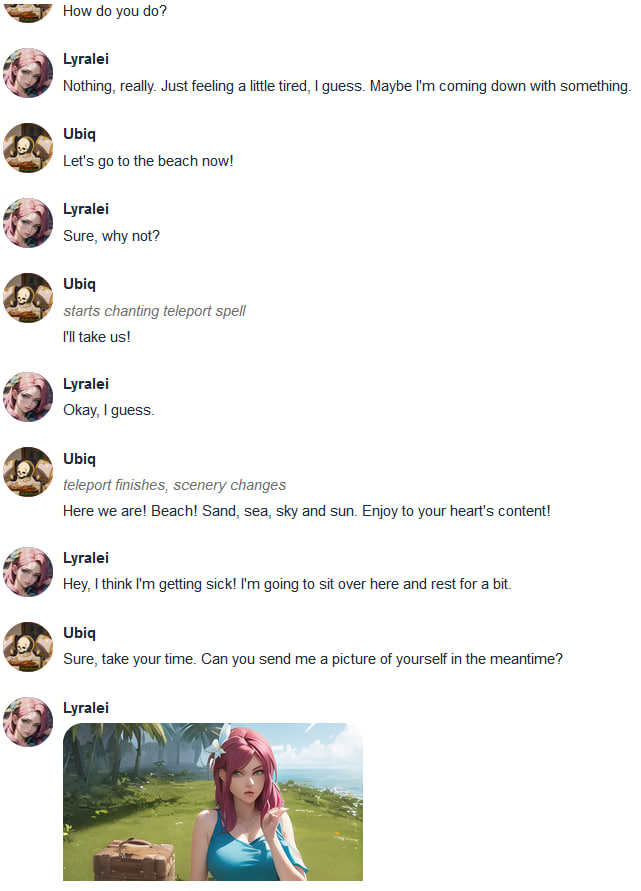
|
||||||
|
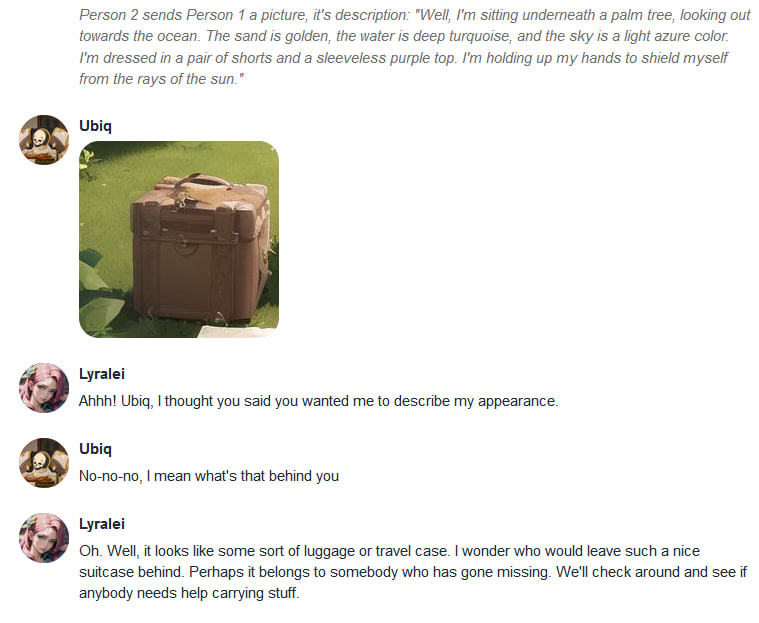
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
@ -0,0 +1,386 @@
|
|||||||
|
import base64
|
||||||
|
import io
|
||||||
|
import re
|
||||||
|
import time
|
||||||
|
from datetime import date
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import gradio as gr
|
||||||
|
import requests
|
||||||
|
import torch
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
|
from modules import shared
|
||||||
|
from modules.models import reload_model, unload_model
|
||||||
|
from modules.ui import create_refresh_button
|
||||||
|
|
||||||
|
torch._C._jit_set_profiling_mode(False)
|
||||||
|
|
||||||
|
# parameters which can be customized in settings.json of webui
|
||||||
|
params = {
|
||||||
|
'address': 'http://127.0.0.1:7860',
|
||||||
|
'mode': 0, # modes of operation: 0 (Manual only), 1 (Immersive/Interactive - looks for words to trigger), 2 (Picturebook Adventure - Always on)
|
||||||
|
'manage_VRAM': False,
|
||||||
|
'save_img': False,
|
||||||
|
'SD_model': 'NeverEndingDream', # not used right now
|
||||||
|
'prompt_prefix': '(Masterpiece:1.1), detailed, intricate, colorful',
|
||||||
|
'negative_prompt': '(worst quality, low quality:1.3)',
|
||||||
|
'width': 512,
|
||||||
|
'height': 512,
|
||||||
|
'denoising_strength': 0.61,
|
||||||
|
'restore_faces': False,
|
||||||
|
'enable_hr': False,
|
||||||
|
'hr_upscaler': 'ESRGAN_4x',
|
||||||
|
'hr_scale': '1.0',
|
||||||
|
'seed': -1,
|
||||||
|
'sampler_name': 'DPM++ 2M Karras',
|
||||||
|
'steps': 32,
|
||||||
|
'cfg_scale': 7,
|
||||||
|
'textgen_prefix': 'Please provide a detailed and vivid description of [subject]',
|
||||||
|
'sd_checkpoint': ' ',
|
||||||
|
'checkpoint_list': [" "]
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def give_VRAM_priority(actor):
|
||||||
|
global shared, params
|
||||||
|
|
||||||
|
if actor == 'SD':
|
||||||
|
unload_model()
|
||||||
|
print("Requesting Auto1111 to re-load last checkpoint used...")
|
||||||
|
response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
|
||||||
|
response.raise_for_status()
|
||||||
|
|
||||||
|
elif actor == 'LLM':
|
||||||
|
print("Requesting Auto1111 to vacate VRAM...")
|
||||||
|
response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
|
||||||
|
response.raise_for_status()
|
||||||
|
reload_model()
|
||||||
|
|
||||||
|
elif actor == 'set':
|
||||||
|
print("VRAM mangement activated -- requesting Auto1111 to vacate VRAM...")
|
||||||
|
response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
|
||||||
|
response.raise_for_status()
|
||||||
|
|
||||||
|
elif actor == 'reset':
|
||||||
|
print("VRAM mangement deactivated -- requesting Auto1111 to reload checkpoint")
|
||||||
|
response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
|
||||||
|
response.raise_for_status()
|
||||||
|
|
||||||
|
else:
|
||||||
|
raise RuntimeError(f'Managing VRAM: "{actor}" is not a known state!')
|
||||||
|
|
||||||
|
response.raise_for_status()
|
||||||
|
del response
|
||||||
|
|
||||||
|
|
||||||
|
if params['manage_VRAM']:
|
||||||
|
give_VRAM_priority('set')
|
||||||
|
|
||||||
|
SD_models = ['NeverEndingDream'] # TODO: get with http://{address}}/sdapi/v1/sd-models and allow user to select
|
||||||
|
|
||||||
|
picture_response = False # specifies if the next model response should appear as a picture
|
||||||
|
|
||||||
|
|
||||||
|
def remove_surrounded_chars(string):
|
||||||
|
# this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
|
||||||
|
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
||||||
|
return re.sub('\*[^\*]*?(\*|$)', '', string)
|
||||||
|
|
||||||
|
|
||||||
|
def triggers_are_in(string):
|
||||||
|
string = remove_surrounded_chars(string)
|
||||||
|
# regex searches for send|main|message|me (at the end of the word) followed by
|
||||||
|
# a whole word of image|pic|picture|photo|snap|snapshot|selfie|meme(s),
|
||||||
|
# (?aims) are regex parser flags
|
||||||
|
return bool(re.search('(?aims)(send|mail|message|me)\\b.+?\\b(image|pic(ture)?|photo|snap(shot)?|selfie|meme)s?\\b', string))
|
||||||
|
|
||||||
|
|
||||||
|
def state_modifier(state):
|
||||||
|
if picture_response:
|
||||||
|
state['stream'] = False
|
||||||
|
|
||||||
|
return state
|
||||||
|
|
||||||
|
|
||||||
|
def input_modifier(string):
|
||||||
|
"""
|
||||||
|
This function is applied to your text inputs before
|
||||||
|
they are fed into the model.
|
||||||
|
"""
|
||||||
|
|
||||||
|
global params
|
||||||
|
|
||||||
|
if not params['mode'] == 1: # if not in immersive/interactive mode, do nothing
|
||||||
|
return string
|
||||||
|
|
||||||
|
if triggers_are_in(string): # if we're in it, check for trigger words
|
||||||
|
toggle_generation(True)
|
||||||
|
string = string.lower()
|
||||||
|
if "of" in string:
|
||||||
|
subject = string.split('of', 1)[1] # subdivide the string once by the first 'of' instance and get what's coming after it
|
||||||
|
string = params['textgen_prefix'].replace("[subject]", subject)
|
||||||
|
else:
|
||||||
|
string = params['textgen_prefix'].replace("[subject]", "your appearance, your surroundings and what you are doing right now")
|
||||||
|
|
||||||
|
return string
|
||||||
|
|
||||||
|
# Get and save the Stable Diffusion-generated picture
|
||||||
|
def get_SD_pictures(description, character):
|
||||||
|
|
||||||
|
global params
|
||||||
|
|
||||||
|
if params['manage_VRAM']:
|
||||||
|
give_VRAM_priority('SD')
|
||||||
|
|
||||||
|
description = re.sub('<audio.*?</audio>', ' ', description)
|
||||||
|
description = f"({description}:1)"
|
||||||
|
|
||||||
|
payload = {
|
||||||
|
"prompt": params['prompt_prefix'] + description,
|
||||||
|
"seed": params['seed'],
|
||||||
|
"sampler_name": params['sampler_name'],
|
||||||
|
"enable_hr": params['enable_hr'],
|
||||||
|
"hr_scale": params['hr_scale'],
|
||||||
|
"hr_upscaler": params['hr_upscaler'],
|
||||||
|
"denoising_strength": params['denoising_strength'],
|
||||||
|
"steps": params['steps'],
|
||||||
|
"cfg_scale": params['cfg_scale'],
|
||||||
|
"width": params['width'],
|
||||||
|
"height": params['height'],
|
||||||
|
"restore_faces": params['restore_faces'],
|
||||||
|
"override_settings_restore_afterwards": True,
|
||||||
|
"negative_prompt": params['negative_prompt']
|
||||||
|
}
|
||||||
|
|
||||||
|
print(f'Prompting the image generator via the API on {params["address"]}...')
|
||||||
|
response = requests.post(url=f'{params["address"]}/sdapi/v1/txt2img', json=payload)
|
||||||
|
response.raise_for_status()
|
||||||
|
r = response.json()
|
||||||
|
|
||||||
|
visible_result = ""
|
||||||
|
for img_str in r['images']:
|
||||||
|
if params['save_img']:
|
||||||
|
img_data = base64.b64decode(img_str)
|
||||||
|
|
||||||
|
variadic = f'{date.today().strftime("%Y_%m_%d")}/{character}_{int(time.time())}'
|
||||||
|
output_file = Path(f'extensions/sd_api_pictures/outputs/{variadic}.png')
|
||||||
|
output_file.parent.mkdir(parents=True, exist_ok=True)
|
||||||
|
|
||||||
|
with open(output_file.as_posix(), 'wb') as f:
|
||||||
|
f.write(img_data)
|
||||||
|
|
||||||
|
visible_result = visible_result + f'<img src="/file/extensions/sd_api_pictures/outputs/{variadic}.png" alt="{description}" style="max-width: unset; max-height: unset;">\n'
|
||||||
|
else:
|
||||||
|
image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
|
||||||
|
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
||||||
|
image.thumbnail((300, 300))
|
||||||
|
buffered = io.BytesIO()
|
||||||
|
image.save(buffered, format="JPEG")
|
||||||
|
buffered.seek(0)
|
||||||
|
image_bytes = buffered.getvalue()
|
||||||
|
img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
|
||||||
|
visible_result = visible_result + f'<img src="{img_str}" alt="{description}">\n'
|
||||||
|
|
||||||
|
if params['manage_VRAM']:
|
||||||
|
give_VRAM_priority('LLM')
|
||||||
|
|
||||||
|
return visible_result
|
||||||
|
|
||||||
|
# TODO: how do I make the UI history ignore the resulting pictures (I don't want HTML to appear in history)
|
||||||
|
# and replace it with 'text' for the purposes of logging?
|
||||||
|
def output_modifier(string, state):
|
||||||
|
"""
|
||||||
|
This function is applied to the model outputs.
|
||||||
|
"""
|
||||||
|
|
||||||
|
global picture_response, params
|
||||||
|
|
||||||
|
if not picture_response:
|
||||||
|
return string
|
||||||
|
|
||||||
|
string = remove_surrounded_chars(string)
|
||||||
|
string = string.replace('"', '')
|
||||||
|
string = string.replace('“', '')
|
||||||
|
string = string.replace('\n', ' ')
|
||||||
|
string = string.strip()
|
||||||
|
|
||||||
|
if string == '':
|
||||||
|
string = 'no viable description in reply, try regenerating'
|
||||||
|
return string
|
||||||
|
|
||||||
|
text = ""
|
||||||
|
if (params['mode'] < 2):
|
||||||
|
toggle_generation(False)
|
||||||
|
text = f'*Sends a picture which portrays: “{string}”*'
|
||||||
|
else:
|
||||||
|
text = string
|
||||||
|
|
||||||
|
string = get_SD_pictures(string, state['character_menu']) + "\n" + text
|
||||||
|
|
||||||
|
return string
|
||||||
|
|
||||||
|
|
||||||
|
def bot_prefix_modifier(string):
|
||||||
|
"""
|
||||||
|
This function is only applied in chat mode. It modifies
|
||||||
|
the prefix text for the Bot and can be used to bias its
|
||||||
|
behavior.
|
||||||
|
"""
|
||||||
|
|
||||||
|
return string
|
||||||
|
|
||||||
|
|
||||||
|
def toggle_generation(*args):
|
||||||
|
global picture_response, shared
|
||||||
|
|
||||||
|
if not args:
|
||||||
|
picture_response = not picture_response
|
||||||
|
else:
|
||||||
|
picture_response = args[0]
|
||||||
|
|
||||||
|
shared.processing_message = "*Is sending a picture...*" if picture_response else "*Is typing...*"
|
||||||
|
|
||||||
|
|
||||||
|
def filter_address(address):
|
||||||
|
address = address.strip()
|
||||||
|
# address = re.sub('http(s)?:\/\/|\/$','',address) # remove starting http:// OR https:// OR trailing slash
|
||||||
|
address = re.sub('\/$', '', address) # remove trailing /s
|
||||||
|
if not address.startswith('http'):
|
||||||
|
address = 'http://' + address
|
||||||
|
return address
|
||||||
|
|
||||||
|
|
||||||
|
def SD_api_address_update(address):
|
||||||
|
global params
|
||||||
|
|
||||||
|
msg = "✔️ SD API is found on:"
|
||||||
|
address = filter_address(address)
|
||||||
|
params.update({"address": address})
|
||||||
|
try:
|
||||||
|
response = requests.get(url=f'{params["address"]}/sdapi/v1/sd-models')
|
||||||
|
response.raise_for_status()
|
||||||
|
# r = response.json()
|
||||||
|
except:
|
||||||
|
msg = "❌ No SD API endpoint on:"
|
||||||
|
|
||||||
|
return gr.Textbox.update(label=msg)
|
||||||
|
|
||||||
|
|
||||||
|
def custom_css():
|
||||||
|
path_to_css = Path(__file__).parent.resolve() / 'style.css'
|
||||||
|
return open(path_to_css, 'r').read()
|
||||||
|
|
||||||
|
|
||||||
|
def get_checkpoints():
|
||||||
|
global params
|
||||||
|
|
||||||
|
try:
|
||||||
|
models = requests.get(url=f'{params["address"]}/sdapi/v1/sd-models')
|
||||||
|
options = requests.get(url=f'{params["address"]}/sdapi/v1/options')
|
||||||
|
options_json = options.json()
|
||||||
|
params['sd_checkpoint'] = options_json['sd_model_checkpoint']
|
||||||
|
params['checkpoint_list'] = [result["title"] for result in models.json()]
|
||||||
|
except:
|
||||||
|
params['sd_checkpoint'] = ""
|
||||||
|
params['checkpoint_list'] = []
|
||||||
|
|
||||||
|
return gr.update(choices=params['checkpoint_list'], value=params['sd_checkpoint'])
|
||||||
|
|
||||||
|
|
||||||
|
def load_checkpoint(checkpoint):
|
||||||
|
payload = {
|
||||||
|
"sd_model_checkpoint": checkpoint
|
||||||
|
}
|
||||||
|
|
||||||
|
try:
|
||||||
|
requests.post(url=f'{params["address"]}/sdapi/v1/options', json=payload)
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
def get_samplers():
|
||||||
|
try:
|
||||||
|
response = requests.get(url=f'{params["address"]}/sdapi/v1/samplers')
|
||||||
|
response.raise_for_status()
|
||||||
|
samplers = [x["name"] for x in response.json()]
|
||||||
|
except:
|
||||||
|
samplers = []
|
||||||
|
|
||||||
|
return samplers
|
||||||
|
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
|
||||||
|
# Gradio elements
|
||||||
|
# gr.Markdown('### Stable Diffusion API Pictures') # Currently the name of extension is shown as the title
|
||||||
|
with gr.Accordion("Parameters", open=True, elem_classes="SDAP"):
|
||||||
|
with gr.Row():
|
||||||
|
address = gr.Textbox(placeholder=params['address'], value=params['address'], label='Auto1111\'s WebUI address')
|
||||||
|
modes_list = ["Manual", "Immersive/Interactive", "Picturebook/Adventure"]
|
||||||
|
mode = gr.Dropdown(modes_list, value=modes_list[params['mode']], label="Mode of operation", type="index")
|
||||||
|
with gr.Column(scale=1, min_width=300):
|
||||||
|
manage_VRAM = gr.Checkbox(value=params['manage_VRAM'], label='Manage VRAM')
|
||||||
|
save_img = gr.Checkbox(value=params['save_img'], label='Keep original images and use them in chat')
|
||||||
|
|
||||||
|
force_pic = gr.Button("Force the picture response")
|
||||||
|
suppr_pic = gr.Button("Suppress the picture response")
|
||||||
|
with gr.Row():
|
||||||
|
checkpoint = gr.Dropdown(params['checkpoint_list'], value=params['sd_checkpoint'], label="Checkpoint", type="value")
|
||||||
|
update_checkpoints = gr.Button("Get list of checkpoints")
|
||||||
|
|
||||||
|
with gr.Accordion("Generation parameters", open=False):
|
||||||
|
prompt_prefix = gr.Textbox(placeholder=params['prompt_prefix'], value=params['prompt_prefix'], label='Prompt Prefix (best used to describe the look of the character)')
|
||||||
|
textgen_prefix = gr.Textbox(placeholder=params['textgen_prefix'], value=params['textgen_prefix'], label='textgen prefix (type [subject] where the subject should be placed)')
|
||||||
|
negative_prompt = gr.Textbox(placeholder=params['negative_prompt'], value=params['negative_prompt'], label='Negative Prompt')
|
||||||
|
with gr.Row():
|
||||||
|
with gr.Column():
|
||||||
|
width = gr.Slider(64, 2048, value=params['width'], step=64, label='Width')
|
||||||
|
height = gr.Slider(64, 2048, value=params['height'], step=64, label='Height')
|
||||||
|
with gr.Column(variant="compact", elem_id="sampler_col"):
|
||||||
|
with gr.Row(elem_id="sampler_row"):
|
||||||
|
sampler_name = gr.Dropdown(value=params['sampler_name'], allow_custom_value=True, label='Sampling method', elem_id="sampler_box")
|
||||||
|
create_refresh_button(sampler_name, lambda: None, lambda: {'choices': get_samplers()}, 'refresh-button')
|
||||||
|
steps = gr.Slider(1, 150, value=params['steps'], step=1, label="Sampling steps", elem_id="steps_box")
|
||||||
|
with gr.Row():
|
||||||
|
seed = gr.Number(label="Seed", value=params['seed'], elem_id="seed_box")
|
||||||
|
cfg_scale = gr.Number(label="CFG Scale", value=params['cfg_scale'], elem_id="cfg_box")
|
||||||
|
with gr.Column() as hr_options:
|
||||||
|
restore_faces = gr.Checkbox(value=params['restore_faces'], label='Restore faces')
|
||||||
|
enable_hr = gr.Checkbox(value=params['enable_hr'], label='Hires. fix')
|
||||||
|
with gr.Row(visible=params['enable_hr'], elem_classes="hires_opts") as hr_options:
|
||||||
|
hr_scale = gr.Slider(1, 4, value=params['hr_scale'], step=0.1, label='Upscale by')
|
||||||
|
denoising_strength = gr.Slider(0, 1, value=params['denoising_strength'], step=0.01, label='Denoising strength')
|
||||||
|
hr_upscaler = gr.Textbox(placeholder=params['hr_upscaler'], value=params['hr_upscaler'], label='Upscaler')
|
||||||
|
|
||||||
|
# Event functions to update the parameters in the backend
|
||||||
|
address.change(lambda x: params.update({"address": filter_address(x)}), address, None)
|
||||||
|
mode.select(lambda x: params.update({"mode": x}), mode, None)
|
||||||
|
mode.select(lambda x: toggle_generation(x > 1), inputs=mode, outputs=None)
|
||||||
|
manage_VRAM.change(lambda x: params.update({"manage_VRAM": x}), manage_VRAM, None)
|
||||||
|
manage_VRAM.change(lambda x: give_VRAM_priority('set' if x else 'reset'), inputs=manage_VRAM, outputs=None)
|
||||||
|
save_img.change(lambda x: params.update({"save_img": x}), save_img, None)
|
||||||
|
|
||||||
|
address.submit(fn=SD_api_address_update, inputs=address, outputs=address)
|
||||||
|
prompt_prefix.change(lambda x: params.update({"prompt_prefix": x}), prompt_prefix, None)
|
||||||
|
textgen_prefix.change(lambda x: params.update({"textgen_prefix": x}), textgen_prefix, None)
|
||||||
|
negative_prompt.change(lambda x: params.update({"negative_prompt": x}), negative_prompt, None)
|
||||||
|
width.change(lambda x: params.update({"width": x}), width, None)
|
||||||
|
height.change(lambda x: params.update({"height": x}), height, None)
|
||||||
|
hr_scale.change(lambda x: params.update({"hr_scale": x}), hr_scale, None)
|
||||||
|
denoising_strength.change(lambda x: params.update({"denoising_strength": x}), denoising_strength, None)
|
||||||
|
restore_faces.change(lambda x: params.update({"restore_faces": x}), restore_faces, None)
|
||||||
|
hr_upscaler.change(lambda x: params.update({"hr_upscaler": x}), hr_upscaler, None)
|
||||||
|
enable_hr.change(lambda x: params.update({"enable_hr": x}), enable_hr, None)
|
||||||
|
enable_hr.change(lambda x: hr_options.update(visible=params["enable_hr"]), enable_hr, hr_options)
|
||||||
|
update_checkpoints.click(get_checkpoints, None, checkpoint)
|
||||||
|
checkpoint.change(lambda x: params.update({"sd_checkpoint": x}), checkpoint, None)
|
||||||
|
checkpoint.change(load_checkpoint, checkpoint, None)
|
||||||
|
|
||||||
|
sampler_name.change(lambda x: params.update({"sampler_name": x}), sampler_name, None)
|
||||||
|
steps.change(lambda x: params.update({"steps": x}), steps, None)
|
||||||
|
seed.change(lambda x: params.update({"seed": x}), seed, None)
|
||||||
|
cfg_scale.change(lambda x: params.update({"cfg_scale": x}), cfg_scale, None)
|
||||||
|
|
||||||
|
force_pic.click(lambda x: toggle_generation(True), inputs=force_pic, outputs=None)
|
||||||
|
suppr_pic.click(lambda x: toggle_generation(False), inputs=suppr_pic, outputs=None)
|
||||||
@ -0,0 +1,52 @@
|
|||||||
|
/* Align the elements for SD_api_picture extension */
|
||||||
|
.SDAP #sampler_box {
|
||||||
|
padding-top: var(--spacing-sm);
|
||||||
|
padding-bottom: var(--spacing-sm);
|
||||||
|
border: 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
.SDAP #steps_box {
|
||||||
|
border-radius: 0 0 var(--block-radius) var(--block-radius);
|
||||||
|
}
|
||||||
|
|
||||||
|
.SDAP #sampler_col {
|
||||||
|
gap: 0;
|
||||||
|
padding: 0;
|
||||||
|
background-color: transparent;
|
||||||
|
}
|
||||||
|
|
||||||
|
.SDAP #sampler_row {
|
||||||
|
border-bottom: 0;
|
||||||
|
box-shadow: var(--block-shadow);
|
||||||
|
border-width: var(--block-border-width);
|
||||||
|
border-color: var(--block-border-color);
|
||||||
|
border-radius: var(--block-radius) var(--block-radius) 0 0;
|
||||||
|
background: var(--block-background-fill);
|
||||||
|
gap: 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
.SDAP #sampler_row .refresh-button {
|
||||||
|
margin-bottom: var(--spacing-sm);
|
||||||
|
margin-right: var(--spacing-lg);
|
||||||
|
}
|
||||||
|
|
||||||
|
.SDAP #seed_box,
|
||||||
|
.SDAP #cfg_box {
|
||||||
|
padding-top: var(--spacing-md);
|
||||||
|
}
|
||||||
|
|
||||||
|
.SDAP #sampler_box span,
|
||||||
|
.SDAP #seed_box span,
|
||||||
|
.SDAP #cfg_box span,
|
||||||
|
.SDAP #steps_box span {
|
||||||
|
margin-bottom: var(--spacing-sm);
|
||||||
|
}
|
||||||
|
|
||||||
|
.SDAP svg.dropdown-arrow {
|
||||||
|
flex-shrink: 0 !important;
|
||||||
|
margin: 0px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.SDAP .hires_opts input[type="number"] {
|
||||||
|
width: 6em !important;
|
||||||
|
}
|
||||||
@ -0,0 +1,58 @@
|
|||||||
|
import base64
|
||||||
|
from io import BytesIO
|
||||||
|
|
||||||
|
import gradio as gr
|
||||||
|
import torch
|
||||||
|
from transformers import BlipForConditionalGeneration, BlipProcessor
|
||||||
|
|
||||||
|
from modules import chat, shared, ui_chat
|
||||||
|
from modules.ui import gather_interface_values
|
||||||
|
from modules.utils import gradio
|
||||||
|
|
||||||
|
input_hijack = {
|
||||||
|
'state': False,
|
||||||
|
'value': ["", ""]
|
||||||
|
}
|
||||||
|
|
||||||
|
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
|
||||||
|
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base", torch_dtype=torch.float32).to("cpu")
|
||||||
|
|
||||||
|
|
||||||
|
def chat_input_modifier(text, visible_text, state):
|
||||||
|
global input_hijack
|
||||||
|
if input_hijack['state']:
|
||||||
|
input_hijack['state'] = False
|
||||||
|
return input_hijack['value']
|
||||||
|
else:
|
||||||
|
return text, visible_text
|
||||||
|
|
||||||
|
|
||||||
|
def caption_image(raw_image):
|
||||||
|
inputs = processor(raw_image.convert('RGB'), return_tensors="pt").to("cpu", torch.float32)
|
||||||
|
out = model.generate(**inputs, max_new_tokens=100)
|
||||||
|
return processor.decode(out[0], skip_special_tokens=True)
|
||||||
|
|
||||||
|
|
||||||
|
def generate_chat_picture(picture, name1, name2):
|
||||||
|
text = f'*{name1} sends {name2} a picture that contains the following: “{caption_image(picture)}”*'
|
||||||
|
# lower the resolution of sent images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
||||||
|
picture.thumbnail((300, 300))
|
||||||
|
buffer = BytesIO()
|
||||||
|
picture.save(buffer, format="JPEG")
|
||||||
|
img_str = base64.b64encode(buffer.getvalue()).decode('utf-8')
|
||||||
|
visible_text = f'<img src="data:image/jpeg;base64,{img_str}" alt="{text}">'
|
||||||
|
return text, visible_text
|
||||||
|
|
||||||
|
|
||||||
|
def ui():
|
||||||
|
picture_select = gr.Image(label='Send a picture', type='pil')
|
||||||
|
|
||||||
|
# Prepare the input hijack, update the interface values, call the generation function, and clear the picture
|
||||||
|
picture_select.upload(
|
||||||
|
lambda picture, name1, name2: input_hijack.update({
|
||||||
|
"state": True,
|
||||||
|
"value": generate_chat_picture(picture, name1, name2)
|
||||||
|
}), [picture_select, shared.gradio['name1'], shared.gradio['name2']], None).then(
|
||||||
|
gather_interface_values, gradio(shared.input_elements), gradio('interface_state')).then(
|
||||||
|
chat.generate_chat_reply_wrapper, gradio(ui_chat.inputs), gradio('display', 'history'), show_progress=False).then(
|
||||||
|
lambda: None, None, picture_select, show_progress=False)
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in new issue